

最近碰到一个mysql服务器操作系统内核有关的问题,作为dba,不光要具备数据库方面的知识,还需要了解运行环境下的排查的一些方式和手段。
环境:
高配物理服务器,mysql日常运行并发也在20以内。但发现cpu的sys使用比较高,并发上升的时候sys值不断上升,最后导致qps,tps下降。严重的时候存在穷住情况发生。
需要先了解cpu的sys是什么?什么情况下mysql会影响cpu? 按照这个思路进行排查。
- %sy(sys)
表示cpu 在内核态运行的时间百分比(不包括中断),就是说系统进程消耗cpu 时间,通常内核态 cpu 越低越好,否则表示系统存在某些瓶颈。比如:i/o频繁操作,网络包大量传输,core输出 等情况下。 - mysql对于cpu的影响:
并发太高,连接数满很多线程需要等待,mysql参数控制并发度,大事务 等。
指标分析
1.监控sys cpu情况: 日常维持在10%~20%,最高能到到50%
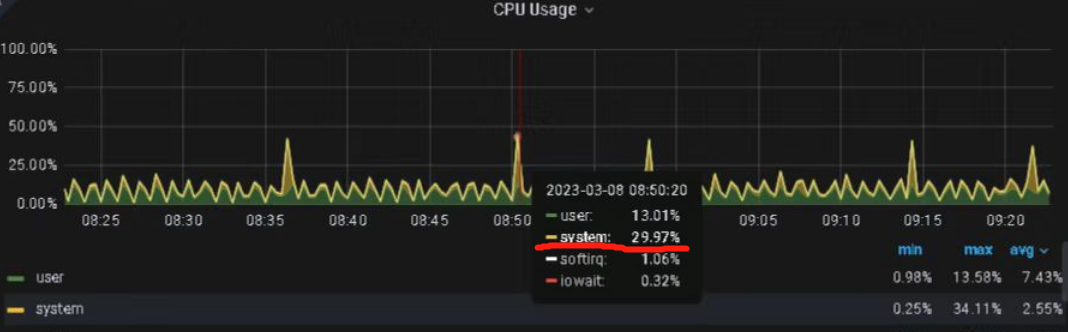
2.监控io等待情况: 20%的util
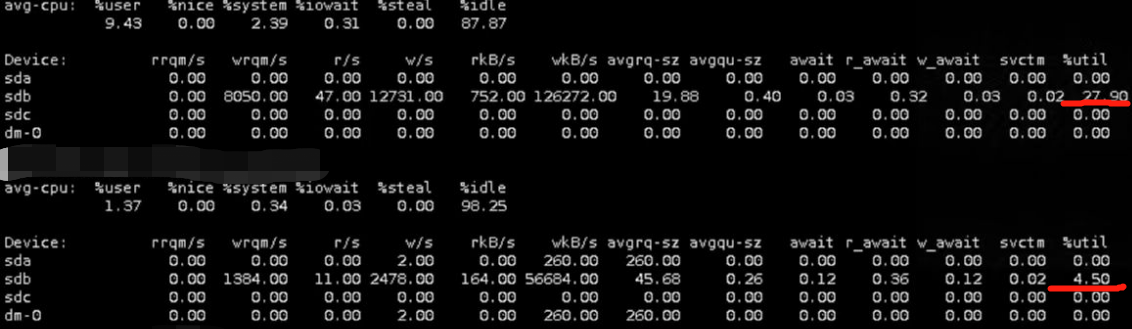
3.mysql运行情况当时运行并发数: 3个线程并行运行
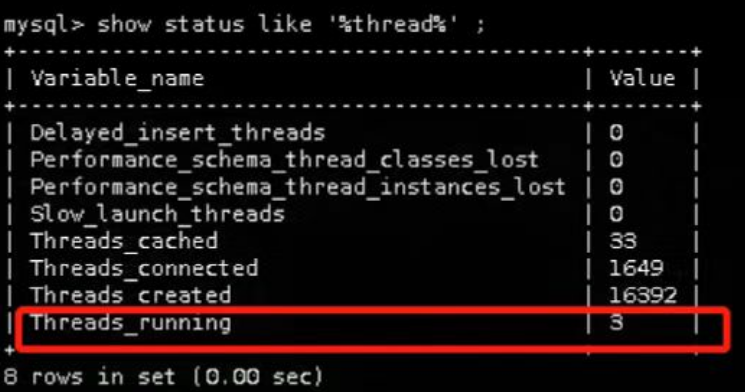
5.mysql限制并发: 无限制

6.错误日志,系统日志: 无异常信息
从上面整个mysql的运行情况来说,比较耐人寻味。因为除了反馈sys高,其他指标属于正常范围。
7.使用perf top 和 sar 分析

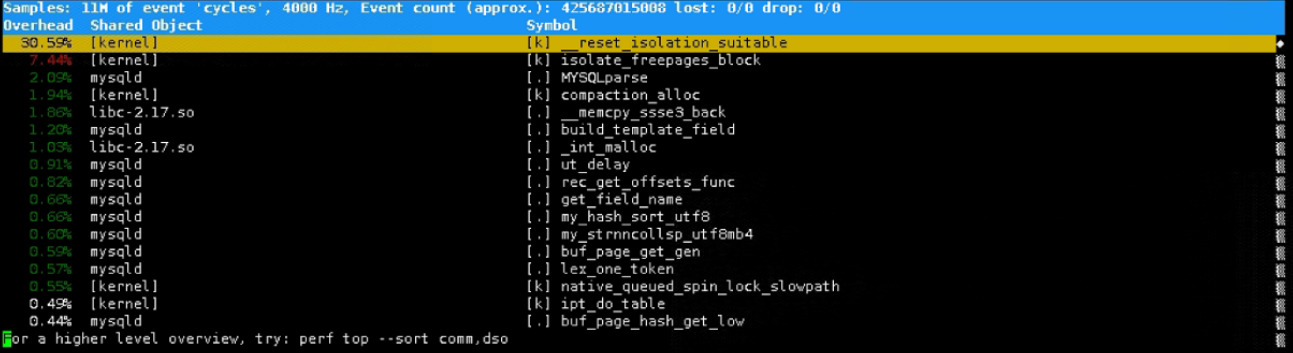
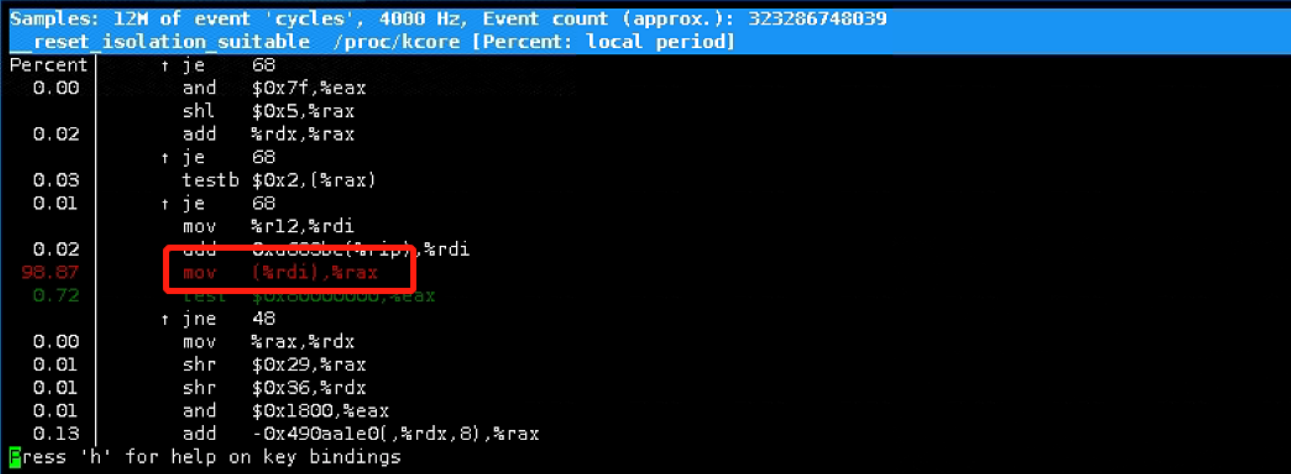
发现sys cpu利用率到达79%时,后台运行_reset_isolation_suitable 突然达到98%
- mov rdi,rax说明:
将rax寄存器的的数据传送到rdi寄存器,但是rax寄存器的数据本身不破坏 - reset_isolation_suitable:
内存碎片管理
搜索相关知识点,大部分都指向内核内存管理有关系。基本肯定是内存的碎片管理导致sys高。
原理分析
1.知识点
cpu指中央处理器,中央处理器的功效主要为处理指令、执行操作、控制时间、处理数据。cpu和内存之间的架构分为两种:
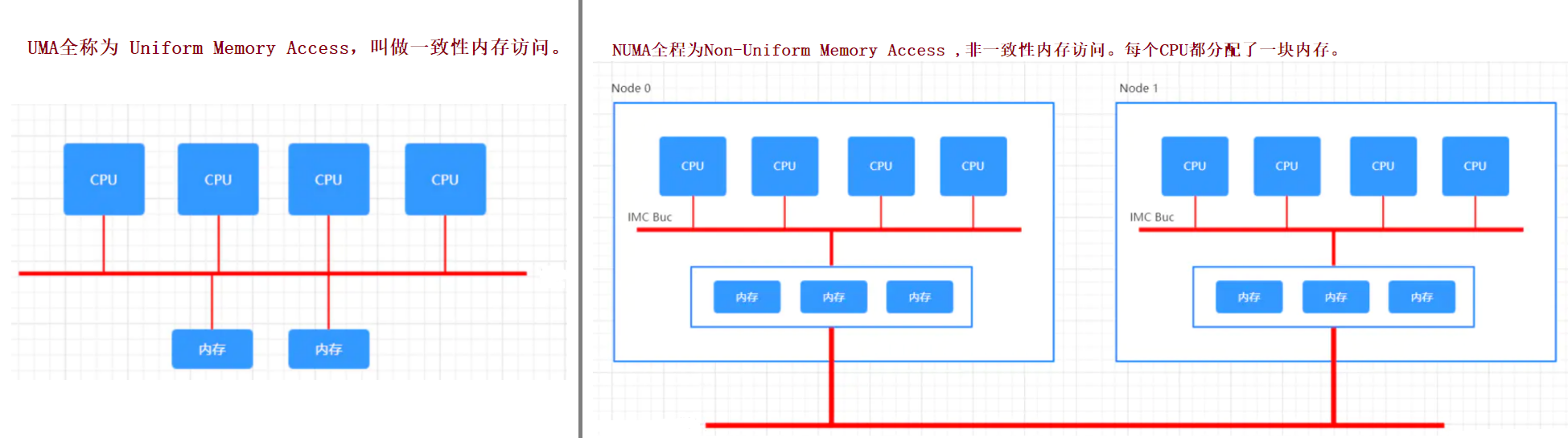
- 内存架构
物理内存由node,zone,page三级结构来构成。
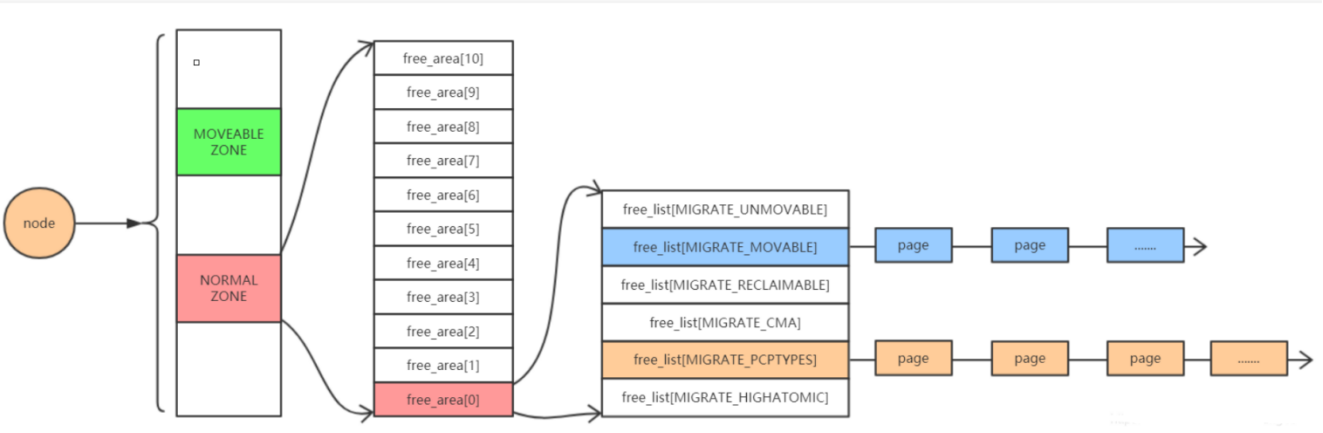
- zone_normal: 正常使用的物理内存区域,大部分申请的内存都使用的是该区域
- zone_highmem: 只会出现在32位系统内,这时由于在32位系统中,物理内存最多能够直接映射到内核中896m内存
- zone_movable: 可移动或回收区域,所管理的物理内存来自于zone_normal或者zone_highmem,主要是防止内存碎片和支持热插拔功能,内核将zone_normal或者zone_highmem中根据配置划分出一片物理内存为zone_movable。
zone_movable区两个重要作用:
- 可以有效防止内存碎片化。
- 支持内存热插拔,尤其是在虚拟化场景,当不需要那么多物理内存时可以释放处理给系统其他程序使用,当需要申请新的物理内存时重新进程插入。
系统内核果然是一个又有趣又神秘的领域。
定位分析
了解了内存的一些基础理论,那怎样查看内存碎片情况。
linux内核提供了 pagetypeinfo,slabinfo,buddyinfo 等方面提供分析
查看buddyinfo分析系统内存碎片
shell> cat /proc/buddyinfo | awk -v ps="`getconf pagesize`" -v date="`date`" -v host="`hostname`" \
'begin{printf("\nfragmentation report\nlow is order 1-4, high is order 5-9, normal is order 10-11\n%s\t%s\n\n",host,date)} {\
l= ps * ( ($5 * 1) ($6 * 2) ($7 * 4) ($8 * 8) ); \
h= ps * ( ($9 * 16) ($10 * 32) ($11 * 64) ($12 * 128) ($13 * 256) ); \
n= ps * ( ($14 * 512) ($15 * 1024) ); \
t=l h n; \
printf("%s\ttotal: �m\tlow: .2f%%\thigh: .2f%%\tnormal: .2f%%\n",\
$1" "$2" "$3" "$4,t/1024/1024,(l/t)*100,(h/t)*100,(n/t)*100);}'
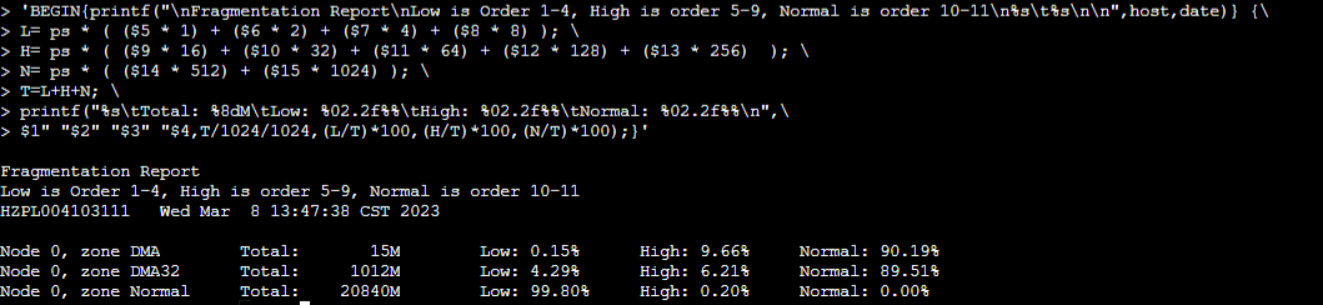
- normal: 正常使用的物理内存区域,大部分申请的内存都使用的是该区域
- low:低水位,代表内存已经开始吃紧,需要启动回收页内核线性kswapped去回收内存
- high:高水位,代表内存还是足够的。
cat /proc/zoneinfo
node 0, zone dma
per-node stats
nr_inactive_anon 448
nr_active_anon 171214
nr_inactive_file 121291
nr_active_file 95855
nr_unevictable 0
nr_slab_reclaimable 13073
。。。
pages free 2166
min 94
low 117
high 140
spanned 4095
present 3998
managed 3840
protection: (0, 1781, 1781, 1781, 1781)
nr_free_pages 2166
。。。
- page_low: 当空闲页面的数量达到page_low所标定的数量的时候,kswapd线程将被唤醒,并开始释放回收页面。这个值默认是page_min的2倍。
- page_min: 当空闲页面的数量达到page_min所标定的数量的时候, 分配页面的动作和kswapd线程同步运行
- page_high: 当空闲页面的数量达到page_high所标定的数量的时候, kswapd线程将重新休眠,通常这个数值是page_min的3倍。
内核更改
sysctl被用于在内核运行时动态地修改内核的运行参数,可用的内核参数在目录/proc/sys中。它包含一些tcp/ip堆栈和虚拟内存系统的高级选项,合理配置并提高系统性能。
sysctl -a | grep "vm\."
[root@schouse kevindba]# sysctl -a | grep "vm\."
。。。
vm.drop_caches = 0
vm.extfrag_threshold = 500
vm.min_free_kbytes = 45056
vm.watermark_scale_factor = 10
。。。
1. 内存压缩
extfrag_threshold:当向系统申请一大段连续内存时,如果找不到符合条件的连续页, 于是触发了memory compaction。这个参数用来控制出现memory compaction的概率。它是一个0 ~ 1000的整数. 如果出现内存不够用的情况, linux会为当前系统的内存碎片情况打一个分, 如果超过了extfrag_threshold这个值, kswapd将触发内存压缩。
- 这个值接近1000, 说明系统在内存碎片的处理倾向于把旧的页换出, 以符合申请的需要;
- 而接近0, 表示系统在内存碎片的处理倾向于做memory compaction.
更改extfrag_threshold内核参数避免内存碎片。
sysctl -w vm.extfrag_threshold = 1000
2.调整min水位线
多数情况下建议将min水位线设置为总内存的1%~3%。推荐设置为总内存的2%,当内存资源紧张时,提前进入异步回收。
sysctl -w vm.min_free_kbytes = memtotal_kbytes * 2%
其中,变量memtotal_kbytes * 2%表示当前实例内总内存的2%对应的内存大小。
3.调整min水位线和low水位线之间的差值
可以通过内核的watermark_scale_factor调整min水位线和low水位线之间的差值,以应对业务突发申请内存的情况。watermark_scale_factor的默认值为总内存的0.1%,最小值(即min水位线和low水位线之间的最小差值)为0.5*min水位线。
sysctl -w vm.watermark_scale_factor = value
其中,变量value为手动设置的min水位线和low水位线之间的差值。
定期整理
定期重新启动 服务和服务器 或 定期进行整理操作
1.定期进行内存规整
可以在业务空闲时段,主动触发异步内存规整。
echo 1 > /proc/sys/vm/compact_memory
2.定期手动释放缓存
清理内存cache,以上措施均不能有效应对内存碎片化时,还可以在业务空闲时段执行释放缓存(drop cache)的操作,然后内存会重新分配。释放缓存是避免内存碎片化的有效措施,但在执行释放缓存时会出现短时间的系统性能抖动(这个方案不可取,只能应急)。
echo 3 > /proc/sys/vm/drop_caches
升级
除此之外也可以进行操作系统重新安装,内核升级,软件升级的操作。因为这些方面在不停的迭代更新中。但无法保证问题不重现。但确实比较少见场景。
从上诉中问题分析的整个思路和过程中,dba不光需要数据库方面的知识,还需要了解一些运行环境的浅度内核知识。
对于内存碎片问题,结合实际情况选择合理的方案即可。