table of contents
概述
primary database主库
处于open状态对外提供服务,用户在primary database 上进行操作,操作被记录在联机日志和归
档日志中。
需要设置 logging force 模式:
即使在归档模式下,也可能会有一些有nologging的操作不产生redo,这在dg下是不允许的,因此
必须启用数据库强制记录redo。
standby database备库
处于恢复状态,接收并应用主库传递过来的日志。
概述
dg的运行遵循一个很简单的原则:主库将redo日志传给备库,备库接受后验证并应用redo日志
-
dg只传输恢复数据库事务所需的redo日志,以便同步备库和对应的主库
- redo由redo entries组成,一个redo entry由一组变更向量构成,每个向量描述数据库中的一个数据块的变更
- redo entry : redo entry包含重新生成数据库更改所需的所有信息,例如雇员表中的薪水值
- 变更向量:撤销段数据块的变化、撤销段的事务表的变化以及表的数据段块的变化
-
dg会在备库应用redo日志之前执行oracle验证,以免扩散主库中的受损的数据
-
如果网络中断或者备库断电导致主备库的连接临时中断,dg会自动使用在主库上已经归档的redo日志重新同步备库
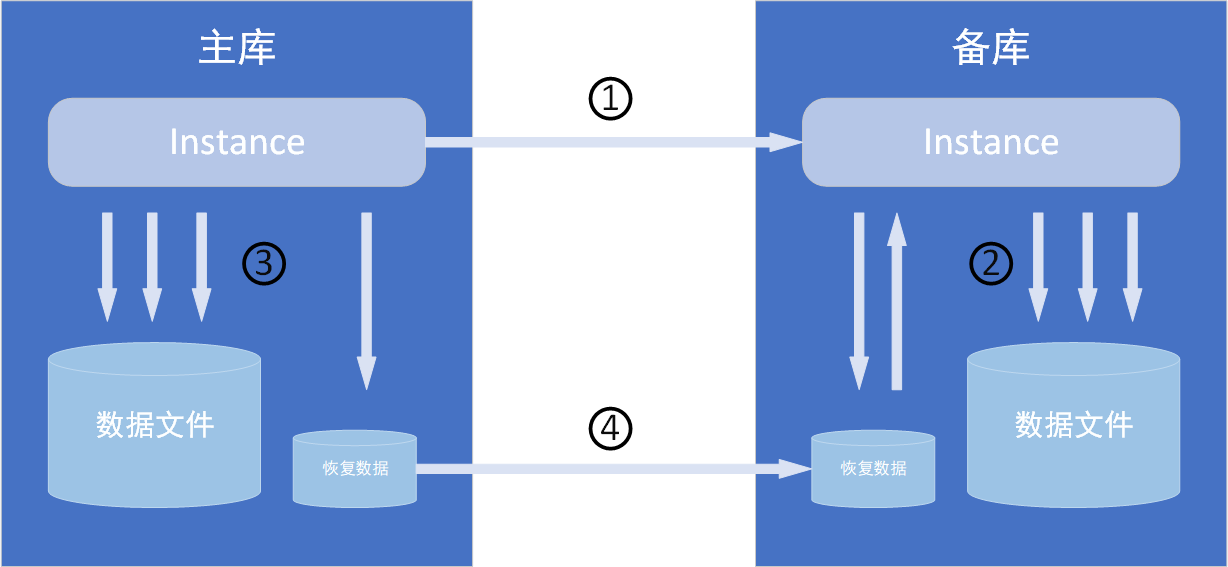
① 生成redo时,redo传输服务将redo日志从主库传到备库
② 应用服务验证redo日志并更新备库数据库文件
③ 独立于dg,dbwn进程更新数据库文件
④ 在网络中断或备库停运后,dg使用已在主库上归档的redo日志,自动重新同步备库
传输方式
redo transport service
redo transport service主要协调从主库到备库的redo传输过程
主要传输过程:
- 主库的lgwr进程将redo从sga的redo log buffer中写入到online redo log中
- 主库的lns(log network service)进程从sga的redo log buffer中读取数据,并交由oracle net服务传输到备库的rfs进程
- 备库的rfs(remote file server)进程接受lns传输的redo日志,然后将其写入standby redo log文件的顺序文件中
同步传输sync
同步传输(synchronous transport, sync)又称为“零数据损失”,使用同步传输可以使主库与备库随时处于同步状态,传输过程中主库要等到事务恢复所需的redo已被写入备库的磁盘里,才允许lgwr认可提交操作成功,具体的传输过程如下:
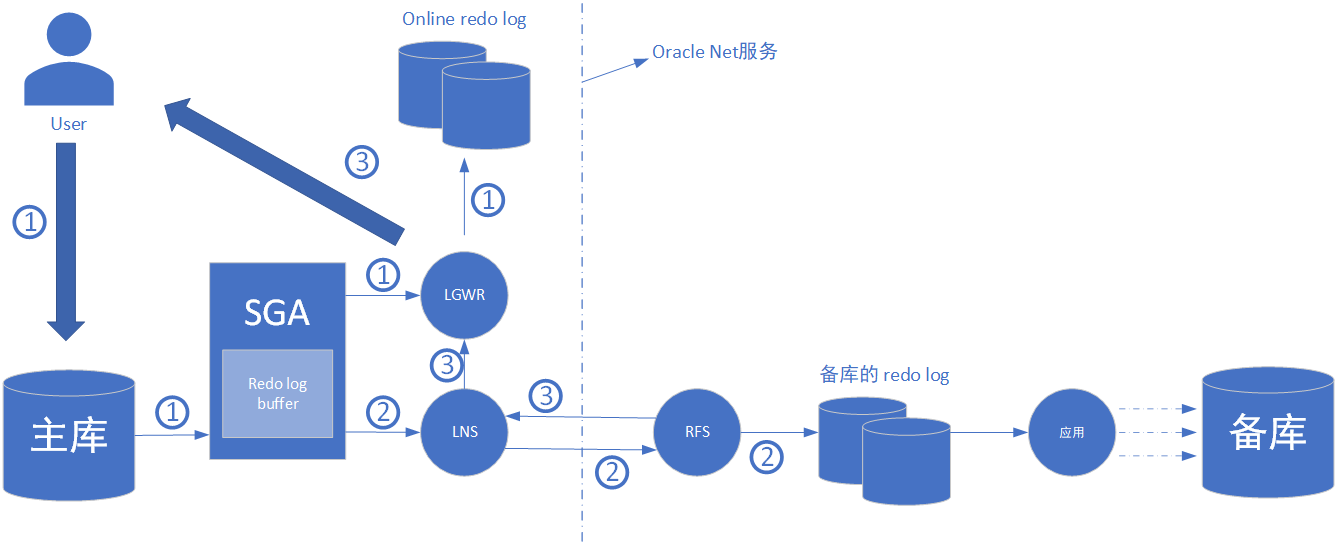
① 用户提交事务,事务再sga中创建一个redo entry。lgwr从redo log buffer中读取redo entry,写入online redo log,并等待lns的确认
② lns从redo log buffer中读取相同的redo entry,通过oracle net服务传给备库。备库上的rfs接受redo,然后将其写入备库的redo log中
③ 备库的rfs从磁盘接受到写完的消息,会传回一个确认消息给主库的lns,lns接着通知lgwr传输完成。lgwr向用户发送确认信息
同步传输的不足:
sync可以确保得到数据库提交确认的每个事务都得到保护,但这种方式会对主库的性能造成影响。主要的原因就是:lgwr只有等到数据已在备库受到保护的确认消息后,才能才是继续处理下一个事务
redo log的大小、可用的网络宽带、往返网络延迟(rtt)以及备库写入standby redo log的i/o性能都会对应用程序响应速度和数据库吞吐量。所以网络rtt随着距离的延长而增加,主库的性能也就会受到影响,实际上则会对主库与备库之间的距离形成限制
异步传输async
异步传输(asynchronous transport, async)与sync的最大的不同就在于lgwr不用等待来自lns的确认消息,无论主备库之间相距多远,都可以做到几乎不影响主库的性能
即使由于宽带有限,使得redo不能立即传给备库,lgwr也将继续确认提交操作成功完成。如果lns赶不上lgwr的提交进度,主库在lns将redo传给备库前就回收了redo log buffer,lns将自行转为从online redo log 读取和发送redo;当lgwr赶上进度后,将自行转回直接从redo log buffer中读取发送
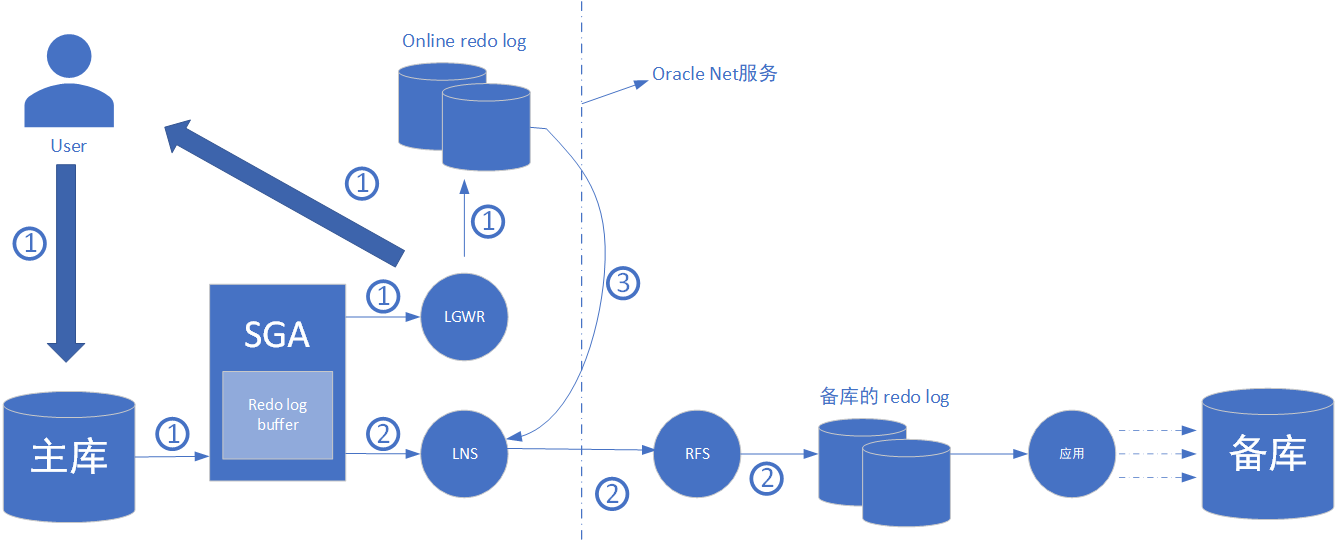
① 用户提交事务,事务再sga中创建一个redo entry。lgwr从redo log buffer中读取redo entry,写入online redo log,并向用户发送确认信息
② lns从redo log buffer中读取相同的redo entry,通过oracle net服务传给备库。备库上的rfs接受redo,然后将其写入备库的redo log中
③ 主备库之间的日志传输出现异常等情况时,lns自动转为从online redo log读取和发送redo;恢复后自动转回从redo log buffer中读取和发送redo
异步传输的不足:
async最大的不足就在于增加了数据丢失风险。如果某个故障破坏了主库,而此时传输滞后尚未降低到0,那么传输滞后所包含的任何已提交事务都将丢失。所以在使用async时,提供足够打的网络宽带来处理峰值期间告诉产生的redo,可以最大限度地降低数据损失的风险
应用服务
dg提供了两种不同的方式在备库中应用redo:redo apply(物理备用)和sql apply(逻辑备用)
dg的宗旨是防止丢失数据,设计目标是让备库成为主库的同步副本。dg的设计纯粹的是为了实现对整个数据库的单向复制。因此,dg还嵌入了safeguard,以免在备库上对主库是上复制来的数据进行任何未授权的改动
dg的第二目标旨在高度分离主库和备库,以防主库上发生的问题影响到备库,进而危及数据的保护和可用性,这样做也可以防止备库上出现的问题影响到主库的可用性或性能
dg的第三目标是在主库出现故障时提供数据可用性和高可用性。**redo apply和sql apply都能将一个同步备库快速的转成主角色。**这样可以主库出现计划内或计划外中断后保护数据和恢复可用性
dg的最后一个目标是为备用系统、存储和软件投资提供高额回报,而不会影响“数据保护和可用性”这项重要使命。redo apply和sql apply都允许将仍担当备用角色的备库投入生产,同时不影响数据保护或实现恢复时间目标(recovery time objectives)的能力
redo apply
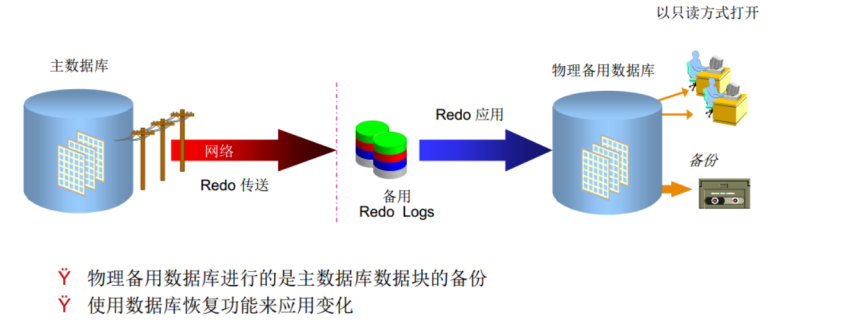
redo apply维护的备库是与主库逐块对应的精确的物理副本
当备库上的rfs进程收到从主库传来的redo,然后将其写入standby redo log时,redo apply使用戒指恢复将standby redo log中的redo entry写入内存,接着直接在备库上应用更改。
介质恢复包括一个mrp进程以及多个并行应用进程(pr0x)
mrp管理恢复会话,按照scn顺序合并来自多个实例的redo(在使用rac主实例的情形下)然后将redo解析到按应用进程划分的更改映射中。应用进程读取数据块,组装映射中的重做更改,然后将重做更改应用于数据块。redo apply将应用进程数量自动配置为比备库系统中的cpu数量少1。
oracle针对data gurad redo apply的基准测试表明,在承担oltp(联机事务处理)工作负荷时其速度高达47mb/s,在直接路径加载情形下速度高达112mb/s
redo apply可防止将主库上的物理损坏应用到备库,从而提供了卓越的保护能力。以sync或async模式直接从sga传输的redo与主站点上的组件故障造成的物理i/o损坏完全隔离
当备库使用redo apply应用redo时,将读取相应的数据块,并将scn(对应刚从主库中传过来的redo的scn,主库的scn)与redo log中的scn(保存在备库的redo log中的scn,备库的scn)进行比较,可能出现的比较结果如下:
- 主备库相同:说明主备库数据同步正常
- 主库的数据块scn小于备库的数据块scn:说明主库出现了写丢失,此时回报错ora-752,建议的响应操作是执行到物理备库的故障转移,然后重建主库
- 主库的数据块scn大于备库的数据块scn:说明备库出现了写丢失,此时回发生内部错误ora-600 3020。如有可能,需要使用受影响的数据文件在主库的备份来修复备库;否则,必须重建备库。
sql apply
sql apply(逻辑备库)使用逻辑备用进程(lsp)将更改协调应用于备库。
dg 转换日志文件中的数据为sql语句在逻辑standby上执行sql语句,因为逻辑standby是通过sql语句来实现数据同步,所以在同步期间其必须保持打开状态。
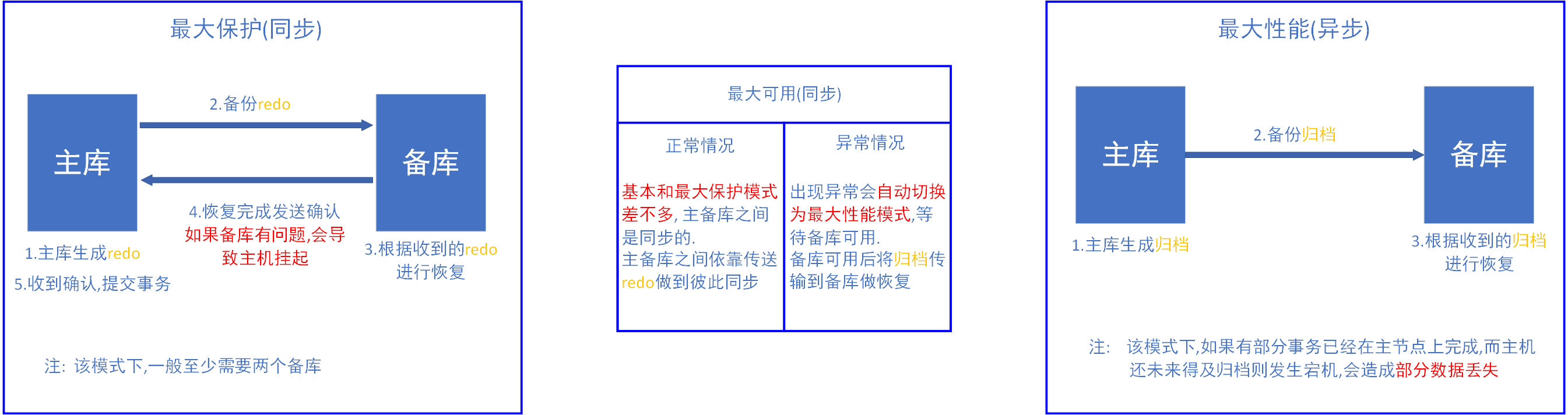
保护模式
dg的三种保护模式
dg相关的进程
log transport service
在主节点上,日志传输服务主要使用如下几个进程:
- lgwr
lgwr写联机重做日志
在同步模式下,直接将redo信息直接传送到备库中的rfs进程,主库在继续进行处理前需要等待备库的确认在非同步情况下, 直接将日志信息传递到备库的rfs进程,但是不等待备库的确认信息主库进程可以继续进行处理。 - arch
arch进程可以在归档的同时,传递日志流到备库的rfs进程,该进程还用于检测和解决备库的日志不连续问题(gap)。 - fal:(fetch archive log)
fetch archive log只有物理备库才有该进程,fal进程提供了一个client/server的机制,用来解决检测在生产库产生的连续的归档日志,而在备库接受的归档日志不连续的问题,该进程只有在需要的时候才会启动,而工作完成后就关闭,因此在正常情况下,该进程无法看到,可以设置通过lgwr,arch进程去传递日志到备库,但是不能两个进程同时传送。 - lnsn(lgwr network server process)
把日志通过网络发送给远程的目的地,每个远程目的地对应一个lns进程,多个lns进程能够并行工作。
log apply service
在备库节点上,日志应用进程主要使用如下的进程:
- rfs (remote file server)
rfs进程主要用来接受从主库传送过来的日志信息
对于物理备用数据库而言:
可以直接将日志写进备用重做日志
可以直接将日志信息写到归档日志
为了使用备库重做日志,必须创建备用重做日志,一般和主库的联机日志大小一样, 组比主库多一组 - arch
只对物理备库,arch进程归档备库重做日志,这些日志以后将被mrp进程应用到备库。 - mrp:(managed recovery process)
该进程只针对物理备库,该进程应用归档日志到备库,如果我们使用sql语句启用该进程 alterdatabase recover managed standby database , 那么前台进程将会做恢复,如果加上 disconnect 语句,那么恢复进程将在后台进行,发出该语句的进程可以继续做其他的事情实现