一、背景
最近在做数据库巡检的时候发现ash报告里有一个:os thread startup 等待事件,感觉很奇怪,在以前的巡检的报告中未发现此等待事件,避免数据库存储潜在风险。于是做了个分析。
二、事件分析

由sql_id:56h2h7wxpnntt引起的,os thread startup 和 dfs lock handle(与序列有关,整个查询未发现与序列有关,此次先不讨论)
看来与并行有关:px coordinator
三、查询资料
os thread startup 是oracle 等待事件中concurrency的一个等待,在进行并行分配是向os 申请进程启动,而在正常的系统中,该动作是非常快的,在我们高压力的数据库环境下,os存在响应问题,激发了该等待事件的等待。
mos上的一篇文档 :
solaris: database instance hangs intermittently with wait event: ‘os thread startup’ (doc id 1909881.1)
‘os thread startup’ indicates some high contention at os level avoiding even new process startup.
翻译:
solaris:数据库实例间歇性挂起,等待事件:“os thread startup”(文档id 1909881.1)
“os thread startup”表示在操作系统级别存在一些高争用,甚至避免了新进程的启动。
四、查询sql对像的并行度
- 表的并行属性:结果为空
select owner,table_name,degree from dba_tables where degree>1;
- 索引并行属性
select owner, index_name, table_name, degree
from dba_indexes
where degree > 1;
sql_id:56h2h7wxpnntt涉及表的索引的并行度为(8或16),因此表为业务大表,应该是在创建索引的时候加并行了,当时没注意。
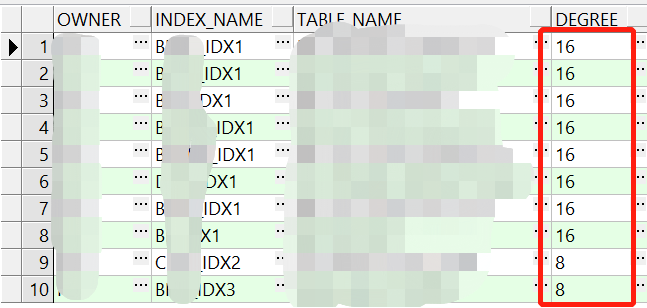
注:并行创建索引完成后,需要调整并行度,避免在使用查询时数据库开启并行,生产oltp数据库使用并行存在一定的风险 。如下:
- 重建索引开并行
sql> alter index t1_idx_id rebuild parallel 4;
index altered.
sql> select degree from all_indexes where index_name='t1_idx_id';
degree
------------
4
- 索引重建完毕后关闭并行
sql> alter index t1_idx_id noparallel;
index altered.
sql> select degree from all_indexes where index_name='t1_idx_id';
degree
------------
1
五、关闭索引并行度
select 'alter index '||owner||'.'||index_name||' noparallel;'
from dba_indexes
where degree > 1;
六、执行计划对比:
- 开并行的sql执行计划:cost:553
count(*)
----------
50997
elapsed: 00:00:04.46
----------------------------------------------------------------------------------------------------
| id | operation | name | rows | bytes | cost | time |
----------------------------------------------------------------------------------------------------
| 0 | select statement | | 1 | 100 | 553 | 00:00:07 |
| 1 | sort aggregate | | 1 | 100 | | |
| 2 | px coordinator | | | | | |
| 3 | px send qc (random) | :tq10003 | 1 | 100 | | |
| 4 | sort aggregate | | 1 | 100 | | |
| 5 | nested loops | | 43978 | 4397800 | 553 | 00:00:07 |
| 6 | nested loops outer | | 43978 | 3870064 | 549 | 00:00:07 |
| * 7 | hash join | | 43978 | 3034482 | 547 | 00:00:07 |
| 8 | buffer sort | | | | | |
| 9 | px receive | | 50551 | 1162673 | 444 | 00:00:06 |
| 10 | px send hash | :tq10001 | 50551 | 1162673 | 444 | 00:00:06 |
| * 11 | table access full | a**_***_****t | 50551 | 1162673 | 444 | 00:00:06 |
| 12 | px receive | | 43979 | 2023034 | 94 | 00:00:02 |
| 13 | px send hash | :tq10002 | 43979 | 2023034 | 94 | 00:00:02 |
| * 14 | hash join | | 43979 | 2023034 | 94 | 00:00:02 |
| 15 | buffer sort | | | | | |
| 16 | px receive | | 65 | 1040 | 4 | 00:00:01 |
| 17 | px send broadcast | :tq10000 | 65 | 1040 | 4 | 00:00:01 |
| * 18 | table access full | b**_*****t | 65 | 1040 | 4 | 00:00:01 |
| 19 | px block iterator | | 51110 | 1533300 | 81 | 00:00:01 |
| 20 | index fast full scan | b**_idx1 | 51110 | 1533300 | 81 | 00:00:01 |
| * 21 | index range scan | d***_idx1 | 1 | 19 | 0 | 00:00:01 |
| * 22 | index unique scan | pk_c***_c***_i*** | 1 | 12 | 0 | 00:00:01 |
----------------------------------------------------------------------------------------------------
statistics
----------------------------------------------------------
96 recursive calls
0 db block gets
26115 consistent gets
0 physical reads
0 redo size
528 bytes sent via sql*net to client
520 bytes received via sql*net from client
2 sql*net roundtrips to/from client
32 sorts (memory)
0 sorts (disk)
1 rows processed
- 去掉并行度后:cost:536
count(*)
----------
50997
elapsed: 00:00:00.21
------------------------------------------------------------------------------------------------
| id | operation | name | rows | bytes | cost | time |
------------------------------------------------------------------------------------------------
| 0 | select statement | | 1 | 100 | 536 | 00:00:07 |
| 1 | sort aggregate | | 1 | 100 | | |
| 2 | nested loops | | 43978 | 4397800 | 536 | 00:00:07 |
| * 3 | hash join right outer | | 43978 | 3870064 | 532 | 00:00:07 |
| 4 | index full scan | d***_idx1 | 87 | 1653 | 1 | 00:00:01 |
| * 5 | hash join | | 43978 | 3034482 | 530 | 00:00:07 |
| * 6 | table access full | a**_***_****t | 50551 | 1162673 | 444 | 00:00:06 |
| * 7 | hash join | | 43979 | 2023034 | 85 | 00:00:02 |
| 8 | view | index$_join$_003 | 65 | 1040 | 3 | 00:00:01 |
| * 9 | hash join | | | | | |
| 10 | index fast full scan | bk_p*****t_pk | 65 | 1040 | 1 | 00:00:01 |
| * 11 | index fast full scan | b***_idx1 | 65 | 1040 | 1 | 00:00:01 |
| 12 | index fast full scan | b***_idx1 | 51110 | 1533300 | 81 | 00:00:01 |
| * 13 | index unique scan | pk_c***_c***_i*** | 1 | 12 | 0 | 00:00:01 |
------------------------------------------------------------------------------------------------
statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
2119 consistent gets
0 physical reads
0 redo size
528 bytes sent via sql*net to client
520 bytes received via sql*net from client
2 sql*net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
查询时间由原来的:00:00:04.46 降至:00:00:00.21 提高了4秒多。
逻辑读:26115 降至:2119
递归调用:96 降至:0
内存排序:32 降至:0
整体的查询效率有了很大的提高。
七、总结
1、os thread startup 等待事件一般与并行相关;
2、在创建索引与重建索引加并行时,索引调整完后,需要关闭并行度;
3、从最后的执行计划来看,并行不一定会使查询变快,可能会起到相反的作用,oltp数据库慎用并行;
oracle相关文章推荐
| oracle: | url |
|---|---|
| 《oracle 自动收集统计信息机制》 | https://www.modb.pro/db/403670 |
| 《oracle_索引重建—优化索引碎片》 | https://www.modb.pro/db/399543 |
| 《dba_tab_modifications表的刷新策略测试》 | https://www.modb.pro/db/414692 |
| 《fy_recover_data.dbf》 | https://www.modb.pro/doc/74682 |
| 《oracle rac 集群迁移文件操作.pdf》 | https://www.modb.pro/doc/72985 |
| 《oracle date 字段索引使用测试.dbf》 | https://www.modb.pro/doc/72521 |
| 《oracle 诊断案例 :因应用死循环导致的cpu过高》 | https://www.modb.pro/db/483047 |
| 《oracle 慢sql监控脚本》 | https://www.modb.pro/db/479620 |
| 《oracle 慢sql监控测试及监控脚本.pdf》 | https://www.modb.pro/doc/76068 |
| 《oracle 脚本实现简单的审计功能》 | https://www.modb.pro/db/450052 |
| 《记录一起索引rebuild与收集统计信息的事故》 | https://www.modb.pro/db/408934 |
| 《rac dg删除备库redo时报ora-01623》 | https://www.modb.pro/db/515939 |