引言
我们都知道数据库是有事务隔离级别的,在读未提交的情况下,会出现脏读的现象,即某个会话会读到其他会话还没提交的事务。oracle默认的隔离级别是读提交,是不会出现脏读的现象,本次故障就是由于应用读到了没能提交的事务,导致的交易异常。
问题现象
某天晚上,公司的存储发生了故障,导致数据库重启了,本来也没啥,过了几天项目组的同事找到我,说有一笔账单异常了,让帮忙从数据库上查一下,情况是这样的:这个交易涉及三个系统a、b、c。a系统向b系统发起转账请求,b系统记账,并转发给c系统,c系统转账完成回复b系统,b系统更新刚才的账单状态为已完成,并返回给a系统。a系统如果在超时时间内没收到b系统返回,会发起二次查询,查询b系统的这条账单的状态。当时出现的问题是c系统完成了转账,并有记录,a系统是在超时时间内没收到b系统返回,发起的二次查询发现b系统的账单状态时已完成转账。b系统自己数据库记录的这条转账状态为未完成。
问题分析
步骤1:捋捋逻辑和时间线
针对这个问题,根据应用日志先捋下时间线:
22:53:46,345 =====》b系统数据库插入转账记录,并标记转账状态为未完成。这是个insert操作。
22:53:46,589 =====》b系统接到c系统转账成功的消息,更新数据库中转账状态为已完成,这是个update操作。
22:53:57,519 =====》b系统接到a系统的二次查询,显示刚才的转账状态为已完成,这是个select操作。
第二天 =====》项目组登录b数据库,查询这条交易转账状态为未完成。这是个select操作。
针对这个特殊情况,我跟项目组讨论了以下怀疑的点:
a、表中是否有多条重复记录? =======》根据唯一键交易流水号查询,无重复值
b、人为修改的? ===============》不可能,堡垒机上没查到相关的操作。与相关维护人员确认,没人动过。
c、a系统是发起二次查询复用了insert和update的连接?======》这是串台了吗?脑洞也太大了,而且二次查询发起的服务器和前面的insert的服务器都不是一台。
d、应用逻辑问题? ============》这套系统是公司十分重要的系统,已经运行多年,从来没出现过这总情况。
步骤2:日志挖掘
a系统二次查询和项目组查询的结果不一致,到底update语句执行了吗?虽然应用日志里有记录,但是这个问题还是需要确认下,我想起了可以通过挖掘redo日志的方法确认,在提交了的事务一定在redolog里有记录,先从带库对日志进行了恢复,在演练环境进行了日志挖掘,具体挖掘步骤不说了,回头可以额单独写一篇文章介绍。
这个表是有唯一键的,根据唯一键对挖掘的日志进行了搜索,只收到了insert的那一句,并未查到update,既然redo里没有,这说明update没提交!!!!
这个可以解释第二天查询的交易状态为未完成,但是没法解释a系统的二次查询的转账状态为已完成这个情况啊。而且该表中有一个字段是time,该字段在insert的时候会插入执行的时间戳,
在update的时候,也会更新成最新的时间戳,应用日志中显示,a系统二次查询出的该条交易的time字段的值和应用日志里记录的update的时候的值都是22:53:46.589,这说明应用日志里的update肯定是执行了,a系统二次查询就是查询的这条记录。
步骤3:深入oracle事务提交原理
问题分析到这个是,感觉陷入死胡同了,一方面a系统二次查询确实是查到了b系统数据库执行update后的这条记录,另一方面redo日志里又没有update的这个操作。项目组的人说这不会是oracle的bug吧,妥妥的脏读啊,这如果真是oracle的bug,我觉得我可能要封神了,哈哈哈。冷静下来还是仔细分析吧。仔细分析故障时的现象,当时是san交换机故障,数据库无法访问存储,查看数据库的alert日志,发现有大量lgwr all worker groups' for 2 secs字样,这是lgwr进程写重做日志的时候的等待,这么看来问题可能出现在update提交的时候。我们分解下事务提交的流程:
oracle事务提交时候流程:
1)为更新undo事务表生成一条更改向量
2)将更改向量复制到日志缓冲区
3)在undo端头块上应用更改向量
4)通知lgwr写日志
5)lgwr 将 log buffer中的日志写入redo
6)返回 commit complete.
从事务提交流程看,应该是第5步夯住了,如果前四步已经做完了,尽管redo日志还没有从redo buffer写入到redolog,其它会话也是可以看到该事务在内存中的数据,而随后db出现实例重启,你可能发现提交的事务被
恢复了,而严格意义上说,这个事务也并没有提交。
步骤4:场景复现
基于以上理解,我做了以下测试,可以看出,确实复现了当时的场景。
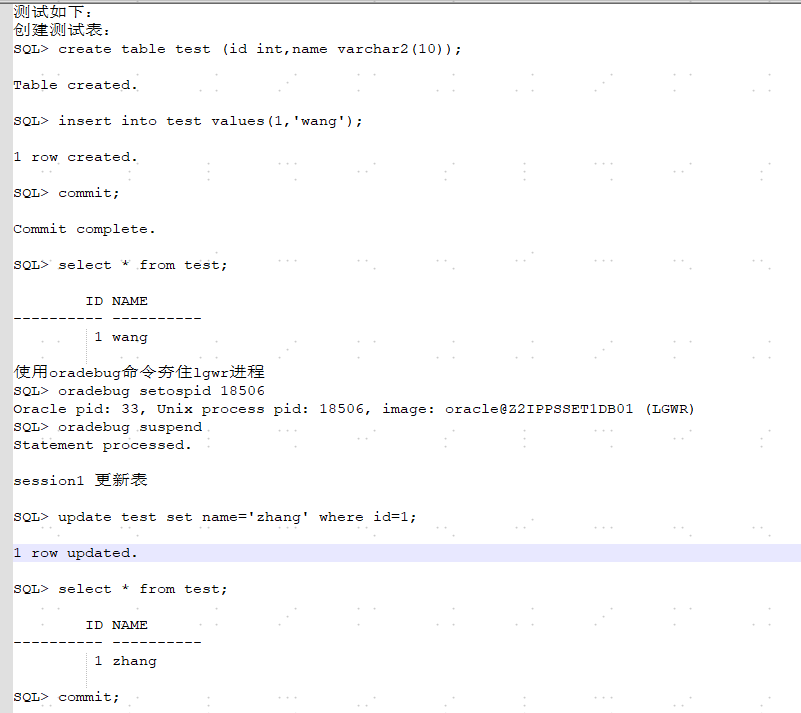
总结
至此,以上问题原因应该很清晰了,本文碰到的这个问题在oracle的一本书里有记载(忘记哪本书了,大概是个外国人写的)。本次碰到的这个场景还是比较极端的,在生产环境应该不大容易遇到。