table of contents
- 表,数据库中最基本的数据存储单元,数据在数据库中的存储形式是行和列。
- 一个行,就是由表中定义的列相应的具体值组成的。
- 理论属性
- 表的字段数最大可达到1000。
- 表的记录行,可以无限。
- 一个表可以有无限个索引。
- 数据库可以存储的表数量不受限制。
注意:理论上是这样的,至少数据库本身是支持的,但实际上可能受到操作系统或其他方面的限制。
表的分类
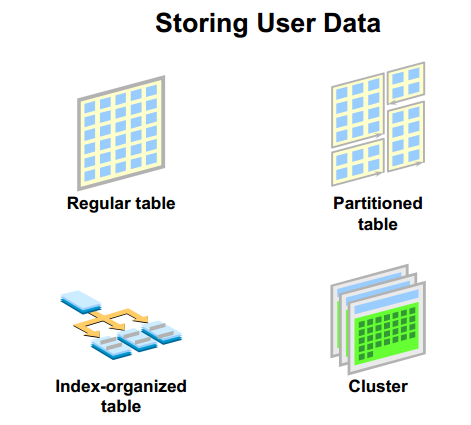
1)常规表
- 常规表(通常称为 “表”)是存储用户数据最常用的形式,它是缺省表。
- 数据库管理员对表中行分布的控制很有限。
- 行可能按任意顺序存储,具体顺序取决于在表中进行的操作。
- 表里的每行数据可以按用户指定的顺序排序。
- 每个表在数据库中对应一个segment。
- 数据存储方式是堆表形式。
- 堆组织表中,数据以堆的方式管理。
- 增加数据时,会使用段中找到的第一个能放下此数据的自由空间。
- 从表中删除数据后,允许以后的
insert和update重用这部分空间。 - 堆(heap)是一组空间,以一种随机的方式使用。因此,无法保证按照放入表中的顺序取得数据。
- 堆表具有的唯一优点是 插入数据不需要采取任何措施,只需要顺其自然地插入的顺序存储。
2)分区表
- 每个分区表有一个或多个分区,每个分区存储已分区(使用范围分区、散列分区、组合分区或列表分区)的行。
- 分区表中的每个分区为一个段,可各自位于不同的表空间中。
- 对于能够同时使用几个进程进行查询或操作的大型表,分区非常有用。
- 分区表最主要的一个作用就是大表转化为小表的形式存储数据,
- 不同分区的数据是存储在不同的segment,分区上可以建立分区索引,称为本地索引。
- 分区表可以提高表的访问速度,特别是大表,因为数据是存储在不同分区segment。
# 查询某个分区的数据:
sql> select * from time_range_sales partition(sales_2001);
# 查看与分区相关的字典:
sql> select table_name from dict where lower(table_name) like '%part%' order by 1;
# 分区表本身的信息:
sql> select table_name,partitioning_type,partition_count
2 from dba_part_tables
3 where table_name='time_range_sales';
# 查询分区信息:
sql> select table_name,partition_name,tablespace_name,high_value
2 from dba_tab_partitions where table_name = 'time_range_sales'
3 order by 2;
分区类型有:
1)range partition 范围分区
create table time_range_sales
( prod_id number(6)
, cust_id number
, time_id date
, channel_id char(1)
, promo_id number(6)
, quantity_sold number(3)
, amount_sold number(10,2)
)
partition by range (time_id)
(partition sales_1998 values less than (to_date('01-jan-1999','dd-mon-yyyy')),
partition sales_1999 values less than (to_date('01-jan-2000','dd-mon-yyyy')),
partition sales_2000 values less than (to_date('01-jan-2001','dd-mon-yyyy')),
partition sales_2001 values less than (maxvalue)
);
2)hash partition 哈希分区
create table hash_products
( product_id number(6) primary key
, product_name varchar2(50)
, product_description varchar2(2000)
, category_id number(2)
, weight_class number(1)
, warranty_period interval year to month
, supplier_id number(6)
, product_status varchar2(20)
, list_price number(8,2)
, min_price number(8,2)
, catalog_url varchar2(50)
, constraint product_status_lov_demo
check (product_status in ('orderable'
,'planned'
,'under development'
,'obsolete')
) )
partition by hash (product_id)
partitions 4
store in (tbs_01, tbs_02, tbs_03, tbs_04);
3)list partition 列表分区
create table list_sales
( prod_id number(6)
, cust_id number
, time_id date
, channel_id char(1)
, promo_id number(6)
, quantity_sold number(3)
, amount_sold number(10,2)
)
partition by list (channel_id)
( partition even_channels values (2,4),
partition odd_channels values (3,9)
);
4)composite partition 组合分区
组合分区是指最开始选定以上三种中的其中一种初步分区, 再选一种划分子分区
所以根据初步分区的方式组合分区又可以细分为三种:
composite_range_partitionscomposite_list_partitionscomposite_hash_partitions
分区索引
a partitioned index is an index that, like a partitioned table,has been decomposed into smaller and more manageable pieces.
like partitioned tables, partitioned indexes improve manageability, availability, performance, and scalability.
global indexes are partitioned independently of the table on which they are created
local indexes are automatically linked to the partitioning method for a table.
# local partitioned indexes 局部分区索引
create index time_range_sales_idx on time_range_sales(time_id) local;
# global partitioned index 全局分区索引
create index time_channel_sales_idx on time_range_sales (channel_id)
global partition by range (channel_id)
( partition p1 values less than (3),
partition p2 values less than (4),
partition p3 values less than (maxvalue)
);
注意:
在整个分区上可以建立全局索引,但是当有创建新分区或删除分区时全局索引失效,必须重建全局索引,否则全局索引失效。
3)按索引组织的表
与普通表(堆表)不同,在索引组织表中数据是按主键存储在b-tree树中的,当创建索引时,b-tree中每个节点不仅存储了行数据也存储了索引值。
这样当按主键查询时,因为索引和表数据是存储在一个节点中的,查询速度会相应提高。
- 按索引组织的表就像在一个或多个列中具有主键索引的堆表。
- 按索引组织的表并不为表和b树索引维护两个单独的存储空间,而是仅维护一个包含表主键和其它列值的b树。
- 由于设置
pctthreshold值以及较长的行长度需要溢出区域,所以可能存在溢出段。 - 按索引组织的表为进行涉及精确匹配和范围搜索的查询,提供基于键的、对表数据的快速访问。
- 存储要求降低了,因为键列在表和索引中不重复。
- 除非索引条目变得非常大,否则其余的非键列就存储在索引中;在此情况下,oracle服务器提供 overflow 子句来处理此问题。
4)集簇表
- 集簇表为存储表数据提供另一种可选的方法。
- 簇由一个表或共享相同数据块的一组表构成,它们之所以被组织在一起,是因为它们共享共同的列并且经常一起使用。
- 簇具有以下特点:
- 簇有一个集簇键,用来标识需要存储在一起的多个行。
- 集簇键可由一个或多个列组成。
- 簇中的表具有与集簇键相对应的列。
- 集簇是一种对使用表的应用程序透明的机制,像操作存储在常规表中的数据那样操作集簇表中的数据。
- 更新集簇键中的一列可能需要移植该行。
- 集簇键独立于主键。簇中的表可有一个主键,它可以是集簇键,也可以是另一组列。
- 创建簇通常是为了改善性能。随机访问集簇数据更快,而对集簇表进行全表扫描通常较慢。
- 簇会重新规范表的物理存储,但不影响其逻辑结构。
表的行结构
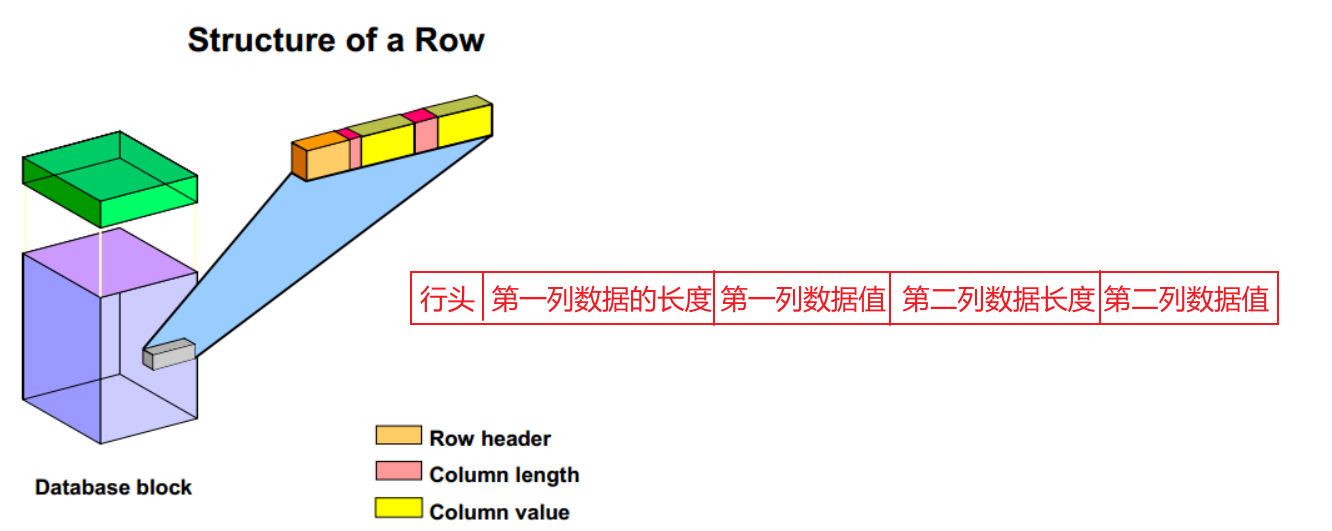
行数据作为长度可变的记录存储在数据库块中。
通常,一个行的各列按其定义时的顺序存储,并且不存储尾随的null列。
对于非尾随的null列,列长度需要占用一个字节。
表中的每行具有:
行头:用来存储行中的列数、链接信息和行锁定状态
行数据:对于每一列,存储列的长度和值。
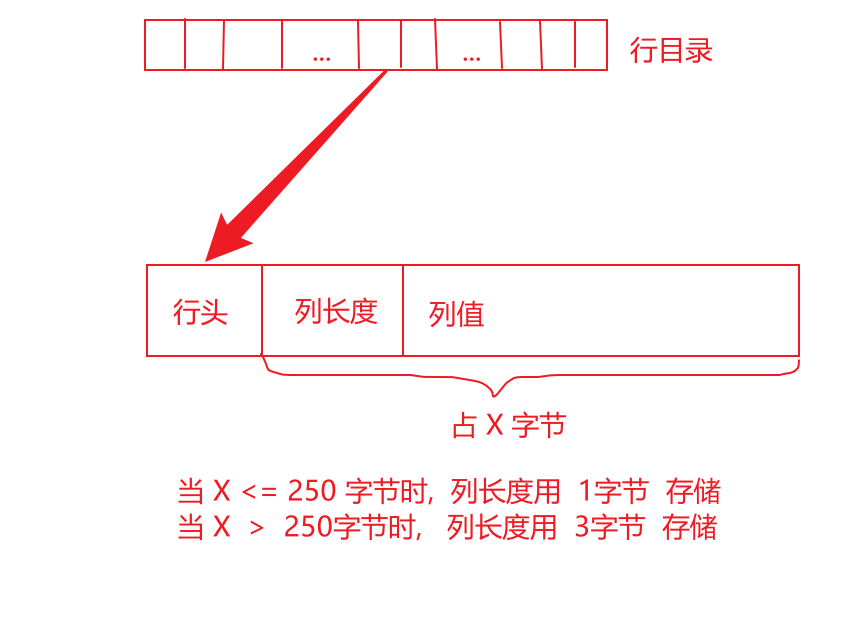
如果该列不超过250个字节,则需要一个字节来存储列长度;
如果该列超过250个字节,则需要三个字节来存储列长度。
列值在紧靠列长度字节后面存储。
相邻的行之间不需要任何空格。
块中的每一行在行目录中都有一个位置。目录位置指向行首。
rowid格式
- rowid是每个行记录在数据库中的唯一标识,它是oracle根据行的物理位置自动算出来的。
- 表中并没有存储rowid,只是个伪列,在select查询时使用它。
- 虽然rowid并没有直接给出行的物理位置,但能定位一个行。
- 快速访问一个行可以通过rowid,因为rowid能快速定位一个行记录。
如何通过rowid确定一行记录:
- oracle服务器使用数据对象编号来确定包含某一行的表空间
- 相关文件编号用来定位表空间中的文件
- 块编号用来定位包含该行的块
- 行编号用来定位该行的行目录条目
- 行目录条目可以用来定位行首
- 根据行首内容获取到行记录
rowid 是 64 进制的,由0-9 a-z a-z /组成 。
一个块8kb,最多存储733个行。
行迁移与行链接
行迁移 row migration
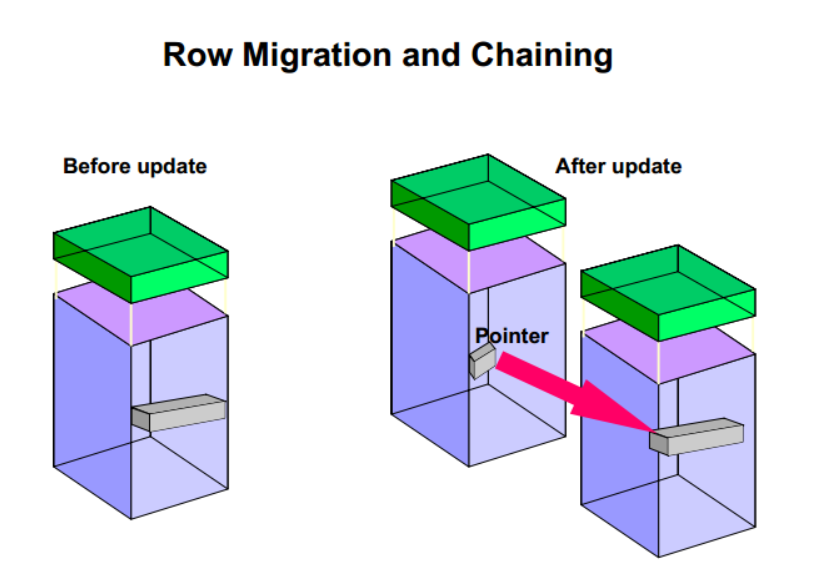
在一个块中可能没有足够的空间来容纳更新后增长的行。
出现这种情况时,oracle服务器就会把整个行移到一个新块,并创建一个从原块指向新位置的指针。
行链接 row chaining
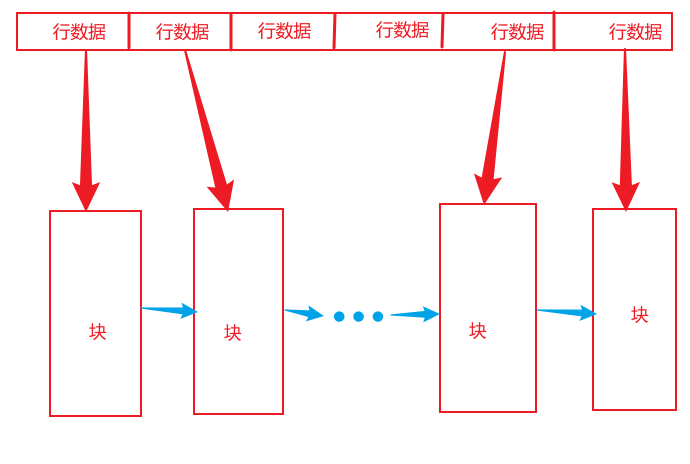
如果一个行过大而任何一个块都容纳不下,就会发生行链接。
如果行包含的列太长,就可能发生这种情况。
在这种情况下,oracle服务器将该行拆分成更小的数据块,称为 “行片段”。
每个行片段存储在一个块中,并带有检索和组合整行所需要的指针。
注意: 若发生行迁移或行链接,与该行相关联的i/o性能会降低,因为oracle服务器必须扫描两个数据块才能检索该数据。
如果可能,可通过选择较大的块大小 或 将一个表拆分成包含更少列的多个表来最大限度地减少行链接。
表重组
- 将表迁移到另一个表空间
- 重组表,以减少表的行迁移记录数
注意: 当表运行一段时间后,表中的数据会被删除,导致了高水位下有空的数据块,或者不满的数据块,数据库在处理全表扫描的时候总是读高水位下所有的数据块。降低了全表扫描的效率,我们将表挪动表空间后,数据会紧密的码放,释放多余的空间,回收了高水位线。提高了全表扫描的性能,节约了存储空间。
迁移过程
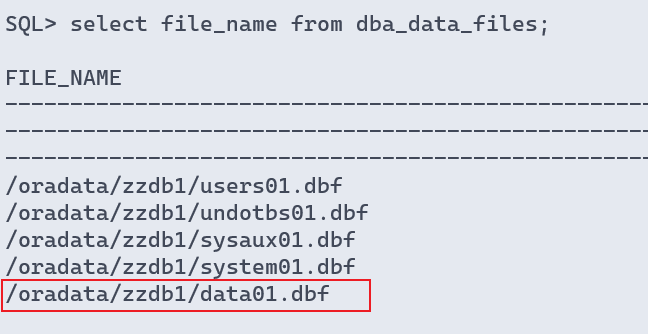
- 创建新表空间
sql> select file_name from dba_data_files;
sql> create tablespace data1 datafile '/oradata/zzdb1/data1_1.dbf' size 10m;
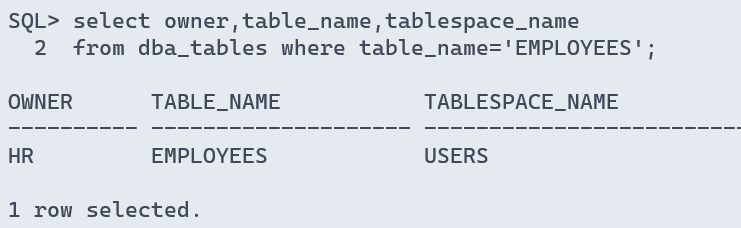
- 查看表所在的表空间
sql> select owner,table_name,tablespace_name
2 from dba_tables where table_name='employees';
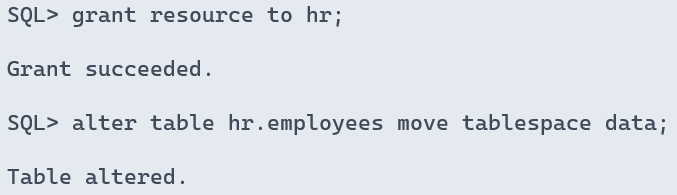
- 将表的表空间更改为 data1
sql> alter table hr.employees move tablespace data1;
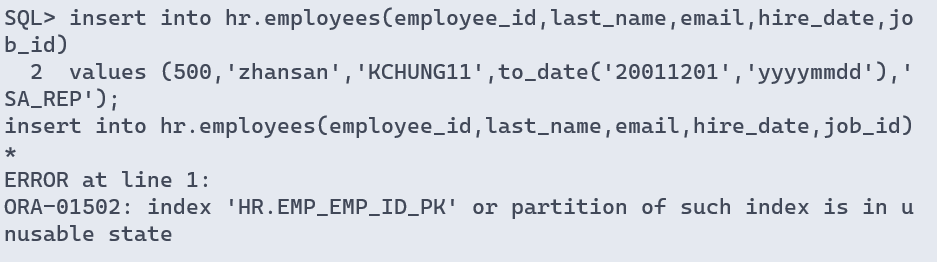
- 解决插入数据时索引失效
sql> insert into hr.employees(employee_id,last_name,email,hire_date,job_id)
2 values (500,'zhansan','kchung11',to_date('20011201','yyyymmdd'),'sa_rep');
insert into employees(employee_id,last_name,email,hire_date,job_id)
*
error at line 1:
ora-01502: index 'hr.emp_email_uk' or partition of such index is in unusable state
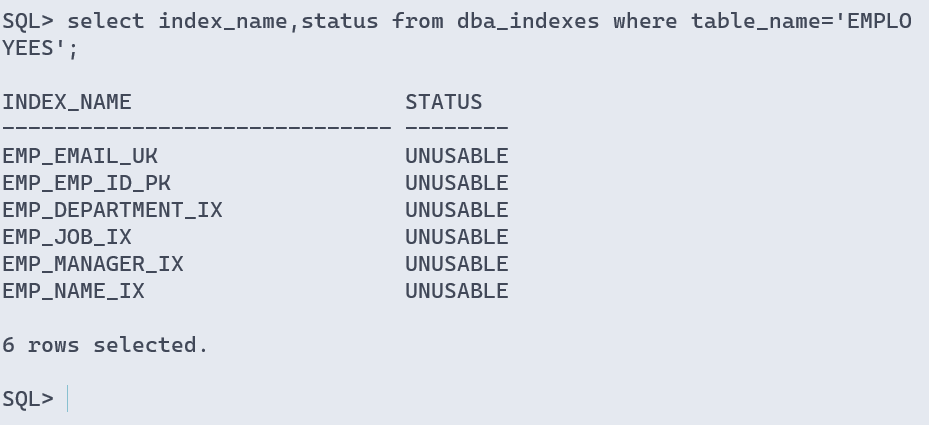
# 查看表的所有索引
sql> select index_name,status from dba_indexes where table_name='employees';
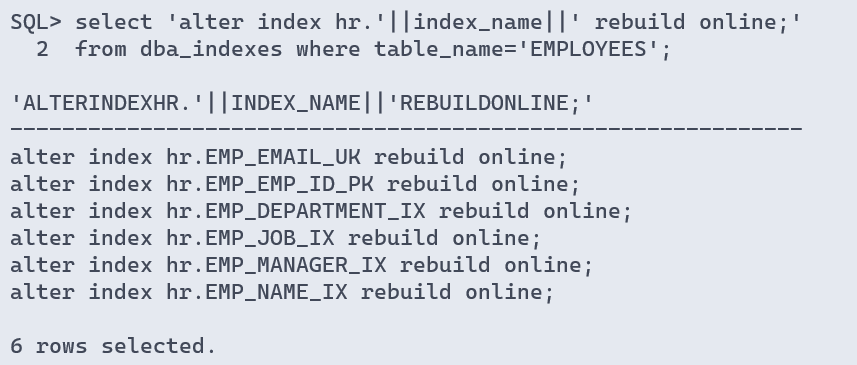
# 生成索引rebuild语句并执行
alter index xx rebuild online;
sql> select 'alter index hr.'||index_name||' rebuild online;'
2 from dba_indexes where table_name='employees';
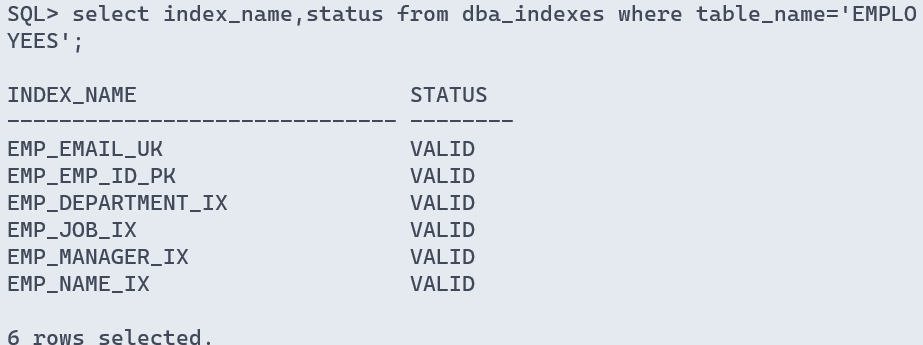
sql> select index_name,status from dba_indexes where table_name='employees';
# 再次插入数据
sql> insert into
2 hr.employees(employee_id,last_name,email,hire_date,job_id)
3 values (500,'zhansan','kchung11',to_date('20011201','yyyymmdd'),'sa_rep');
sql> commit;
sql> select employee_id,last_name,email,to_char(hire_date,'yyyy-mm-dd')
2 as hire_date,job_id
3 from hr.employees where employee_id > 300;
# 查看修改后表的表空间
sql> select owner,table_name,tablespace_name
2 from dba_tables where table_name='employees';
表删除及清空数据
truncate表
sql> truncate table scott.t1;
仅仅清空数据,很少的redo。
清空表,表中记录都删除了,且释放表使用的空间。
相应的索引也清空了。
未产生undo数据。
存在外键的表不能清空。
触发器不启用。
delete表数据
delete from scott.t1
如果表数据量大,delete会很长时间,产生大量redo日志。
drop表
sql> drop table scott.t1 cascade constraints;
表不存在了,从oracle数据库删除掉。
删除表,不仅仅是清空表的记录,表不存在了。空间也释放了。
表的压缩
使用压缩的方法存储表中的数据,使表的占用空间少,从而提高内存的使用率。
- 创建普通表
sql> conn scott/tiger
sql> drop table t1 purge;
sql> create table t1 as select * from emp;
sql> insert into t1 select * from t1;
- 创建压缩表
sql> drop table t2 purge;
sql> create table t2 compress as select * from t1 order by ename;
- 查看占用空间
sql> col segment_name for a30
sql> select segment_name,blocks
2 from user_segments where segment_name in('t1','t2');
segment_name blocks
------------------------------ ----------
t1 3200
t2 768
注意:
压缩存储的原理是每个块内相同的数据只存放一次,所以我们在压缩表的时候最好要排序。
我们把大的静态表压缩存储,这样既可以节约存储空间又提高了 i/o 的效率,还节约了内存的使用,
但是经常 update 的表我们不要压缩存储会下降 dml 的性能。
临时表
创建临时表空间的动作不涉及存储空间的分配, oracle不会为此分配初始区段
除了在特定情况下临时表会删除
一般情况下, 创建应用用户时, 会自动分配两个默认的表空间:
appdata_tbs 用户数据表空间
apptemp_tbs 用户临时表空间
# 创建on commit preserve rows临时表
# on commit preserve rows 提交后数据不删除,中断会话后删除
sql> create global temporary table test1(id number,name varchar2(10))
2 on commit preserve rows;
# 创建on commit delete rows临时表
# on commit delete rows 提交或回滚就删除数据
sql> create global temporary table test2(id number,name varchar2(10))
2 on commit delete rows;
#