[toc]
背景:
我们会经常在一些客户的awr报告中,能够看到如下类似信息,sql的前缀部分都一样,执行时间也基本一致,详细查看具体的sql_text后,我们可以看到仅仅是where条件中的变量值不一样,其他都一样,没有采用绑定变量的方式,而是一个个常量。
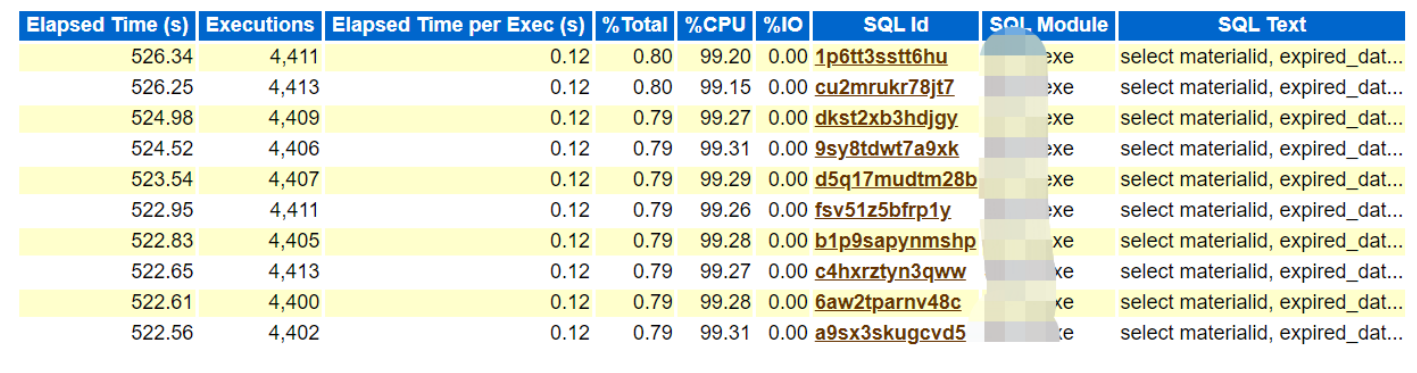
对于这种在awr报告中,能够体现出来的,我们比较容易发现,可及时反馈给开发人员处理。但是在一些环境中,系统中其实存在较多的未使用绑定变量的sql,但是在awr报告top sql部分,并没有体现出来,这个时候,就需要我们去数据库中手动捞取。
当oracle中存在大量的类似sql,基本结构一样,仅where条件的取值不一样时,我们应该采用绑定变量的方法,来减少sql的硬解析,能够提高数据库性能,避免出现shared pool相关的等待事件,同时也能节约cpu资源。
下面我们通过案例,如果查询数据库中未使用绑定变量的sql?
-- 创建测试表,并插入数据
sql> set timing on
sql> drop table t purge;
table dropped.
elapsed: 00:00:00.18
sql> create table t(x int);
table created.
elapsed: 00:00:00.04
sql> begin
2 for i in 1 .. 1000
3 loop
4 execute immediate
5 'insert into t values (:x)' using i;
6 end loop;
7 commit;
8 end;
9 /
pl/sql procedure successfully completed.
elapsed: 00:00:00.03
sql> select count(*) from t;
count(*)
----------
1000
elapsed: 00:00:00.00
– 方便演示,我们清理一下shared pool
sql> alter system flush shared_pool;
system altered.
elapsed: 00:00:00.12
2.1 未使用绑定变量
sql> begin
2 for i in 1 .. 1000
3 loop
4 execute immediate
5 'select /*tag1*/ count(*) from t where x= '||i||'';
6 end loop;
7 commit;
8 end;
9 /
pl/sql procedure successfully completed.
elapsed: 00:00:00.38
2.2 使用绑定变量
sql> begin
2 for i in 1 .. 1000
3 loop
4 execute immediate
5 'select /*tag2*/ count(*) from t where x= :1' using i;
6 end loop;
7 commit;
8 end;
9 /
pl/sql procedure successfully completed.
elapsed: 00:00:00.01
方法一:通过force_matching_signature分析
10g以后v$sql动态性能视图增加了force_matching_signature列,其官方定义为:
the signature used when the cursor_sharing parameter is set to force,也就是oracle通过将原sql_text转换为可能的force模式后计算得到的一个signature值。我们知道,如果cursor sharing设置为force , oracle将类似的sql的谓词用一个变量代替,同时将它们看做同一条sql语句处理。
sql> set numwidth 20
sql> select force_matching_signature,count(1) from v$sql group by force_matching_signature order by count(1) desc;
force_matching_signature count(1)
------------------------ --------------------
11420119939742656807 1000
0 14
4650186927289073934 2
6434074771071323635 2
1435631005720608251 1
12313764141852424472 1
9194475184364435657 1
12005390545862180746 1
sql> select sql_text from v$sql where force_matching_signature=11420119939742656807 and rownum<10;
sql_text
--------------------------------------------------------------------------------
select /*tag1*/ count(*) from t where x= 782
select /*tag1*/ count(*) from t where x= 497
select /*tag1*/ count(*) from t where x= 286
select /*tag1*/ count(*) from t where x= 937
select /*tag1*/ count(*) from t where x= 458
select /*tag1*/ count(*) from t where x= 969
select /*tag1*/ count(*) from t where x= 637
select /*tag1*/ count(*) from t where x= 161
select /*tag1*/ count(*) from t where x= 742
9 rows selected.
elapsed: 00:00:00.00
将上面sql整合到一起,如下:
select sql_text, sql_id, executions, parse_calls,force_matching_signature from v$sql where force_matching_signature in
(select force_matching_signature from (
select force_matching_signature,count(1) from v$sql group by force_matching_signature order by count(1) desc
) where rownum<10);
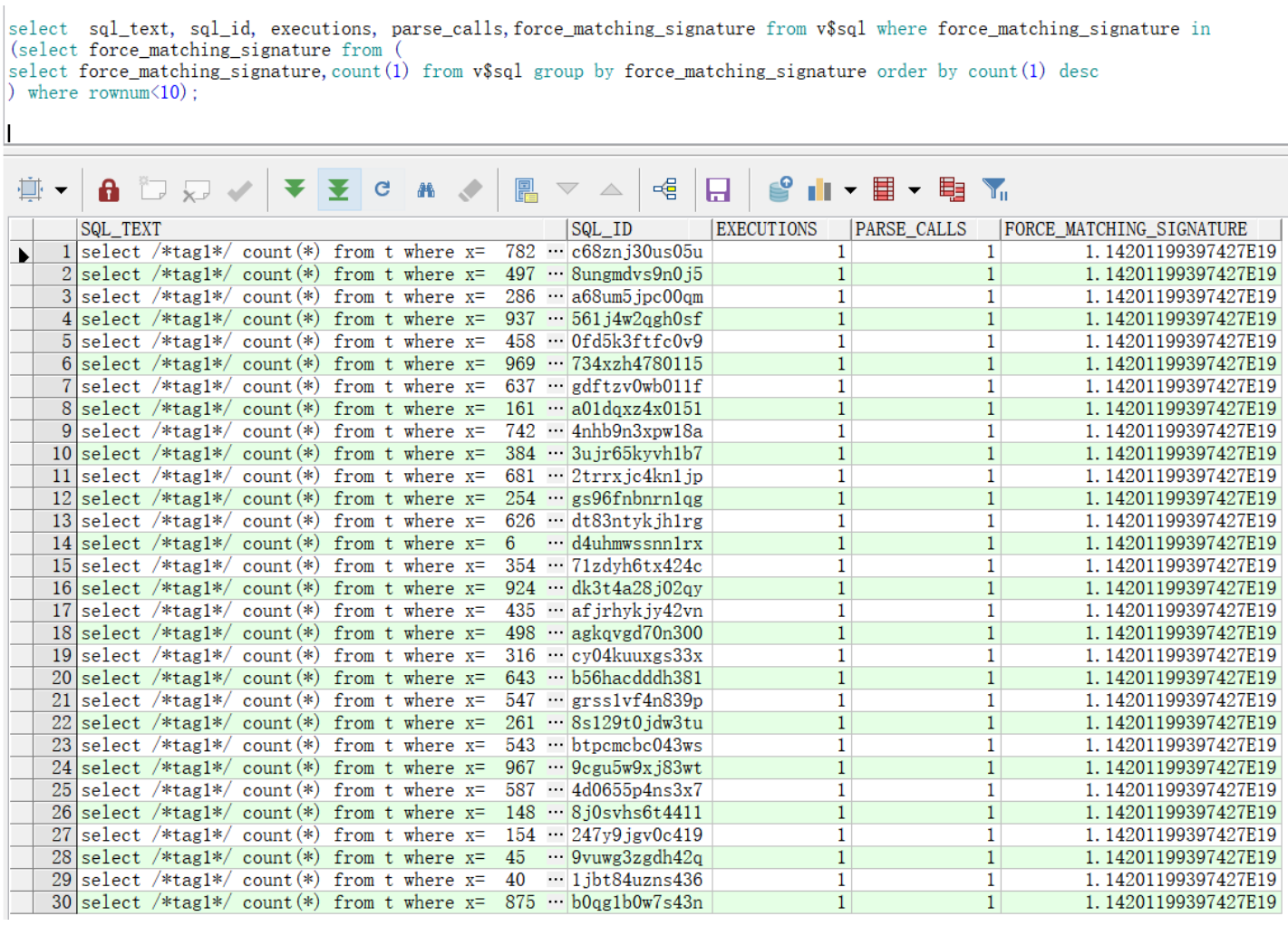
方法二:通过sql文本分析
select substr(sql_text,1,50),count(1) from v$sql group by substr(sql_text,1,50) order by count(1) desc;
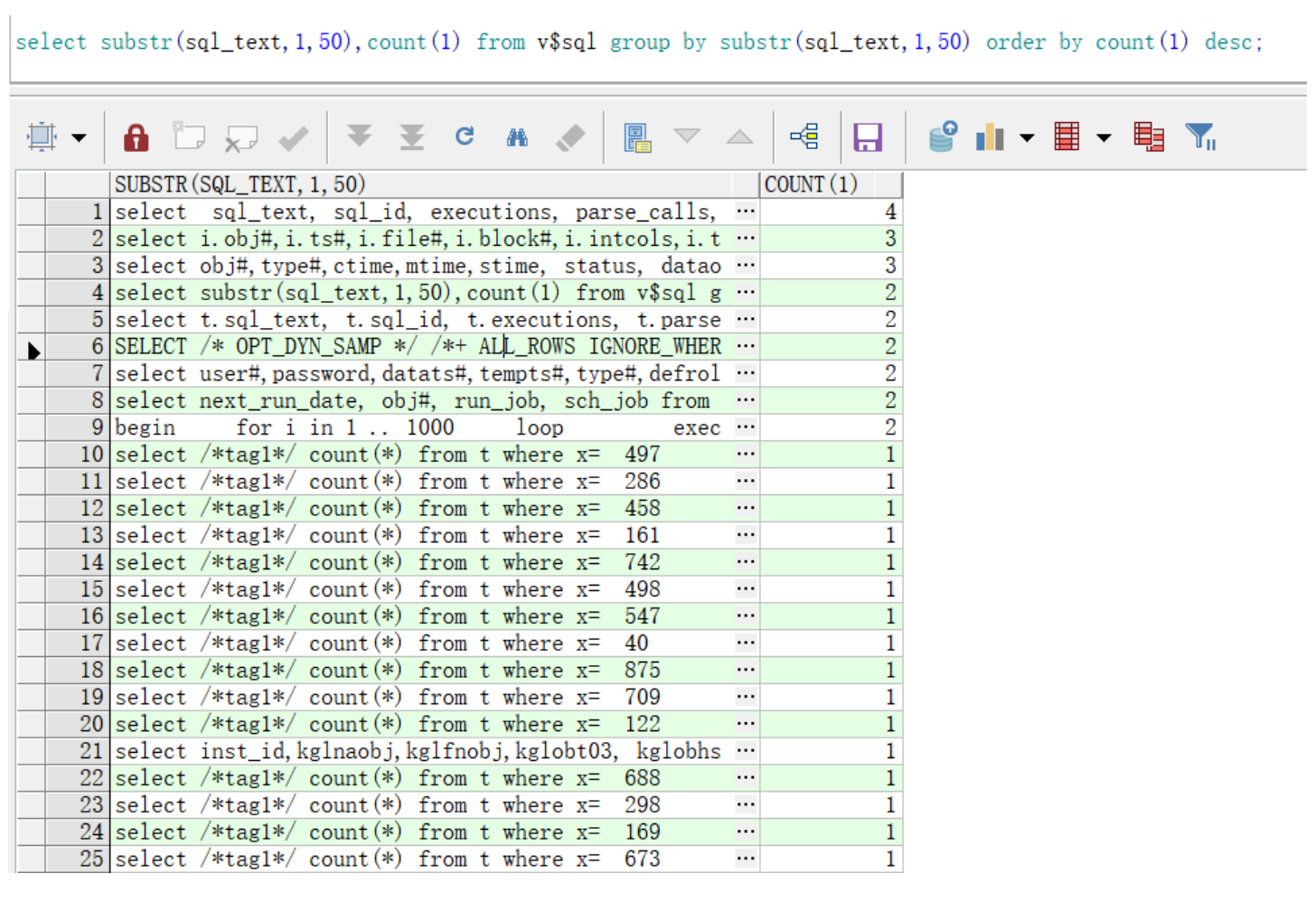
4.1 未使用绑定变量
select t.sql_text, t.sql_id, t.executions, t.parse_calls,force_matching_signature
from v$sql t
where sql_text like 'select /*tag1*/ count(*) from t%';
结论:产生1000个的类似sql,基本结构一样,仅where条件的取值不一样,每个sql都执行一次,解析一次。
4.2 使用绑定变量
select t.sql_text, t.sql_id, t.executions, t.parse_calls,force_matching_signature
from v$sql t
where sql_text like 'select /*tag2*/ count(*) from t%';
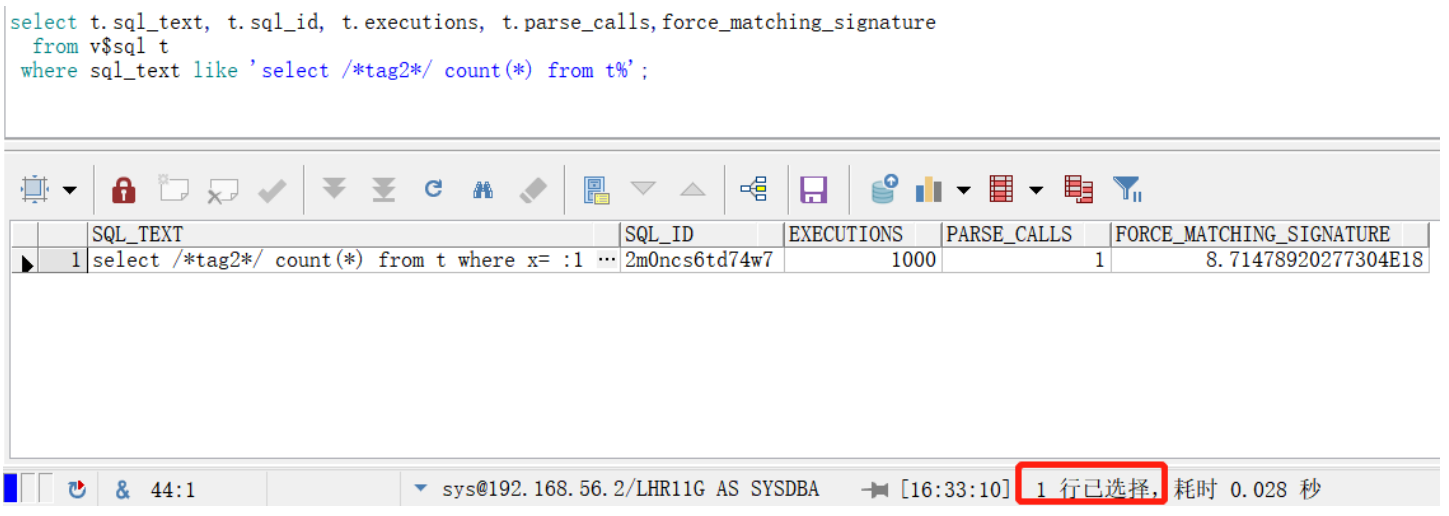
结论:1. 仅产生1个sql,执行1000次,仅解析一次。和未使用绑定变量相比,性能更好。
2. 从案例演示中,2个sql执行时间来看,使用绑定变量的方式也比未使用绑定变量的方式快很多。