原文地址:
原文作者:chandan kumar
使用 zeppelin 通过 heatwave 访问 mds 的完整指南
在本指南中,我们将介绍如何安装和使用 heatwave 访问 mds。
1. 什么是 mds 和 heatwave?
2. 什么是 zeppelin?
3. 环境细节
4. 如何安装 zeppelin?
5. 网络方面的考虑
6. 如何访问 heatwave
7. 使用 zeppelin 的 mds 数据分析
8. 结语
============================================
我们生活在数据世界中,随着数据的高速增长,更快获得结果是非常重要的,直到早些时候,mysql 一直在挑战以更快的方式处理更大规模的数据,但是,目前 mysql 的m6米乐安卓版下载的解决方案有了 “范式转变”。
现在,mysql(仅在 oci 的 paas 模型中)配备了 heatwave,这是一个分布式的、可扩展的、无共享的、内存中的、混合列式的查询处理引擎,旨在实现极限性能。
当你向 mysql 数据库系统添加 heatwave 集群时,它就会被启用。
因此,mysql 数据库服务(mds)将给出更快的结果,然后需要一些数据分析工具来使数据有意义,获得更多的数据洞察力。
在这篇博客中,让我介绍一下 apache zeppelin 用于 mds 的数据分析。
apache zeppelin 是一个开源的多用途笔记本(notebook),它可以帮助用户以图形或图表的形式来表示和分析你的数据,从而帮助组织快速做出决定。
我们将详细探讨每个项目…
总的来说,我的想法是向你展示快速的演示,你如何轻松地通过 zeppelin 连接 mds。
zepplein 可以安装在任何地方(任何公共/私有云,企业内部)。
oracle mysql 数据库服务(mds)是一种完全可管理的数据库服务,可让开发人员使用世界上最流行的开源数据库快速开发和部署安全的云原生应用程序。
mysql 数据库服务是唯一具有集成的高性能内存查询加速器–heatwave 的 mysql 云服务。它使客户能够直接针对其运行中的 mysql 数据库运行复杂的分析,消除了对复杂、耗时和昂贵的数据移动以及与单独的分析数据库整合的需要。
mysql 数据库服务是由 oci 和 mysql 工程团队 100%建立、管理和支持的。
更多信息:-
heatwave:-
mds 的商业利益:-
zeppelin 是基于网络的笔记本,它可以用 sql、scala、python、r 等语言实现数据驱动、交互式数据分析和协作式文档。
像数据摄取、数据浏览、数据可视化和数据分析都可以在 zeppelin 笔记本中完成。
apache zeppelin 的特点
- 数据摄取-
- 数据发现-
- 数据分析-
- 数据可视化和协作
更多信息:-
确保在你的环境中,zeppelin 8080 的端口是白名单。
如果您使用的是 oracle 云基础设施(oci),那么请确保入口规则被配置为安装 zeppelin 的计算实例被加入白名单,同时计算实例能够与 mds 实例进行 ping。
要访问 zeppelin,一定要用有解释器 (**interpreter)**访问权限的适当用户,否则任何用户都可以访问你的 zeppelin。
有时,匿名用户通过输入 zeppelin 的公共 ip 地址进入 zeppelin 的门户,但如果你的解释器被限制在特定的用户,那么你的工作空间就会更安全。
因此,在 apache zeppelin 中拥有数据源授权是很重要的。
注:我无法深入了解安全方面的细节,我的主要重点是你在哪里,你如何访问 zeppelin,如何获得与 mds 和 heatwave 的无缝体验,并进行出色的可视化和数据分析。
在这篇博客中,zeppelin 的安装将在 oracle 云基础设施( )上进行。
使用以下软硬件配置
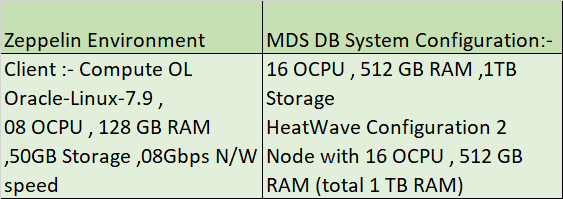
步骤 1 #安装 jdk
sudo yum install java-11-openjdk-devel
第 2 步:-使用以下命令下载 zeppelin
wget https://dlcdn.apache.org/zeppelin/zeppelin-0.10.0/zeppelin-0.10.0-bin-all.tgz
第 3 步 :- 创建用户并给予权限
sudo adduser -d /home/opc/zeppelin -s /sbin/nologin zeppelin
sudo chown -r zeppelin: zeppelin /home/opc/zeppelin
第 4 步:- 将 zeppelin 站点模板重命名为 zeppelin 站点
cd /home/opc/zeppelin/conf
sudo cp zeppelin-site.xml.template zeppelin-site.xml
sudo cp zeppelin-site.xml.template zeppelin-site.xml
步骤 5 :- #启动 zeppelin
http://<计算实例的 ip 地址/本地 ip>::8080/#/

下载 mysql connector/j
rpm -ivh mysql-connector-java-8.0.28-1.el7.noarch.rpm
warning: mysql-connector-java-8.0.28-1.el7.noarch.rpm: header v4 rsa/sha256 signature, key id 3a79bd29: nokey
**error**: failed dependencies:
java-headless >= 1:1.8.0 is needed by mysql-connector-java-1:8.0.28-1.el7.noarch
\[
用此命令修复以上错误:-
yum -y install java-headless
创建一个 mysql 解释器(interpreter)
#在 zeppelin 的 interpreter 文件夹下创建名为 mds 的目录
# mkdir mds
#将 "mysql-connector-java.jar "文件移到 mds 文件夹中
#cp /usr/share/java/mysql-connector-java.jar /home/opc/zeppelin/interpreter/mds/
导航到解释器(interpreter)
http://<计算实例的 ip 地址/本地 ip>:8080/#/interpreter
搜索 mds interpreter 并填写以下信息
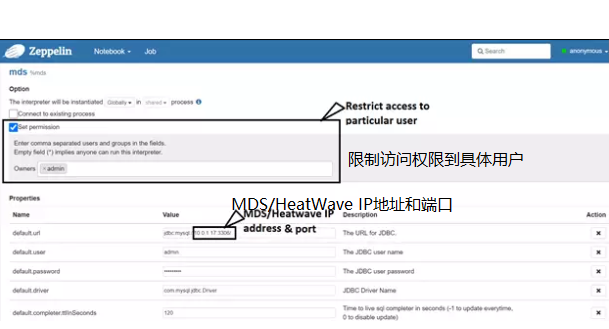
## 最后,一旦修改完成,它看起来就像下面这样
请确保 mds 和 heatwave 已经启动并运行。


棒极了! zeppelin 已连接 mds
在这个演示中,假设 mds 与 heatwave 已经启动并运行,并且数据已经加载到 heatwave 中。
如果你想关注快速启动演示,以及如何将数据加载到 heatwave,请点击以下链接。
演示中使用的模式是 “airportdb”,数据库大小为 50gb。
首次将数据加载到 heatwave 的命令:-
运行 auto parallel load 将 airportdb 数据加载到 heatwave 中:
call sys.heatwave\_load(json\_array('airportdb'), null);
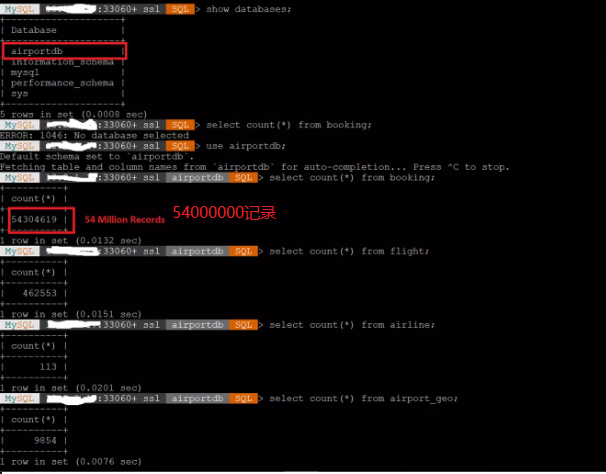
##运行以下 sql 语句来生成报告
use airportdb;
select airline.airlinename, sum(booking.price) as price\_tickets, count(\*) as nb\_tickets
from booking, flight, airline, airport\_geo
where booking.flight\_id=flight.flight\_id and
airline.airline\_id=flight.airline\_id and
flight.from=airport\_geo.airport\_id and
airport\_geo.country = "united states"
group by
airline.airlinename
order by
nb\_tickets desc, airline.airlinename limit 10;
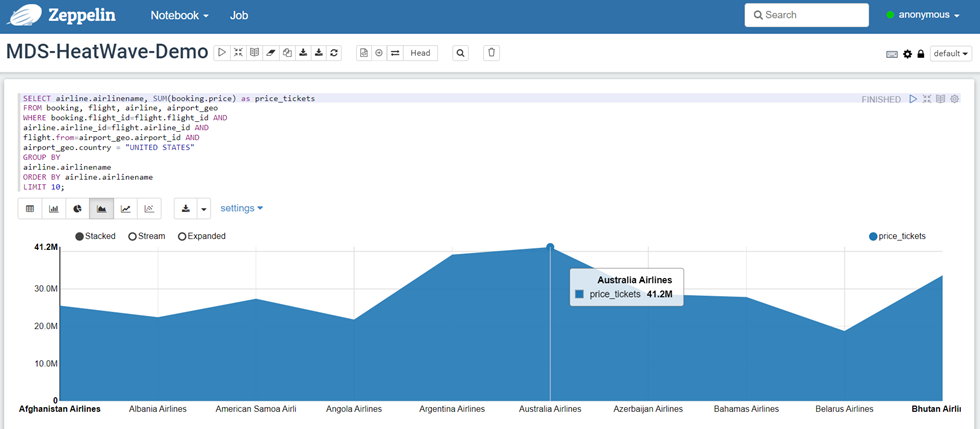
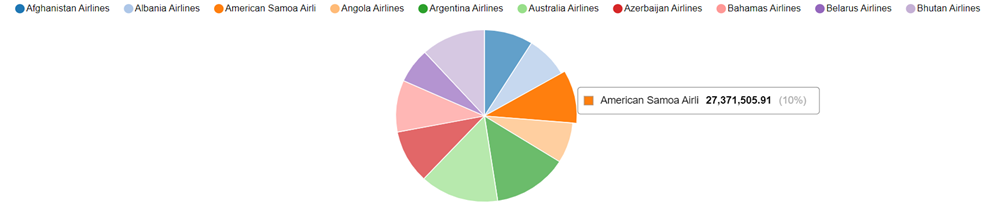
关于 heatwave 的更多信息:-
apache zeppelin 是一种工具,它使数据科学家的生活变得顺利,他们可以在一个地方做他们需要的一切。像数据摄取、数据浏览、数据可视化和数据分析都可以在 zeppelin 笔记本中完成,而 mds heatwave 是 oracle mysql 数据库服务的大规模并行、高性能、内存查询的加速器,可以依据分析和混合工作负载的重要性加速 mysql 的性能,成本却低于专家分析产品,如 amazon redshift、aurora、snowflake、azure synpase、google big query 等。