原文地址:https://pganalyze.com/blog/postgres-create-index
原文作者:lukas fittl
翻译:多米爸比
翻译说明:非完全按照原文进行全部翻译,且原文有一处错误,细心读者可以对比查找。
前言
大多数开发人员面临这样的挑战:他们刚编写的程序部署到生产环境后,应用系统突然变慢了。经过一些工具及监控系统的分析,发现是新编的代码里使用新的query语句引起。进一步分析根因是由query不能使用index引起。
那什么时候query可以使用索引,再postgres里我们如何正确的创建索引呢。本文我们将通过create
index命令详细了解它各个有用的方面,同时我们也会分析postgresql查询的操作符及数据类型,这样我们就可以如何选择最佳的索引定义。
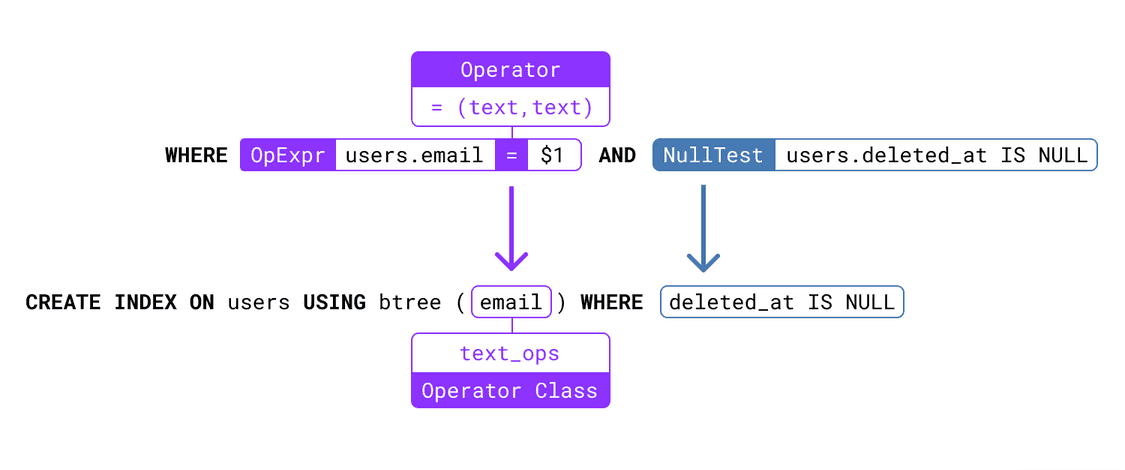
本文将主要围绕这张图展开
我们如何创建索引
首先,我们来看一下postgres里面创建索引的基本方式,它的语法是
create index on [table] ([column1]);
示例:比如用户表有一个针对email地址的查询语句。
select * from users where users.email = 'test@example.com';
我们知道这个语句是针对email这一列进行查询,因此我们的索引应该创建在用户表的这个特定列上。
create index on users (email);
当我们执行create index on users命令之后,postgres就帮我们创建好了索引。
需要注意的是:索引只是一个冗余的数据结构,也就是说我们即使删除了刚才创建的索引,我们也不会丢失任何的数据。使用索引的好处是帮助我们加速搜索表上特定的一些记录行。
postgres如何领会query
当postgres运行用户的语句时,会经历多个阶段,大概可以分成下面四个阶段:
- parsing
- parse analysis
- planning
- execution
在上面这些阶段里,query语句不再仅仅只是一个文本串,而是一个语法tree,每个阶段都会修改这棵树以及对它的结构进行注解,直到最后的执行阶段。
为了理解postgres数据库是如何使用索引,我们首先需要理解parse analysis阶段做了哪些事情。
我们再看稍微复杂一点的示例:
select * from users where users.email = 'test@example.com' and users.deleted_at is null;
根据email地址的查询语句,同时多了一个查询条件。
我们如果打开数据库debug_print_parse参数(生产环境禁用),可以从数据库日志看到详细的日志内容。
log: parse tree:
detail: {query
...
:quals
{boolexpr
:boolop and
:args (
{opexpr
:opno 98
:opfuncid 67
:opresulttype 16
:opretset false
:opcollid 0
:inputcollid 100
:args (
...
)
:location 38
}
{nulltest
:arg
...
:nulltesttype 0
:argisrow false
:location 80
}
...
日志输出的格式很难直接读懂,但我们可以通过下面的可视化来展示。

我们可以看到两个重要的解析节点,where子句里的opexpr节点和nulltest节点。首先来关注第一个opexpr节点。
理解操作符operators和数据类型data types
数据类型我们一般都很熟悉,这个我们再schema里面创建表时都用到过。操作符operator定义了一个数据类型值或者多个数据类型值如何进行比较。opexpr节点就代表着使用一个操作符去比较一个或多个给定的数据类型值的表达式。
在示例中我们使用的操作符可以从pg_operator系统表查询。
select oid, oid::regoperator, oprcode, oprnegate::regoperator
from pg_operator
where oprname = '=' and oprleft = 'text'::regtype and oprright = 'text'::regtype;
oid | oid | oprcode | oprnegate
----- -------------- --------- ---------------
98 | =(text,text) | texteq | <>(text,text)
(1 row)
从上面也可以看到操作符对应的内部实现函数。如果我们想弄清楚它的实现函数,可以查看texteq函数的源码。
/*
* comparison functions for text strings.
*/
datum
texteq(pg_function_args)
{
...
if (lc_collate_is_c(collid) ||
collid == default_collation_oid ||
pg_newlocale_from_collation(collid)->deterministic)
{
...
result = (memcmp(vardata_any(targ1), vardata_any(targ2),
len1 - varhdrsz) == 0);
...
}
else
{
...
result = (text_cmp(arg1, arg2, collid) == 0);
...
}
...
}
当然我们也可以创建自定义的操作符来为自定义数据类型服务。
操作符是创建正确索引最基本且最重要的因素之一。它决定我们如何搜索数据表的值。例如我们可以使用等号操作符来匹配输入值是否与列值相等,也可以使用两个@符号来对全文搜索列执行一个文本text值的匹配。
寻找正确的索引类型
那当我们使用不同的索引类型时,它的数据结构也限定了它所支持的操作符。比如postgres里最常用的索引类型是b-tree索引,它支持等号、范围比较<, <=, =>, >, ~ , ~*。
我们再来看一个例子,users表的全文搜索列上,我们需要使用两个@操作符来搜索这个列。
select * from users where about_text_search @@ to_tsquery('index');
如果我们只是简单的对这个列创建索引,不指定索引类型,那我们的查询语句还是会跟没创建索引一样继续使用全表扫描。
create index on users(about_text_search);
pgaweb=# explain select * from users where about_text_search @@ to_tsquery('index');
query plan
----------------------------------------------------------------------------
seq scan on users (cost=10000000000.00..10000000006.51 rows=1 width=4463)
filter: (about_text_search @@ to_tsquery('index'::text))
(2 rows)
因为通用的b-tree索引并没有支持全文检索类型数据结构,也并没有支持该操作符的操作符类。我们可以反过来通过全文检索操作符来确定我们可以使用哪种索引类型。
select am.amname as index_method,
opf.opfname as opfamily_name,
amop.amopopr::regoperator as opfamily_operator
from pg_am am,
pg_opfamily opf,
pg_amop amop
where opf.opfmethod = am.oid and amop.amopfamily = opf.oid
and amop.amopopr = '@@(tsvector,tsquery)'::regoperator;
index_method | opfamily_name | opfamily_operator
-------------- --------------- ----------------------
gist | tsvector_ops | @@(tsvector,tsquery)
gin | tsvector_ops | @@(tsvector,tsquery)
(2 rows)
从上面的结果我们知道可以使用gist或者gin索引。那我们使用using gin创建索引之后,再次执行语句,可以看到能使用索引。
=# explain select * from users where about_text_search @@ to_tsquery('index');
query plan
-------------------------------------------------------------------------------------------
bitmap heap scan on users (cost=8.25..12.51 rows=1 width=4463)
recheck cond: (about_text_search @@ to_tsquery('index'::text))
-> bitmap index scan on users_about_text_search_idx1 (cost=0.00..8.25 rows=1 width=0)
index cond: (about_text_search @@ to_tsquery('index'::text))
(4 rows)
前面查询postgres内部表时,还看到有一个tsvector_ops的名称,它有什么作用呢?
对于一个确定的操作符,可能会有多种不同的操作符分类,不同的操作符分类是指用于操作特定数据类型索引的最小运算符集,每个操作符分类定义着对某个指定索引类型的数据展现。
明确指定operator classes

我们来查询前面查询语句里用到的“=(text,text)”操作符
select am.amname as index_method,
opf.opfname as opfamily_name,
amop.amopopr::regoperator as opfamily_operator
from pg_am am,
pg_opfamily opf,
pg_amop amop
where opf.opfmethod = am.oid and amop.amopfamily = opf.oid
and amop.amopopr = '=(text,text)'::regoperator;
index_method | opfamily_name | opfamily_operator
-------------- ------------------ -------------------
btree | text_ops | =(text,text)
hash | text_ops | =(text,text)
btree | text_pattern_ops | =(text,text)
hash | text_pattern_ops | =(text,text)
spgist | text_ops | =(text,text)
brin | text_minmax_ops | =(text,text)
gist | gist_text_ops | =(text,text)
(7 rows)
创建索引时如果我们不显示指定operator class,也可以看到索引对应的默认operator class。文本类型的operator class是我们通常所使用的。再一些场景下我们也需要设置特定的operator class。
当我们数据库里运行一个like查询。db上的collation不是大c,索引是不支持like操作的。
create index on users (email);
pgaweb=# explain select * from users where email like 'lukas@%';
query plan
----------------------------------------------------------------------------
seq scan on users (cost=10000000000.00..10000000001.26 rows=1 width=4463)
filter: ((email)::text ~~ 'lukas@%'::text)
(2 rows)
我们可以看到查询还是走全表扫描。如果我们进行引导,索引也能对这种场景生效:1)我们在数据库创建时指定collation为大c(也就是告诉数据库我们不想绑定具体语言的排序比较规则);2)使用文本模式操作符text_pattern_ops。
create index on users (email text_pattern_ops);
pgaweb=# explain select * from users where email like 'lukas@%';
query plan
--------------------------------------------------------------------------------------------
index scan using users_email_idx on users (cost=0.14..8.16 rows=1 width=4463)
index cond: (((email)::text ~>=~ 'lukas@'::text) and ((email)::text ~<~ 'lukasa'::text))
filter: ((email)::text ~~ 'lukas@%'::text)
(3 rows)
可以看到明确指定文本模式的操作符后,也能使用索引。
到这里我们知道了对列使用不同的索引类型以及操作符分类。接下来我们将讨论创建索引的一些其他方面。
使用多列属性
再创建索引的语句定义里面,还有一个基本的特性是使用多列选项。
create index on [table] ([column_a], [column_b]);
对于多列属性,不同索引类型的数据结构有不同的展现形式,有些索引类型比如hash索引、spgist索引是不支持多列属性的。
对于b-tree多列索引,列的顺序非常重要,如果部分查询语句只使用column_a,而大部分查询语句都使用column_b,那我们应该把column_b放在前面。如果我们不遵守这个规则,我们最终的查询需要跳过所有前导列。另一方面,如果我们使用gist索引,那这个顺序就无所谓了,我们可以以任意顺序指定。
还有一个值得讨论的问题:我们是创建单个多列索引合适还是创建多个单列索引更好?
create index on [table] ([column_a]);
create index on [table] ([column_b]);
--- or
create index on [table] ([column_a], [column_b]);
如果从单个查询语句的角度来看,大部分的答案是创建单个多列索引匹配度更高,单个多列索引也会比多个索引更快。但是如果我们是一个很大的工作负载,我们应该需要创建多个单列索引,同时我们也要意识到postgres在这种场景下也会做更多的工作,我们也应该通过explain命令或者来实际验证索引的选择情况。
使用函数及表达式索引
除了对指定列创建索引,我们也可以对列的表达式创建索引,比较典型的例子是email嵌套小写函数之后的比较。
select * from users where lower(email) = $1
如果我们简单的对email列创建索引,通过explain去观察,会发现并不会走索引,因为它并不匹配表达式。
我们知道lower函数是一个“immutable”属性的函数,所以我们可以创建函数表达式索引。
create index on users (lower(email));
使用表达式索引之后,我们的查询就可以使用索引了。注意并不是所有的函数都可用于创建表达式索引,比如使用now函数创建就会报错。
create index on users (now());
error: functions in index expression must be marked immutable
另外需要注意创建了表达式索引后,只有符合表达式的语句才能使用索引,如果只是引用独立的列,是不会走索引的。
运用where子句创建部分索引
我们再回到刚开始的介绍,我们介绍了两个节点,第一个opexpr节点已经介绍过了。我们再来看一下nulltest表达式。

我们的应用查询只需要返回没有被标记为删除的数据。根据我们的工作负载,有可能需要被忽略的记录(也就是打了删除标记的记录)非常多时,我们可以在创建索引时包含删除标记这一列,我们实际不需要关注有删除标记的数据。因为如果包含在索引条目里,那将是非常大的空间浪费。
postgres针对这种场景有更好的解决方式:使用部分索引,我们可以限制索引条目的数据行。当然如果没有这个限制,数据行不会保存到索引中,这会节省空间。在查询执行期间,在很多案例里部分索引可以节省大量时间花销的,因为计划生成器会做简单的检测,判定部分索引是否匹配,忽略不匹配的所有数据。
实际生产中,我们需要做的是在索引的定义里增加一个where子句。
create index on users(email) where deleted_at is null;
需要注意的是:面临下面两个问题时我们应该放弃使用部分索引。
第一:添加了部分索引的限制,意味着只有包含表达式的语句才可以使用索引。那如果我们既需要查询带限制条件,也需要不带限制条件,那我们可能要创建两个索引。
第二:添加大量的部分索引也会加重postgres计划生成器的花销,因为它需要做大量昂贵的分析来判定应该使用哪个索引。
使用include关键字创建covering index
下面我们介绍postgres索引的另外一个新特性,使用include关键字来创建覆盖索引,让更多场景可以使用index-only扫描。
首先我们来看下index扫描和index-only扫描的区别。index-only扫描可以直接从索引中获取数据,而不需要再从磁盘中去读取数据。
另外index-only只有当表最近做过vacuum操作才会起作用。不然postgres需要频繁的对每个索引条目去检查可见性,这样大多情况下postgres会优先选择index scan。
让我们来看下面两个例子,上边的语句能使用index-only scan,下边的语句不能,因为查询的列不一样。
create index on users (email, id);
=# explain select id from users where email = 'test@example.com';
query plan
-------------------------------------------------------------------------------------
index only scan using users_email_id_idx on users (cost=0.14..4.16 rows=1 width=4)
index cond: (email = 'test@example.com'::text)
(2 rows)
=# explain select id, fullname from users where email = 'test@example.com';
query plan
----------------------------------------------------------------------------------
index scan using users_email_id_idx on users (cost=0.14..8.15 rows=1 width=520)
index cond: ((email)::text = 'test@example.com'::text)
(2 rows)
如果想让下边的语句也能使用index-only scan,在我们创建多列索引时,可以把fullname列添加进去。
create index on users (email, id, fullname);
=# explain select id, fullname from users where email = 'test@example.com';
query plan
------------------------------------------------------------------------------------------------
index only scan using users_email_id_fullname_idx on users (cost=0.14..4.16 rows=1 width=520)
index cond: (email = 'test@example.com'::text)
(2 rows)
然而这样做却有一些小小的限制:比如我们要使用唯一索引、索引可能会发生膨胀。
此时使用include关键字会是一个更好的选择:
create index on users (email, id) include (fullname);
这会让我们的索引更加轻量,也不用担心唯一约束的问题,同时include添加的列也很明确,就是为了支持index only scan。
这个特性也需要非常节俭的去使用:因为随着我们添加更多的数据到索引中,索引的值也会非常的大,这也会产生问题,添加太多的列到include子句中其实并不是一个很好的方法。
生产环境安全地添加及删除索引
生产环境下,如果我们不使用concurrently参数,则会获取exclusive lock,会阻塞表的读写操作。postgres能够在不获取任何锁的情况下添加索引。它使用concurrently参数来执行此操作。
create index concurrently on users (email) where deleted_at is null;
删除索引操作也是使用同样的关键字。
小结
通过本文我们应该基本了解与索引相关的操作符和操作符类,了解这些概念对于复杂查询创建最佳索引至关重要。我们还研究了create index命令的一些补充功能特性,这些特性为postgre判定使用哪个索引非常关键。
本文实际上还有一些方面没有讨论:比如使用特定表空间创建索引,使用索引存储参数(尤其是对gin索引类型特别有用!)以及指定列的排序顺序。作者也非常鼓励大家通过postgres文档进一步阅读本文的一些概念。
保持联系
从2019年12月开始写第一篇文章,分享的初心一直在坚持,本人现在组建了一个pg乐知乐享交流群,欢迎关注我文章的小伙伴进群吹牛唠嗑,交流技术,互赞文章。

如果群二维码失效可以加我微信。