

目录

查询优化存储
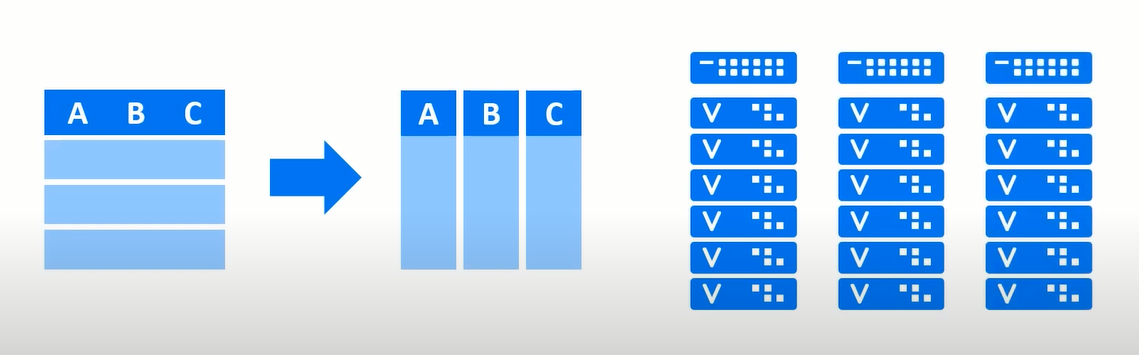
列式存储体系架构是的核心,实际上vertica是世界上第一个列式存储数据库,它是在2005年发表的学术论文c-store的基础上推出的适用于大规模并行处理场景的真正意义上的分布式数据库。
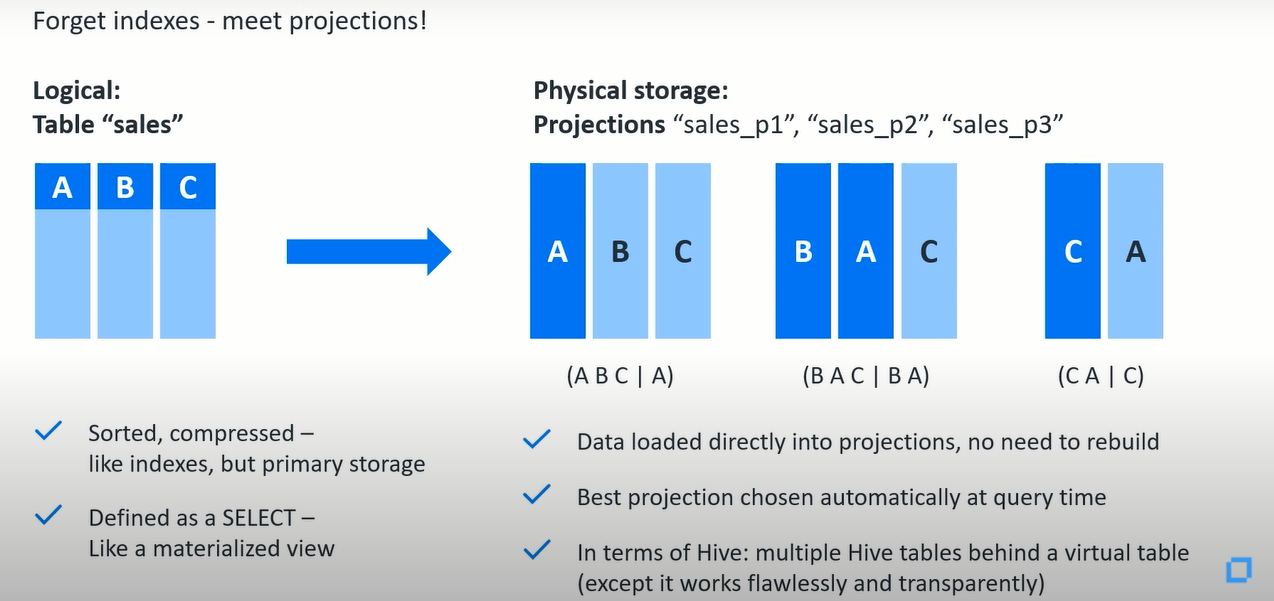
上面是vertica的sql专家和hadoop专家解释列式存储是如何工作的一个原理图,左边的表“sales”是表的逻辑结构(按列存储),包含三个列a,b和c。右边的三个投影“sales_p1”,“sales_p2”和“sales_p3”分别对应下面的三个投影示意图,它们是实际的物理存储结构。
投影实际上是一组经过排序和压缩的存储在磁盘上的一个文件集合,这个投影类似于聚集列索引(它和表的存储有很大的不同),您可以认为它是只存储了索引结构。投影的定义类似于带有一个as select子句的物化视图,正如您在上面的图中所看到的三个投影,“create projection as select a, b, c from sales order by a;”,“create projection as select b, a, c from sales order by b, a;”,“create projection as select c, a from sales order by c;”。
您可以指定更多选项,而不仅仅是列和排序顺序,但是这些是最低需求。它和物化视图不一样的是您不必刷新视图,当您在表中插入数据时也没有必要更新索引,表的数据在加载过程中会立刻转换为投影。
如果您熟悉hive,您很可能现在已经意识到投影非常像hive里的表,可以将其视为在虚拟表的背后有多个hive表,以便您可以在不同类型查询的流水线聚合中获得合并联接。

自动数据库设计
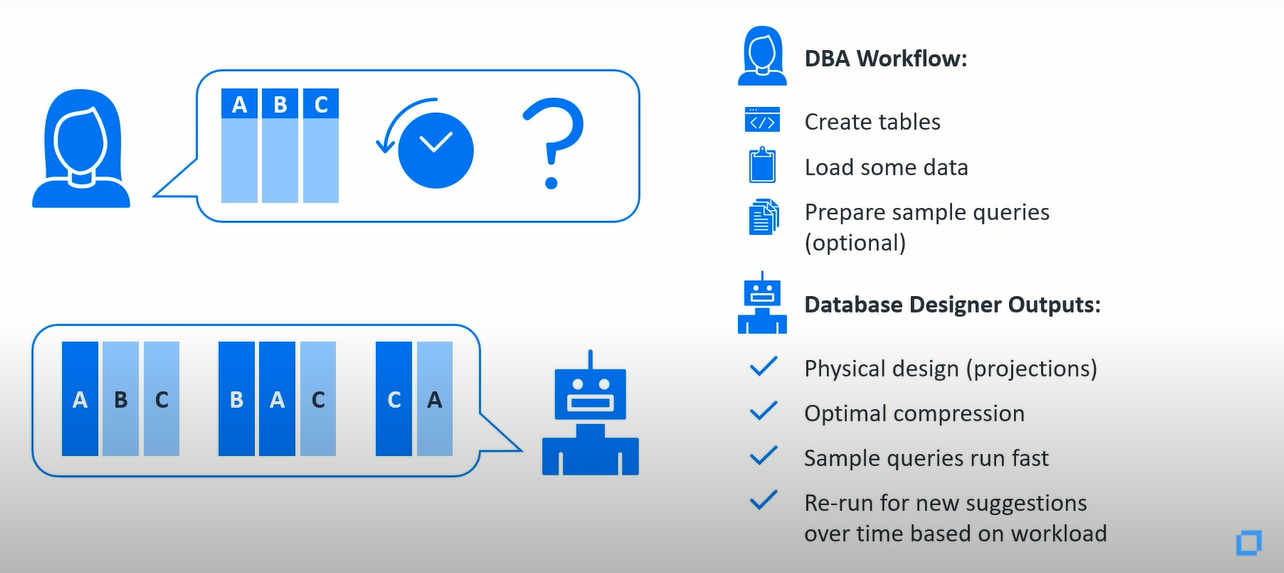
在大多数情况下,最佳压缩排序和分布式投影的规则很简单,它可以直接从查询中导出。所以我们为什么要花费时间手动处理它呢?通过一种称为数据库设计器的特殊工具能够自动创建投影,这种工具根据您的工作负载自动为您建议行存储中的索引。
例如,我作为销售工程师做poc测试的典型工作流程是接收我们的oracle或microsoft数据库的备份以及一些查询,我需要对它们的表现进行基准测试,而且我通常必须在一周内完成所有工作。为了防止积压工作的增加,所以我要做的是将oracle或microsoft的创建表的语句转换为vertica数据库的sql语句。
首先,使用自动转换器从源数据库加载一些数据到vertica数据库,然后准备我需要的示例查询优化,最后我将所有这些都输入到数据库设计器中。这通常是一个物理设计,它设计所有的创建投影语句。数据被优化压缩以后,示例查询会运行得很快,当工作负载发生变化时,稍后它可以增量运行。
现在,数据库设计器从一开始就做了一个很好的工作。很明显地,在大多数情况下,我给它一个b 或 a-,如果您知道了编码压缩的来龙去脉和交叉执行计划等,您总是可以手动地进一步优化。

在列存储中准实时分析
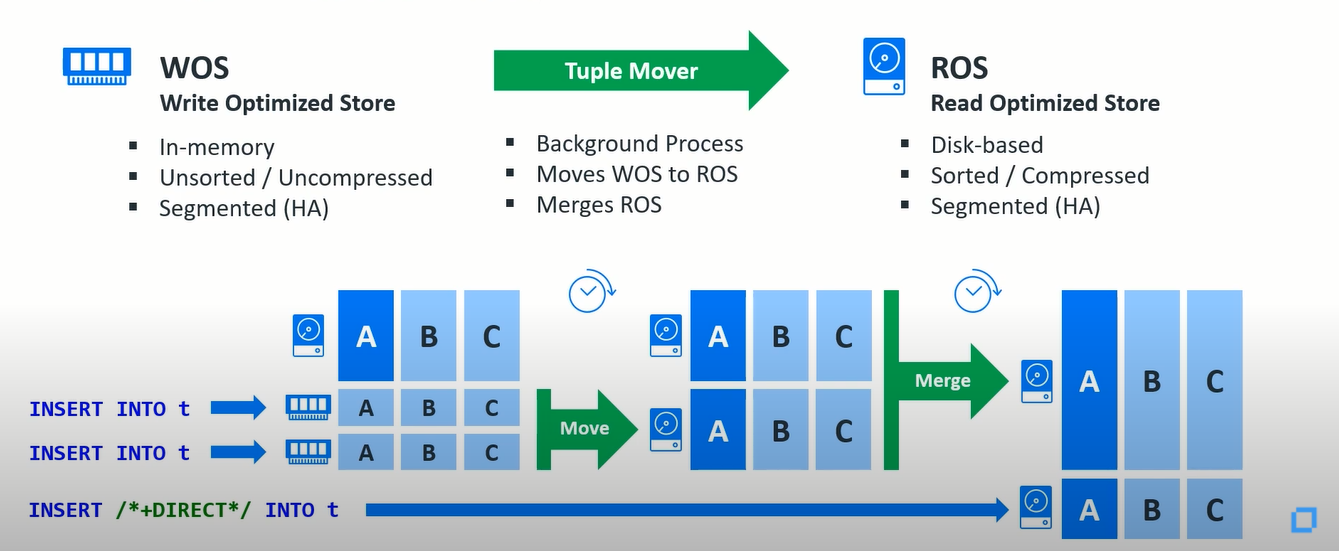
列式存储是存储格式,例如,hadoop中使用的parquet文件格式非常适合批量读取数据和处理数据。事实上,作为原生列式存储的vertica字面意思叫做ros或者读优化存储,但是如果你需要写数据(插入一些行或更新某些内容或实时地流数据)并立即查询,这对于行存储(例如,oracle或postgresql)来说从来都不是问题,它们是最初针对写入更新进行了优化,但是当您按行存储时被迫使用诸如索引之类的依赖来解决读取性能问题。所以读取最好的选择是列存储,而写入最好的选择是行存储或内存存储,这就是vertica数据库具有混合存储体系架构的原因所在。
我们有一个基于磁盘的列式读取优化存储,我们有一个内存写入优化存储,这是任何插入和更新的默认选项。这让vertica能够支持实时查询这个核心功能,因为它的唯一缺点是能够接受几行数据的插入或更新,并在事务完成以后,内存中的数据只需几毫秒即可用于读取到磁盘,然后在查询时进行合并,通常在几分钟后的某个时间点它通过后台进程刷新到磁盘,形成一个新的排序和压缩的存储容器,然后在通过后台进程再次合并存储容器。如果您批量加载并且不想浪费内存,则可以将数据直接写入磁盘。因为在这种规模上进行实时分析的任何其他选择将涉及多种产品的临时混合架构。
有很多博客文章解释到,我们如何处理hive的变化量文件,然后将其与hive查询结合起来,这些方法都非常复杂,就是插入、更新和提交。让更少的人做更少的工作是明智的,这一切都是开箱即用的,更重要的是开箱即用,有一流的企业支持。

自动数据集市

多表联接是一个性能杀手,请确保您有合并连接和列式存储之类的功能,让事情变得更好。但是在白天的工作时间之内到了快要下班的时候,你仍然在获取来自多个不同地方的数据,并且很好地将它们连接在一起,这显然需要时间,而且每个查询都需要这样做。这就是为什么数据集市长期以来一直是转到“需要频繁查询数据的选项”以查看数据。当数据发生变化时,需要刷新到数据集市,这可能会造成大量耗时的计算,除非您只刷新已经被更改的那一部分,但是也存在其他问题。
考虑到这一点,多表联接已经不是一个微不足道的杀手了,这项功能已经使用了几年。为了让大多数的数据使用场景更加简单,是否可以将计算列添加到可以从另一个表中查找值的表中,或者是您可以使用任何其他表达式来合并一些表,这些表包括或不包括每行返回任何一个值。如果数据集市只是简单地从维度表中查找具有列的实际表,您可以添加从该维度表中选择的值,然后将新数据插入到实际表中,然后单击“新建”自动填充值,更新维度表并刷新单个列。它真得是非常快,因为您知道列存储更新实际表中的两个键仅在最后一天刷新一列,或者以更快的速度对数据进行分区。
另外,由于数据和计算列不是独立的,所以它是免费的不计入许可容量,您只需为此类数据集市的已使用部分付费。

多维数据集的预聚合

当我们在上一个特性中讨论数据集市的主题时,请考虑一下,您正在获取的数据容量每天都在tb级以上。您会怎么做?
- 从磁盘读取千兆字节的数据并为每个查询冗余聚合?
- 您是否使用聚合数据创建单独的表并使用复杂的逻辑对其进行更新?
- 您是否在数据库前放置了一个olap引擎来聚合您的数据从而增加了硬件的成本和复杂性?
不,您可以向表中添加投影(projection)功能。它按您需要的所有产品分组并汇总您需要的所有指标,这就是所谓的实时聚合投影,然后与所有其他投影一起刷新,每次提交。
现在您不需要增加逻辑的复杂性或硬件成本和附加软件,将为您进行内存聚合,现在一切都来了!开箱即用,更重要的是开箱即用!!!
以上就是这篇文章的所有内容,欢迎您在文章底部的评论区留下反馈意见。在下一篇文章中我将介绍vertica数据库脱颖而出的另外5个特性,敬请期待!!!