

目录
前言
desc v$iostat_function
name null? type
----------------------------------------------------------------- -------- --------------------------------------------
function_id number
function_name varchar2(18)
small_read_megabytes number
small_write_megabytes number
large_read_megabytes number
large_write_megabytes number
small_read_reqs number
small_write_reqs number
large_read_reqs number
large_write_reqs number
number_of_waits number
wait_time number其中,我们使用sql语句查询v$iostat_function中的function_id和function_name后发现oracle的io按function分类总共有14个不同的类别,请看下面的查询语句和结果:
set pagesize 30
column function_name for a18
select function_id, function_name from v$iostat_function order by 1;
function_id function_name
----------- ------------------------------------
0 rman
1 dbwr
2 lgwr
3 arch
4 xdb
5 streams aq
6 data pump
7 recovery
8 buffer cache reads
9 direct reads
10 direct writes
11 smart scan
12 archive manager
13 others
14 rows selected.因此,我们需要从两个维度(最近1分钟和最近1小时)可视化我们所提到的14个类别(在图表中也可将其称作“图例”)的io(io分为mbps和iops两类,即每秒的io读写容量和每秒的io读写请求)情况。其中,最近1分钟的数据保存在动态性能视图里,最近1小时的数据保存在动态性能视图上。所以两个维度和两个io类别的互相组合,我们将要使用四个sql查询来实现我们的业务需求。
将oracle数据库的mbps&iops by function查询导入vertica数据库
- 将oracle数据库的mbps&iops by function查询保存为csv文件
- 将所有csv文件上传到vertica服务器的/home/dbadmin目录下
- 用vsql客户端命令连接到vertica数据库
- 在vertica数据库中创建相关的mbps&iops by function表
- 使用copy命令将csv文件导入刚创建的表中
将oracle数据库的mbps&iops by function查询保存为csv文件
和前两篇文章的方法相同,我们在sql develooper中分别以脚本方式运行下面的四个sql查询并将其保存为csv文件。具体的操作步骤有些繁琐,所以这里只贴出sql代码,依次(首先,最近1分钟和最近1小时的mbps;其次,最近1分钟和最近1小时的iops)如下所示:
-- converting rows to columns based on i/o megabytes per second in last 1 minute.
-- vertical axis name: mb per sec
set feedback off;
set sqlformat csv;
set linesize 200
set pagesize 10
column sample_time format a11
column function_name format a18
column io_mbps format 999,999,999.999
alter session set nls_date_format = 'yyyy-mm-dd hh24:mi:ss';
with ifm as
(
select to_char(end_time, 'yyyy-mm-dd hh24:mi:ss') sample_time
, function_name
, round((small_read_mbps small_write_mbps large_read_mbps large_write_mbps), 3) io_mbps
from v$iofuncmetric
)
select * from ifm
pivot ( max(io_mbps)
for function_name in
( 'buffer cache reads' as "buffer cache reads"
, 'direct reads' as "direct reads"
, 'direct writes' as "direct writes"
, 'dbwr' as "dbwr"
, 'lgwr' as "lgwr"
, 'arch' as "arch"
, 'rman' as "rman"
, 'recovery' as "recovery"
, 'data pump' as "data pump"
, 'streams aq' as "streams aq"
, 'xdb' as "xdb"
, 'others' as "others"
, 'archive manager' as "archive manager"
, 'smart scan' as "smart scan"
)
)
order by sample_time
;-- converting rows to columns based on i/o megabytes per second in last 1 hour (interval by each minute).
-- vertical axis name: mb per sec
set feedback off;
set sqlformat csv;
set linesize 200
set pagesize 80
column sample_time format a11
column function_name format a18
column io_mbps format 999,999,999.999
alter session set nls_date_format = 'yyyy-mm-dd hh24:mi:ss';
with ifmh as
(
select to_char(end_time, 'yyyy-mm-dd hh24:mi:ss') sample_time
, function_name
, round((small_read_mbps small_write_mbps large_read_mbps large_write_mbps), 3) io_mbps
from v$iofuncmetric_history
)
select * from ifmh
pivot ( max(io_mbps)
for function_name in
( 'buffer cache reads' as "buffer cache reads"
, 'direct reads' as "direct reads"
, 'direct writes' as "direct writes"
, 'dbwr' as "dbwr"
, 'lgwr' as "lgwr"
, 'arch' as "arch"
, 'rman' as "rman"
, 'recovery' as "recovery"
, 'data pump' as "data pump"
, 'streams aq' as "streams aq"
, 'xdb' as "xdb"
, 'others' as "others"
, 'archive manager' as "archive manager"
, 'smart scan' as "smart scan"
)
)
order by sample_time
;-- converting rows to columns based on i/o requests per second in last 1 minute.
-- horizontal axis name: i/o per sec
set feedback off;
set sqlformat csv;
set linesize 200
set pagesize 10
column sample_time format a11
column function_name format a18
column iops format 999,999,999.999
alter session set nls_date_format = 'yyyy-mm-dd hh24:mi:ss';
with ifm as
(
select to_char(end_time, 'yyyy-mm-dd hh24:mi:ss') sample_time
, function_name
, round((small_read_iops small_write_iops large_read_iops large_write_iops), 3) iops
from v$iofuncmetric
)
select * from ifm
pivot ( max(iops)
for function_name in
( 'buffer cache reads' as "buffer cache reads"
, 'direct reads' as "direct reads"
, 'direct writes' as "direct writes"
, 'dbwr' as "dbwr"
, 'lgwr' as "lgwr"
, 'arch' as "arch"
, 'rman' as "rman"
, 'recovery' as "recovery"
, 'data pump' as "data pump"
, 'streams aq' as "streams aq"
, 'xdb' as "xdb"
, 'others' as "others"
, 'archive manager' as "archive manager"
, 'smart scan' as "smart scan"
)
)
order by sample_time
;-- converting rows to columns based on i/o requests per second in last 1 hour (interval by each minute).
-- horizontal axis name: i/o per sec
set feedback off;
set sqlformat csv;
set linesize 200
set pagesize 80
column sample_time format a11
column function_name format a18
column iops format 999,999,999.999
alter session set nls_date_format = 'yyyy-mm-dd hh24:mi:ss';
with ifmh as
(
select to_char(end_time, 'yyyy-mm-dd hh24:mi:ss') sample_time
, function_name
, round((small_read_iops small_write_iops large_read_iops large_write_iops), 3) iops
from v$iofuncmetric_history
)
select * from ifmh
pivot ( max(iops)
for function_name in
( 'buffer cache reads' as "buffer cache reads"
, 'direct reads' as "direct reads"
, 'direct writes' as "direct writes"
, 'dbwr' as "dbwr"
, 'lgwr' as "lgwr"
, 'arch' as "arch"
, 'rman' as "rman"
, 'recovery' as "recovery"
, 'data pump' as "data pump"
, 'streams aq' as "streams aq"
, 'xdb' as "xdb"
, 'others' as "others"
, 'archive manager' as "archive manager"
, 'smart scan' as "smart scan"
)
)
order by sample_time
;由于csv文件的内容过多,所以我把它们分别上传到了我的,您可以查看这4个文件:,,和。
将所有csv文件上传到vertica服务器的/home/dbadmin目录下
这里,省略具体的上传步骤和相关授权操作,最终的上传结果如下所示(用“<<==”标明):
[dbadmin@test ~]$ ls -lrht
total 184k
drwxr-xr-x 5 dbadmin verticadba 134 dec 15 14:06 vdb_oracle_perf
......
-rw-r--r-- 1 dbadmin verticadba 225 dec 23 10:54 crtc_oracle_io_mbps_in_last_1_minute.csv <<==
-rw-r--r-- 1 dbadmin verticadba 3.0k dec 23 10:56 crtc_oracle_io_mbps_in_last_1_hour.csv <<==
-rw-r--r-- 1 dbadmin verticadba 233 dec 23 10:57 crtc_oracle_iops_in_last_1_minute.csv <<==
-rw-r--r-- 1 dbadmin verticadba 3.6k dec 23 10:59 crtc_oracle_iops_in_last_1_hour.csv <<==用vsql客户端命令连接到vertica数据库
用linux命令su切换vertica数据库服务器的root用户到dbadmin用户,然后用vsql命令进行连接,下面是具体的操作过程:
[root@test ~]# su - dbadmin
[dbadmin@test ~]$
[dbadmin@test ~]$ /opt/vertica/bin/vsql -h 127.0.0.1 vdb_oracle_perf dbadmin
password:
welcome to vsql, the vertica analytic database interactive terminal.
type: \h or \? for help with vsql commands
\g or terminate with semicolon to execute query
\q to quit
vdb_oracle_perf=> 在vertica数据库中创建相关的mbps&iops by function表
在public的schema下,分别创建表crtc_oracle_io_mbps_in_last_1_minute,crtc_oracle_io_mbps_in_last_1_hour,crtc_oracle_iops_in_last_1_minute和crtc_oracle_iops_in_last_1_hour。
vdb_oracle_perf=>
vdb_oracle_perf=> create table public.crtc_oracle_io_mbps_in_last_1_minute
vdb_oracle_perf-> (sample_time timestamp,
vdb_oracle_perf(> buffer_cache_reads number(12,3),
vdb_oracle_perf(> direct_reads number(12,3),
vdb_oracle_perf(> direct_writes number(12,3),
vdb_oracle_perf(> dbwr number(12,3),
vdb_oracle_perf(> lgwr number(12,3),
vdb_oracle_perf(> arch number(12,3),
vdb_oracle_perf(> rman number(12,3),
vdb_oracle_perf(> recovery number(12,3),
vdb_oracle_perf(> data_pump number(12,3),
vdb_oracle_perf(> streams_aq number(12,3),
vdb_oracle_perf(> xdb number(12,3),
vdb_oracle_perf(> others number(12,3),
vdb_oracle_perf(> archive_manager number(12,3),
vdb_oracle_perf(> smart_scan number(12,3)
vdb_oracle_perf(> );
create table
vdb_oracle_perf=> vdb_oracle_perf=>
vdb_oracle_perf=> create table public.crtc_oracle_io_mbps_in_last_1_hour
vdb_oracle_perf-> (sample_time timestamp,
vdb_oracle_perf(> buffer_cache_reads number(12,3),
vdb_oracle_perf(> direct_reads number(12,3),
vdb_oracle_perf(> direct_writes number(12,3),
vdb_oracle_perf(> dbwr number(12,3),
vdb_oracle_perf(> lgwr number(12,3),
vdb_oracle_perf(> arch number(12,3),
vdb_oracle_perf(> rman number(12,3),
vdb_oracle_perf(> recovery number(12,3),
vdb_oracle_perf(> data_pump number(12,3),
vdb_oracle_perf(> streams_aq number(12,3),
vdb_oracle_perf(> xdb number(12,3),
vdb_oracle_perf(> others number(12,3),
vdb_oracle_perf(> archive_manager number(12,3),
vdb_oracle_perf(> smart_scan number(12,3)
vdb_oracle_perf(> );
create table
vdb_oracle_perf=> vdb_oracle_perf=>
vdb_oracle_perf=> create table public.crtc_oracle_iops_in_last_1_minute
vdb_oracle_perf-> (sample_time timestamp,
vdb_oracle_perf(> buffer_cache_reads number(12,3),
vdb_oracle_perf(> direct_reads number(12,3),
vdb_oracle_perf(> direct_writes number(12,3),
vdb_oracle_perf(> dbwr number(12,3),
vdb_oracle_perf(> lgwr number(12,3),
vdb_oracle_perf(> arch number(12,3),
vdb_oracle_perf(> rman number(12,3),
vdb_oracle_perf(> recovery number(12,3),
vdb_oracle_perf(> data_pump number(12,3),
vdb_oracle_perf(> streams_aq number(12,3),
vdb_oracle_perf(> xdb number(12,3),
vdb_oracle_perf(> others number(12,3),
vdb_oracle_perf(> archive_manager number(12,3),
vdb_oracle_perf(> smart_scan number(12,3)
vdb_oracle_perf(> );
create table
vdb_oracle_perf=> vdb_oracle_perf=>
vdb_oracle_perf=> create table public.crtc_oracle_iops_in_last_1_hour
vdb_oracle_perf-> (sample_time timestamp,
vdb_oracle_perf(> buffer_cache_reads number(12,3),
vdb_oracle_perf(> direct_reads number(12,3),
vdb_oracle_perf(> direct_writes number(12,3),
vdb_oracle_perf(> dbwr number(12,3),
vdb_oracle_perf(> lgwr number(12,3),
vdb_oracle_perf(> arch number(12,3),
vdb_oracle_perf(> rman number(12,3),
vdb_oracle_perf(> recovery number(12,3),
vdb_oracle_perf(> data_pump number(12,3),
vdb_oracle_perf(> streams_aq number(12,3),
vdb_oracle_perf(> xdb number(12,3),
vdb_oracle_perf(> others number(12,3),
vdb_oracle_perf(> archive_manager number(12,3),
vdb_oracle_perf(> smart_scan number(12,3)
vdb_oracle_perf(> );
create table
vdb_oracle_perf=> 使用copy命令将csv文件导入刚创建的表中
在上一步操作中,我们已经创建成功了4个表。现在我们用copy命令将上传到vertica数据库服务器的4个csv文件分别导入到那4个表中。操作步骤依次为:
vdb_oracle_perf=>
vdb_oracle_perf=> copy public.crtc_oracle_io_mbps_in_last_1_minute from '/home/dbadmin/crtc_oracle_io_mbps_in_last_1_minute.csv' exceptions '/home/dbadmin/imp_io_mbps_1.log' delimiter as ',';
notice 7850: in a multi-threaded load, rejected record data may be written to additional files
hint: exceptions may be written to files [/home/dbadmin/imp_io_mbps_1.log], [/home/dbadmin/imp_io_mbps_1.log.1], etc
rows loaded
-------------
1
(1 row)vdb_oracle_perf=>
vdb_oracle_perf=> copy public.crtc_oracle_io_mbps_in_last_1_hour from '/home/dbadmin/crtc_oracle_io_mbps_in_last_1_hour.csv' exceptions '/home/dbadmin/imp_io_mbps_2.log' delimiter as ',';
notice 7850: in a multi-threaded load, rejected record data may be written to additional files
hint: exceptions may be written to files [/home/dbadmin/imp_io_mbps_2.log], [/home/dbadmin/imp_io_mbps_2.log.1], etc
rows loaded
-------------
61
(1 row)vdb_oracle_perf=>
vdb_oracle_perf=> copy public.crtc_oracle_iops_in_last_1_minute from '/home/dbadmin/crtc_oracle_iops_in_last_1_minute.csv' exceptions '/home/dbadmin/imp_iops_1.log' delimiter as ',';
notice 7850: in a multi-threaded load, rejected record data may be written to additional files
hint: exceptions may be written to files [/home/dbadmin/imp_iops_1.log], [/home/dbadmin/imp_iops_1.log.1], etc
rows loaded
-------------
1
(1 row)vdb_oracle_perf=>
vdb_oracle_perf=> copy public.crtc_oracle_iops_in_last_1_hour from '/home/dbadmin/crtc_oracle_iops_in_last_1_hour.csv' exceptions '/home/dbadmin/imp_iops_2.log' delimiter as ',';
notice 7850: in a multi-threaded load, rejected record data may be written to additional files
hint: exceptions may be written to files [/home/dbadmin/imp_iops_2.log], [/home/dbadmin/imp_iops_2.log.1], etc
rows loaded
-------------
61
(1 row)
vdb_oracle_perf=> 用tableau可视化vertica数据库的表
- 按function name分类的最近1分钟的io mbps
- 按function name分类的最近1小时的io mbps
- 按function name分类的最近1分钟的iops
- 按function name分类的最近1小时的iops
按function name分类的最近1分钟的io mbps
打开tableau desktop工具,然后连接到vertica数据库,选择schema为public,然后将表crtc_oracle_io_mbps_in_last_1_minute拖动到指定位置,点击底部的工作表,进入工作表编辑区。详见下面两个屏幕截图:
接着,将工作区中左侧“数据”标签卡内“表”的度量名称sample time用鼠标拖到位于工作区上方标签名为“列”的右侧“标签框”中,同样的方法,将“表”的14个度量值分别拖到位于工作区上方标签名为“行”的右侧“标签框”中,屏幕截图如下所示:

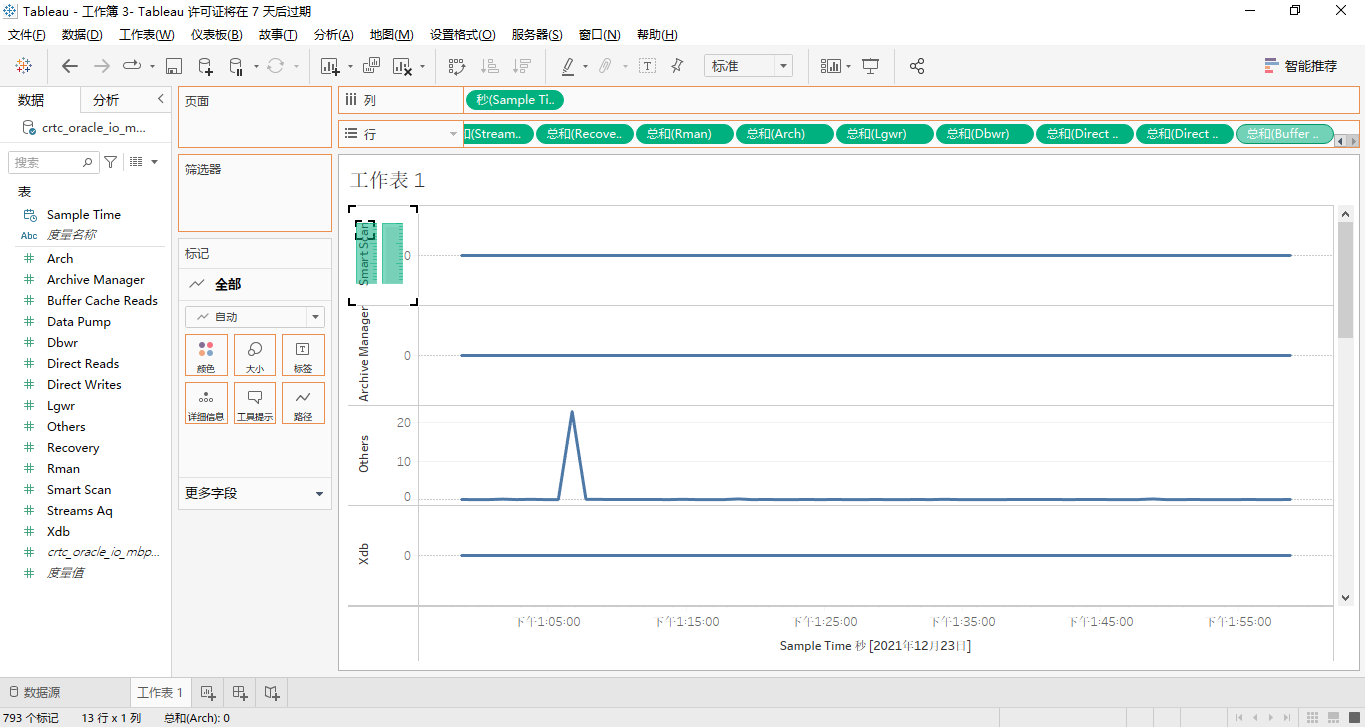
然后将标签名为“行”内的其余13个度量依次用鼠标拖动到工作区中部的图表纵坐标轴名称为“smart scan”的区域,也就是将这14个度量都合并到一个纵坐标轴上,顺便修改图表的名称和纵坐标轴名称,最终的效果如图所示:
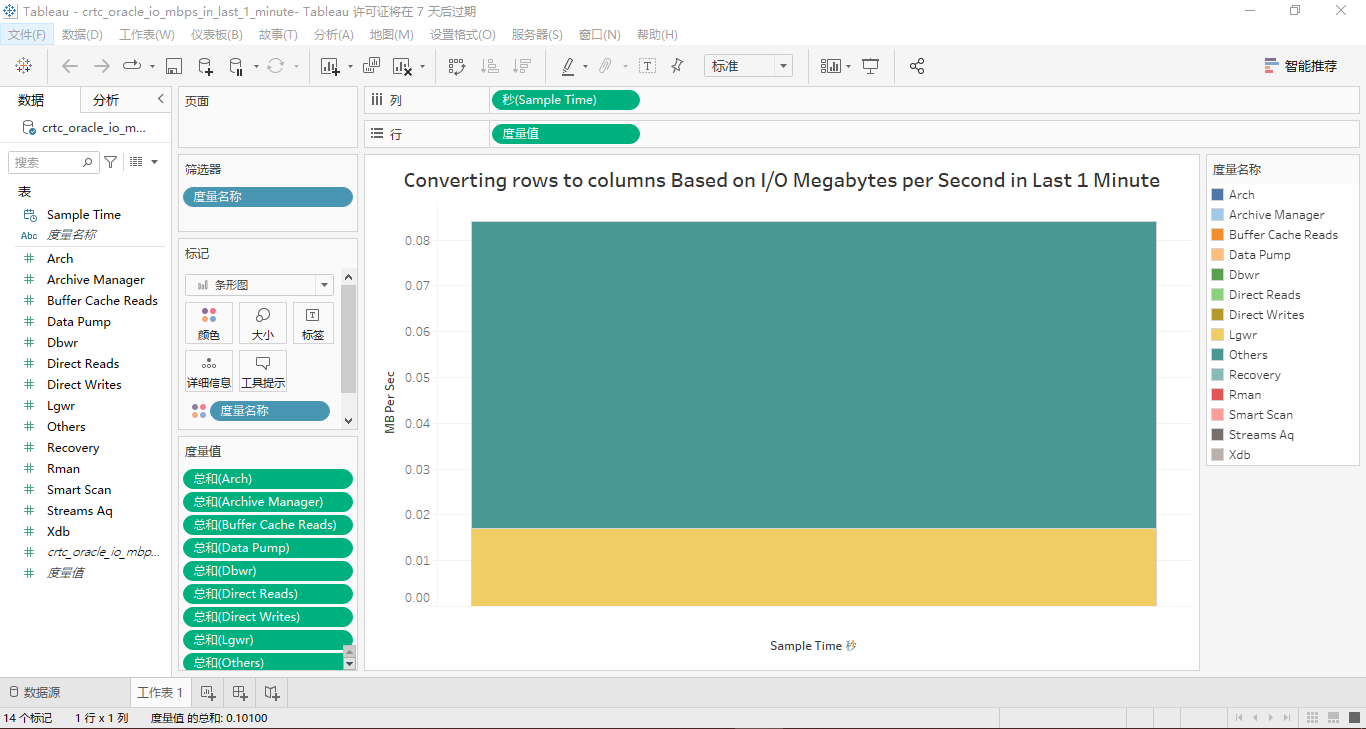
因为每个度量在最近1分钟的数据只有一个值显示,显然,所有度量在纵坐标轴上显示的话,这个柱状条形图看起来很臃肿!因此,将这个14个度量换到横坐标轴上,详见下面的两个屏幕截图:
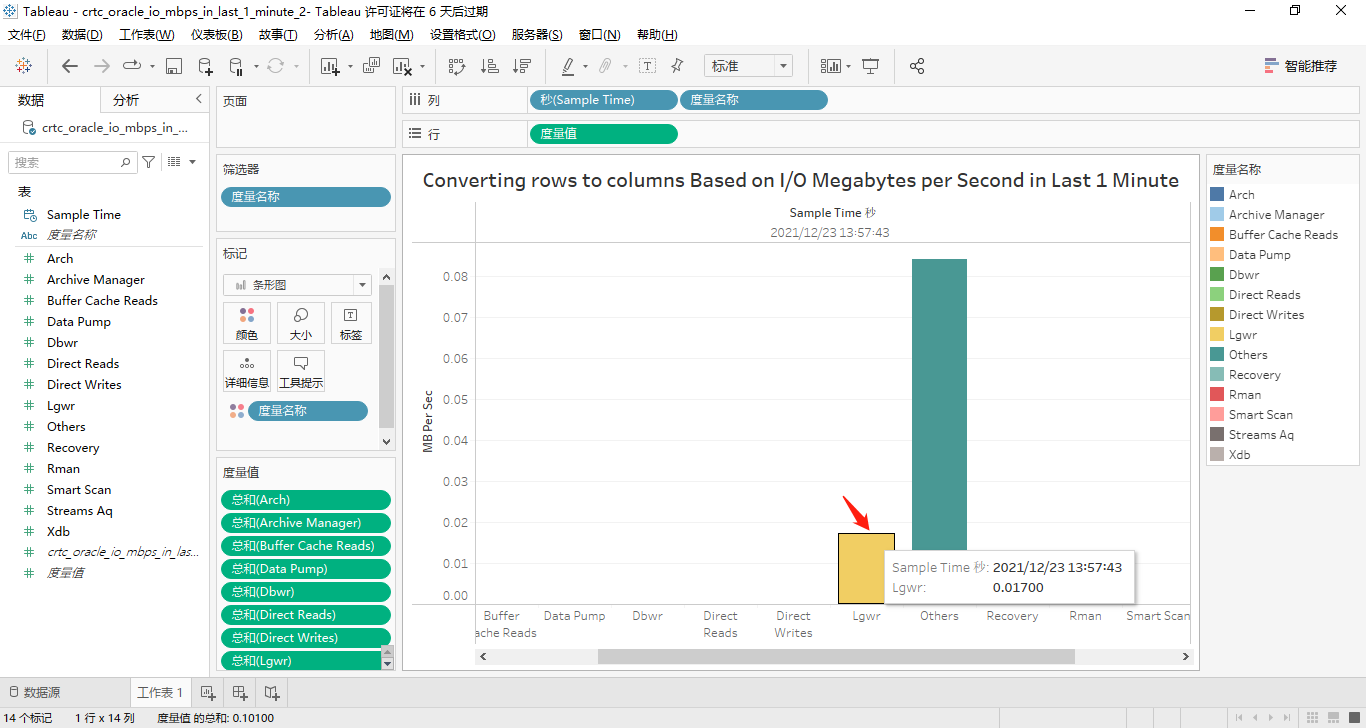

正如我们所看到的,只有lgwr和others这两个度量有取值。
按function name分类的最近1小时的io mbps
因为上一环节我们已经非常详细地说明了在tablesau desktop中可视化表crtc_oracle_io_mbps_in_last_1_minute的每一步骤,所以在这里,我们进行快速地操作,见如下屏幕截图。
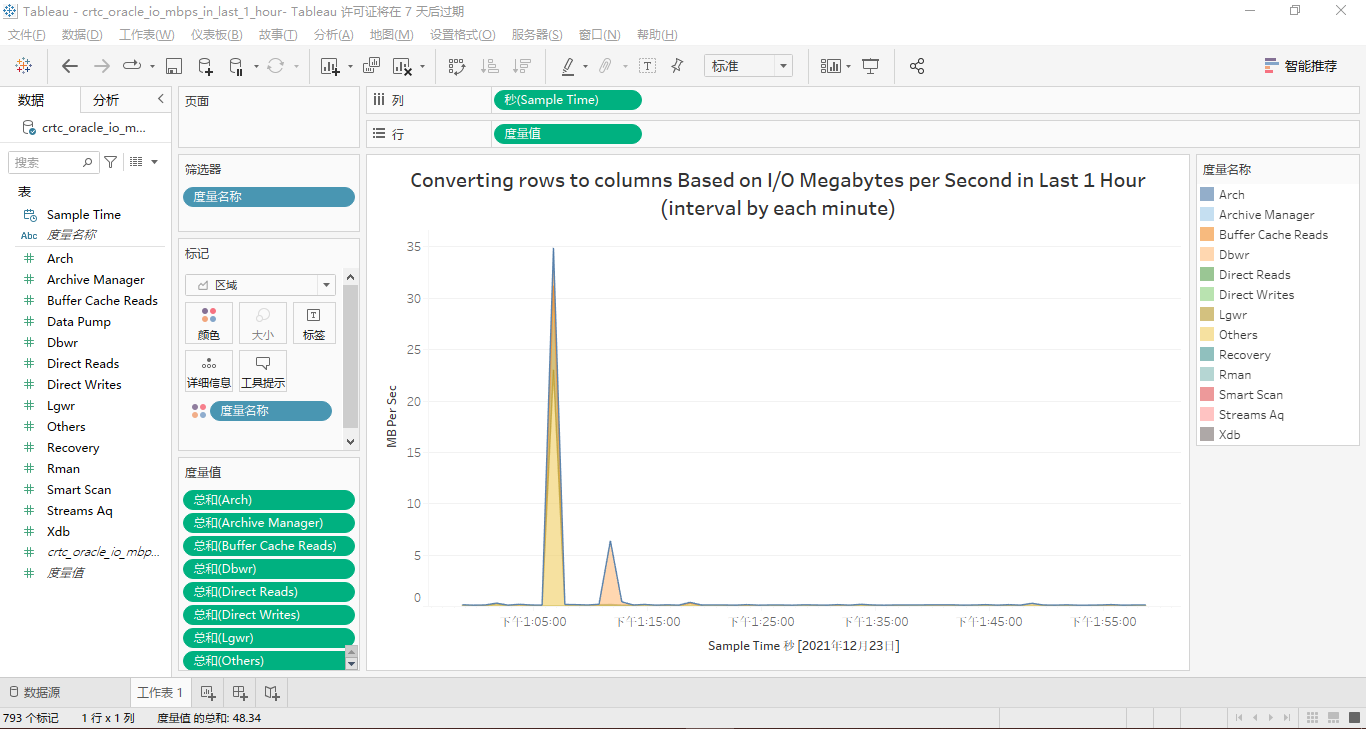
最终,按function name分类的最近1小时的io mbps的面积堆叠图是这样的:
按function name分类的最近1分钟的iops
这14个度量均在纵坐标轴上显示的条形柱状图为:

接着,我们将那14个度量都转换到横坐标轴上显示。其中,有取值的4个度量对应的屏幕截图分别如下所示:
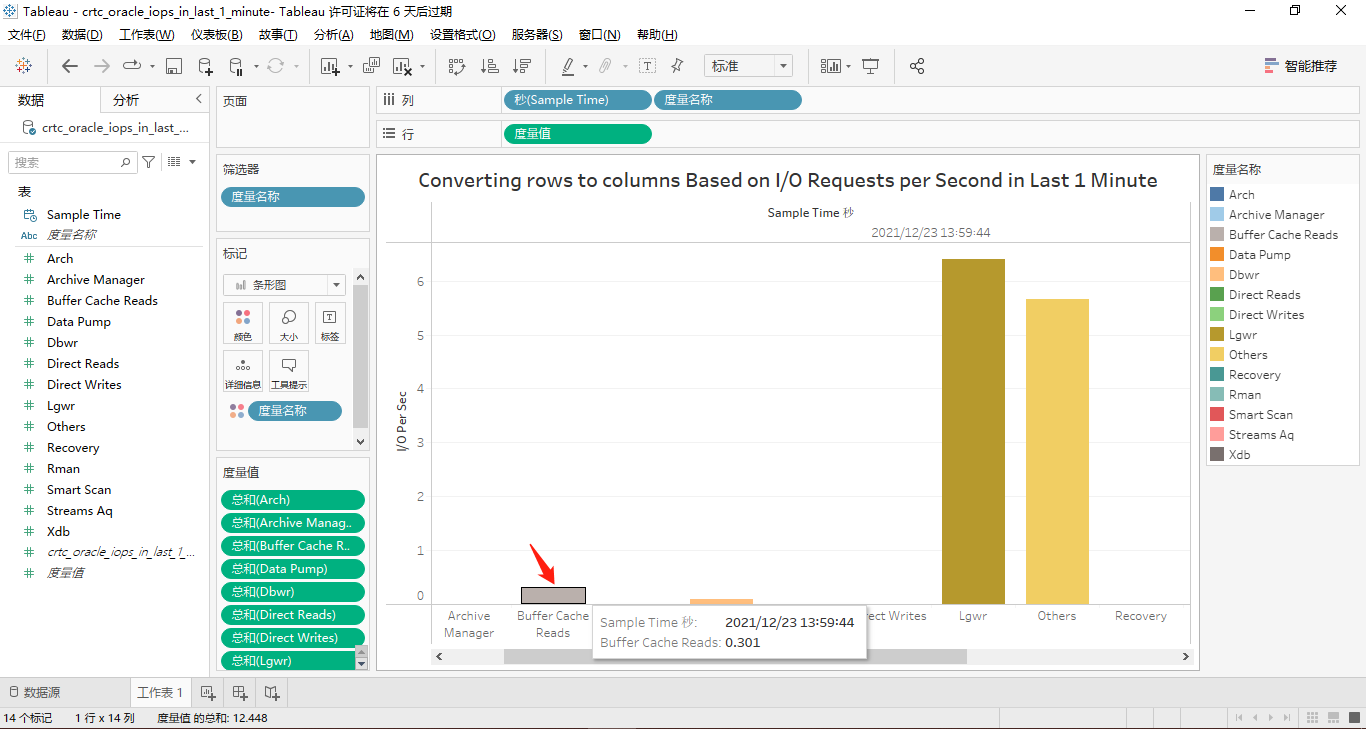
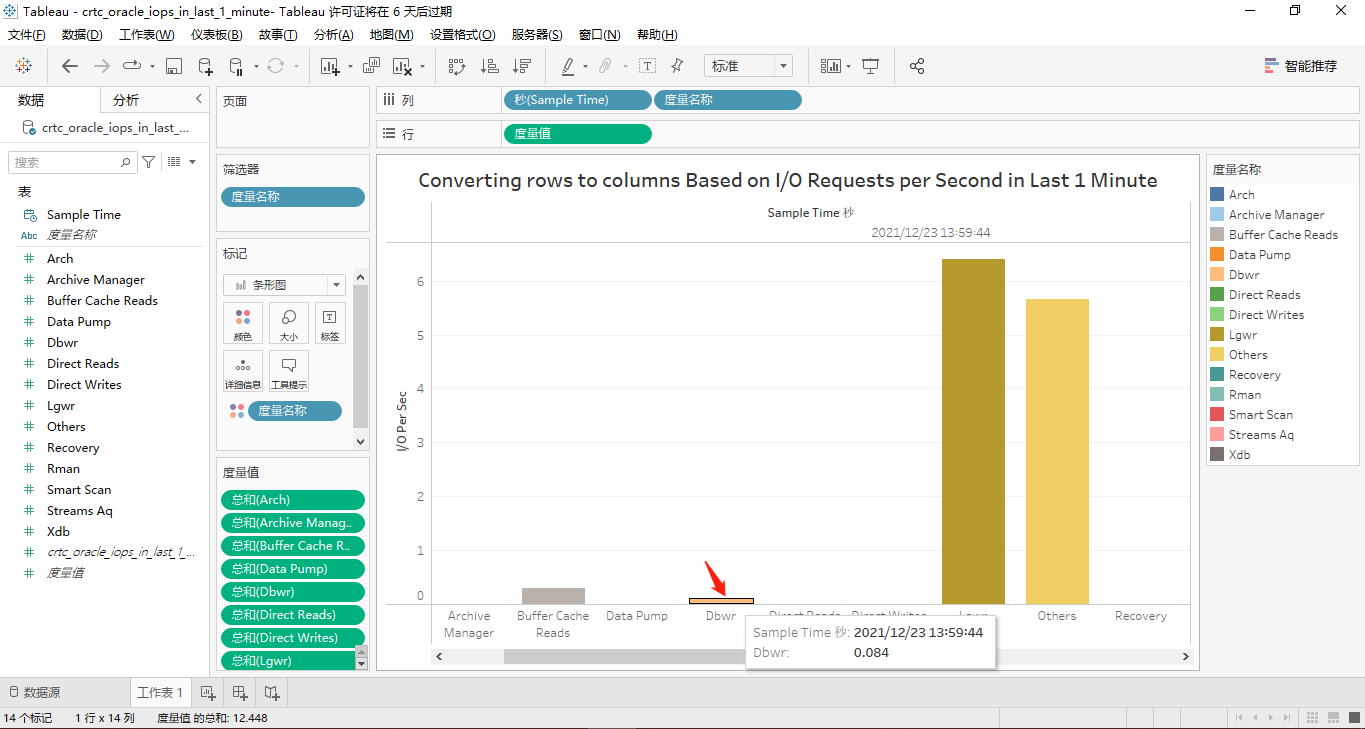
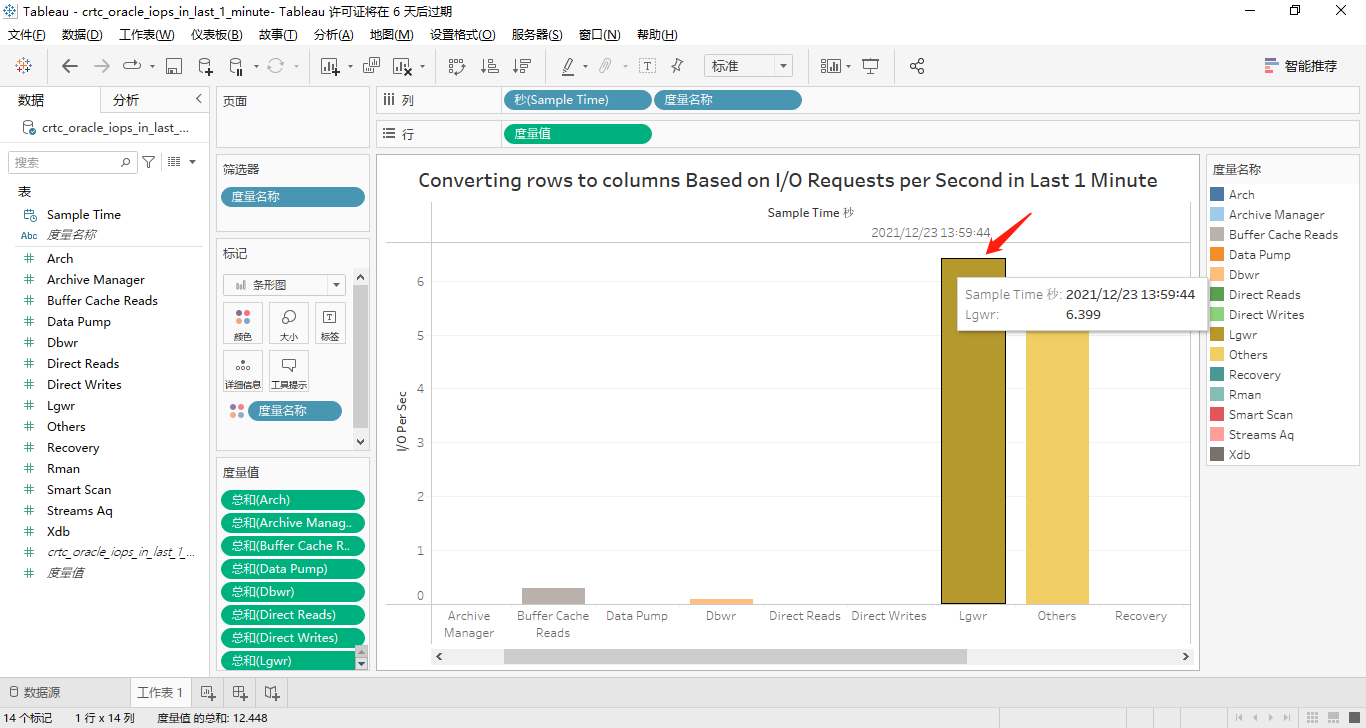
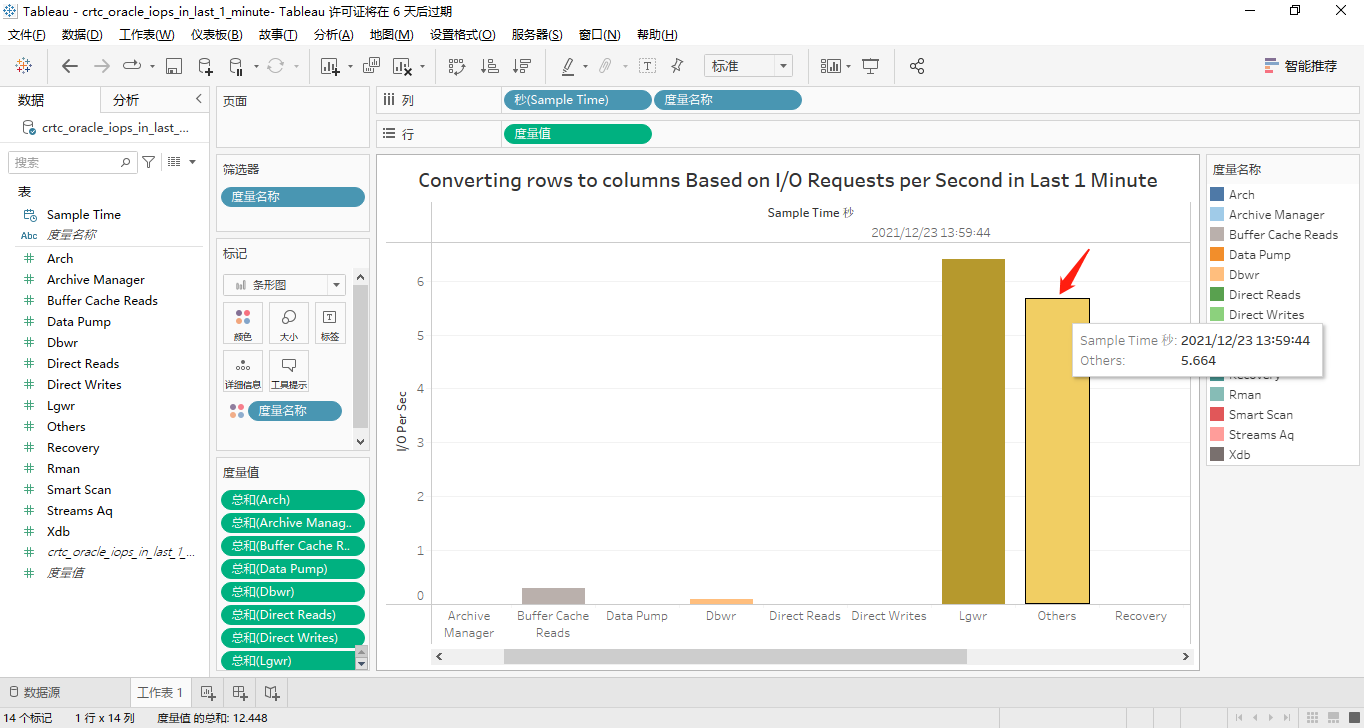
按function name分类的最近1小时的iops
最近1小时的iops的面积堆叠图设置相对简单,最终效果见下图:
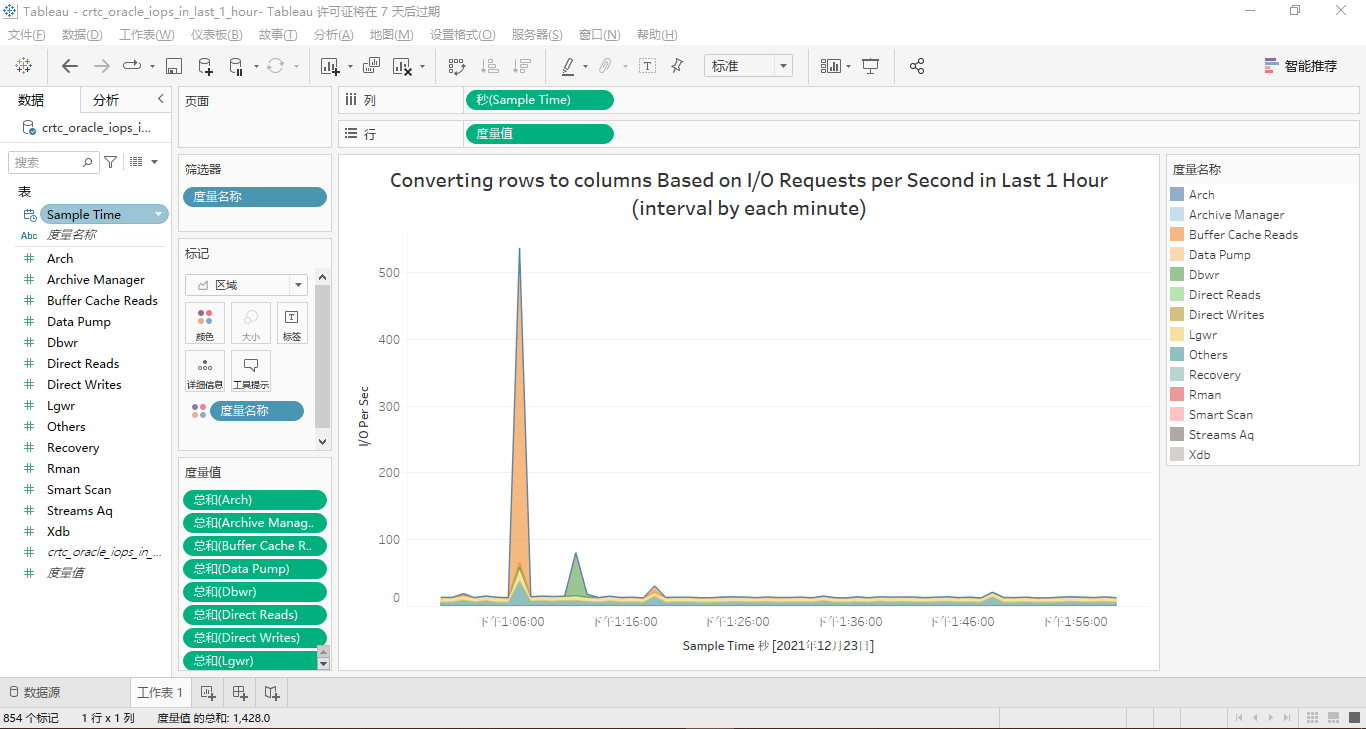
以上就是这篇文章用tableau可视化vertica数据库之“mbps&iops by function”篇的所有内容。另外,您也可以从和查看我前面提到的所有sql源代码。如果您有好的建议或意见,欢迎在文章底部的评论区提出,我将逐条阅读,并在最快时间内回复。