

table of contents
preface
i recalled a simple and relaxed scene chatting with my friend in his residence a couple of years ago (seems like in 2018), at that time he was responsible for maintaining some oracle databases of that is one of most popular and famous three telecom operators in china. i'm not sure what's the reason (probably we discussed something about data analysis) that he unconsciously mentioned a data analysis software that named . yes, i heard about this software from him for the first time. perhaps this thing has passed over the years.
earlier this month occasionally i discovered the free download resource about from m6米乐安卓版下载-米乐app官网下载 (as well-known as i'm the big fans of modb). since the version is 11.0.x then it should be the latest version at least i think. the primary aim is to drive and encouraged us to test, learn and communicate with each other in order to expanding and improving entire vertica ecosystem. based on those links i successively opened the and , the following is 2 number of relevant screenshots.
origin
it appears the english word "vertical" immediately in my brain when i've heard of vertica database for the first time. of course, on one hand they just have a bit difference between "vertical" and "vertica", on the other hand the antonym/opposite english word of "vertical" is "horizontal". naturally i can imagine that there exists the concept of a on the (relational database management system) in it database industry due to the pairs of these two english words because i'm an oracle dba in china. typically a two dimension table is comprised of multiple of rows and columns, the row is horizontal in the direction from left to right and the column is vertical in the direction from up to down. it's the usual concept that all of data from the table has been stored with the row format by rdbms, e.g. oracle, mysql, microsoft sql server, postgresql and other relational databases.
nevertheless the data from the table in vertica is stored with the column format. i've mentioned previously that the column of the table is vertical. i think that it's most possible and important reason about the origin of vertica database as well. you know, although, vertica official didn't say like that. thus it only represents my opinion rather than official standpoint of vertica.
history
it's almost hard to find out about the history introduction of vertica database, however, which's from the official website or official documentation home page. so i searched the keyword vertica on (the free encyclopedia). amazing! 's the full content about vertica. you can spend a little time reading it. hence just quoted a brief introduction as follows:
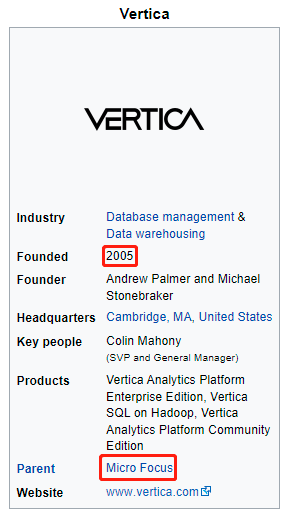
vertica systems is an analytic database management software company. vertica was founded in 2005 by database researcher michael stonebraker and andrew palmer. palmer was the founding ceo.
lynch joined as chairman and ceo in 2010 and was responsible for vertica's acquisition by hewlett packard in march 2011. the acquisition expanded the hp software portfolio for enterprise companies and the public sector group. as part of the micro focus-hewlett packard enterprise merger, vertica joined micro focus in september, 2017.
of course, here's a related screenshot.
if you check , and in underneath of the tab with services & support on it'll automatically skip to the who is the parent company of vertica currently.
now i have to mention that the company founder who also once created and , you're able to see the section about his personal introduction on . the following is a little quotation (you can find the full dissertation from as well):
c-store and vertica
in the c-store project, started in 2005, stonebraker, along with colleagues from brandeis, brown, mit, and university of massachusetts boston, developed a parallel, shared-nothing column-oriented dbms for data warehousing. by dividing and storing data in columns, c-store is able to perform less i/o and get better compression ratios than conventional database systems that store data in rows.
in 2005, stonebraker co-founded vertica to commercialize the technology behind c-store.
i've also just noticed that the version of vertica that started from 8.1.x to 11.0.x, the more earlier version has never been cited from the official documentation page. here's the corresponding screenshot:
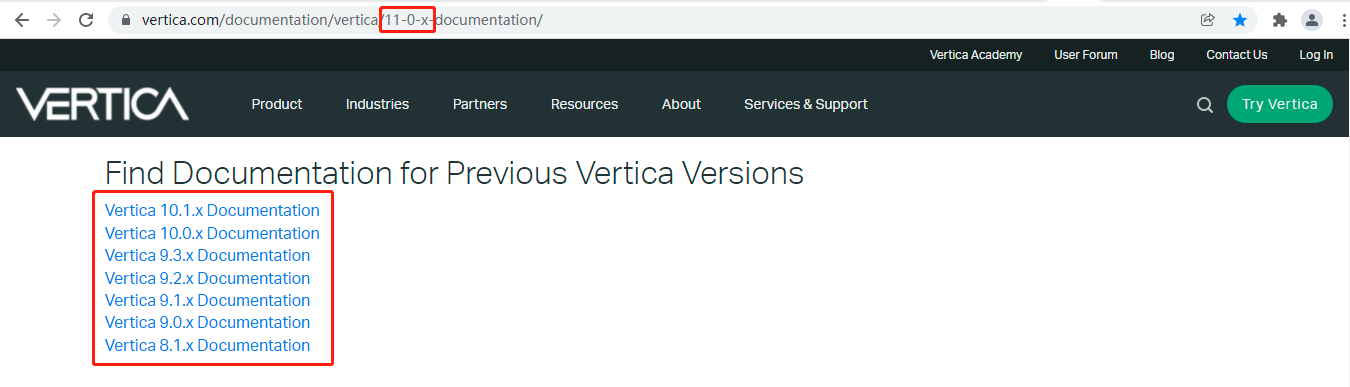
even if the official documentation of has been published on 6/2/2021, so it's difficult to say that exactly which year the 8.1.x has been released on but absolutely not on 2021 because the entire 2021 vertica never probably released the full versions from 8.1.x to 11.0.x. taking a look at this screenshot captured by me as below:
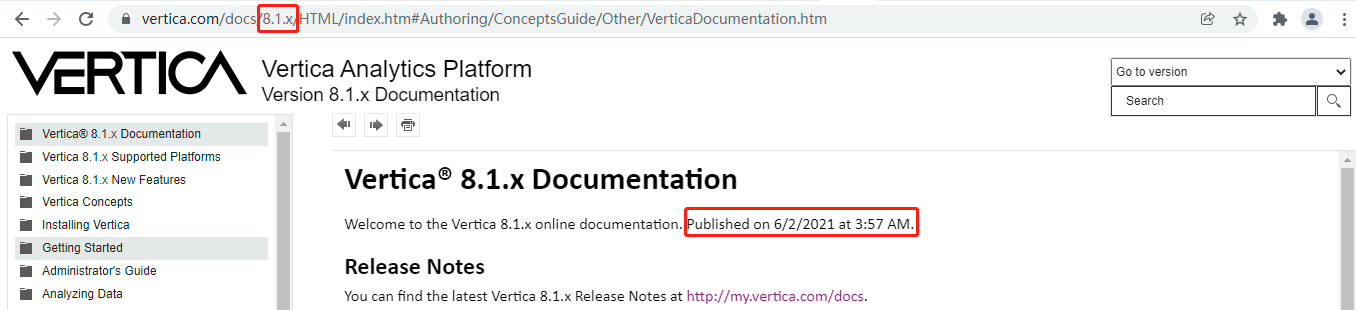
but about the history introduction of is very continuous and centralized whatever it's from or . meanwhile here's some critical events of vertica database that is quoted from wikipedia.
in late 2011, the vertica analytics platform community edition was made available for free with certain limitations, such as a maximum of one terabyte of raw data, three-node (servers) cluster, and community-based support.
in 2018, vertica introduced vertica in eon mode, a separation of compute and storage architecture, which is available on amazon, google, and microsoft clouds.
recent versions of vertica, 10.1.1 and 11 have introduced docker containerization and kubernetes statefulsets support, with tested containerized versions now released on dockerhub and github. this allows more automated deployment, testing, elastic scaling, and broader deployment support.
at the vertica unify event in july, 2021, vertica accelerator, a saas (software as a service) version of vertica, was announced initially on amazon aws only. vertica accelerator differs from similar analytics database services like snowflake, amazon redshift, and google bigquery.
architecture basics
there's three my most favorite architecture basics of vertica, it includes column storage, compression and clustering. thus i've just quoted some brief introduction in proper order from official documentation 11.0.x. but you can see more basics from .
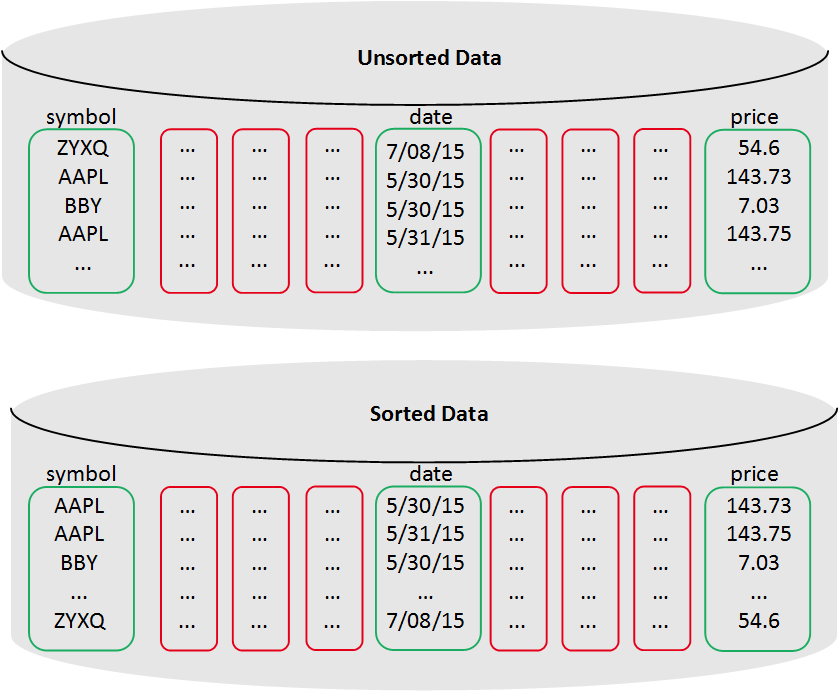
vertica stores data in a column format so it can be queried for best performance. compared to row-based storage, column storage reduces disk i/o making it ideal for read-intensive workloads. vertica reads only the columns needed to answer the query. for example:
select avg(price) from tickstore where symbol = 'aapl' and date = '5/31/13';
the column store usually reads only three columns but the row store reads all columns. the following is a nice image about unsorted-data and sorted-data (notice: the three columns marking with green color rectangle box).
using compression, vertica stores more data and uses less hardware than other databases. vertica uses several different compression methods and automatically chooses the best one for the data being compressed.
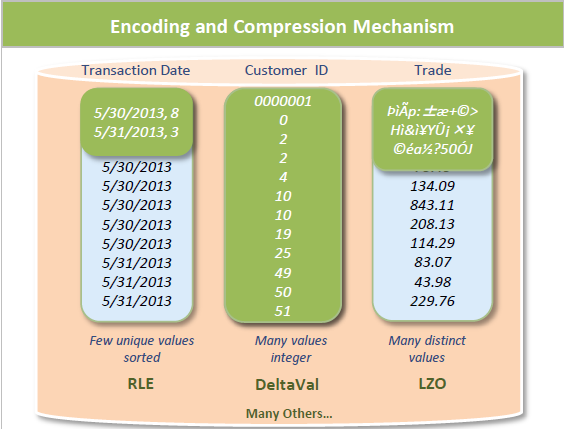
compression allows a column store to occupy substantially less storage than a row store. in a column store, every value stored in a projection column has the same data type. this greatly facilitates compression, particularly in sorted columns. in a row store, each value of a row can have a different data type, resulting in a much less effective use of compression. the efficient storage methods that vertica uses for your database also lets you maintain more historical data in physical storage.
the following shows compression using sorting and cardinality:
clustering supports scaling and redundancy. you can scale your database cluster by adding more nodes, and you can improve reliability by distributing and replicating data across your cluster.
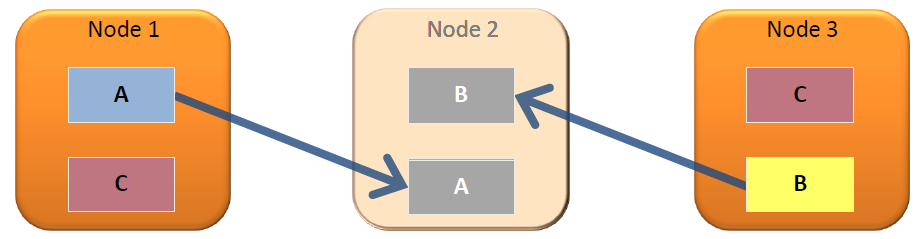
column data gets distributed across nodes in a cluster, so if one node becomes unavailable the database continues to operate. when a node is added to the cluster, or comes back online after being unavailable, it automatically queries other nodes to update its local data.
here's a relevant picture of three nodes that balanced distributing data (a, b and c) in a cluster.
enterprise mode vs eon mode
we can create a vertica database in one of two modes: enterprise mode or eon mode. these two number of modes allow us to control how and where the database stores the data. centainly, each mode has its own obvious advantages.
in an enterprise mode of vertica database, the physical architecture is designed to move data as close as possible to computing resources. the data in an enterprise mode database is spread among all of the nodes within the database. ideally, the data is evenly distributed to ensure that each node has an equal amount of the analytic workload. the following picture reveals its architecture mode.
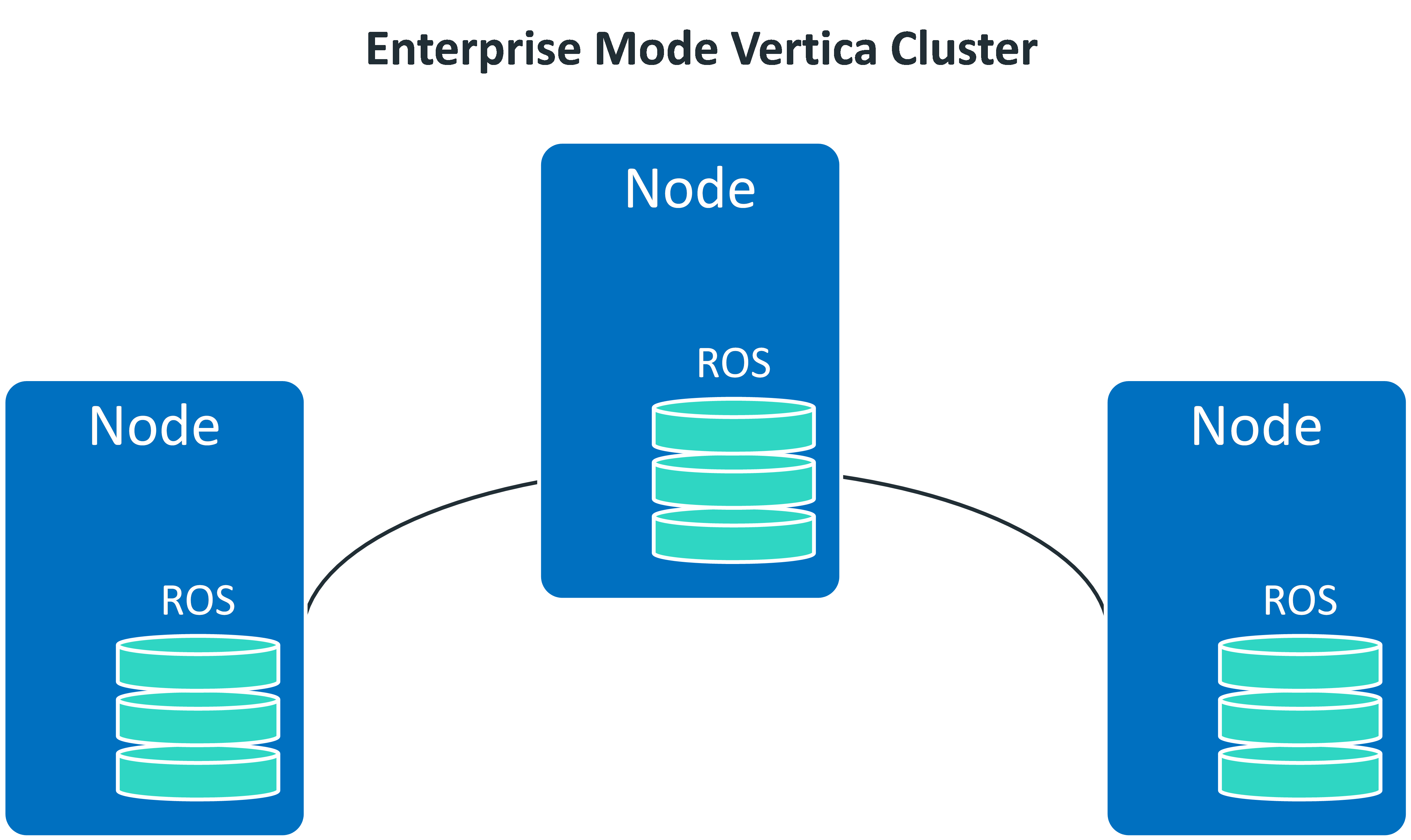
the architecture of eon mode is distinctly different from enterprise mode, it separates the computational resources from the storage layer of your database. this separation gives you the ability to store your data in a single location. you can elastically vary the number of nodes connected to that location according to your computational needs. adjusting the size of your cluster won't interrupt analytic workloads. yes, a real innovation thought plays an import role in the design of vertica database. its architecture concept diagram is as below:
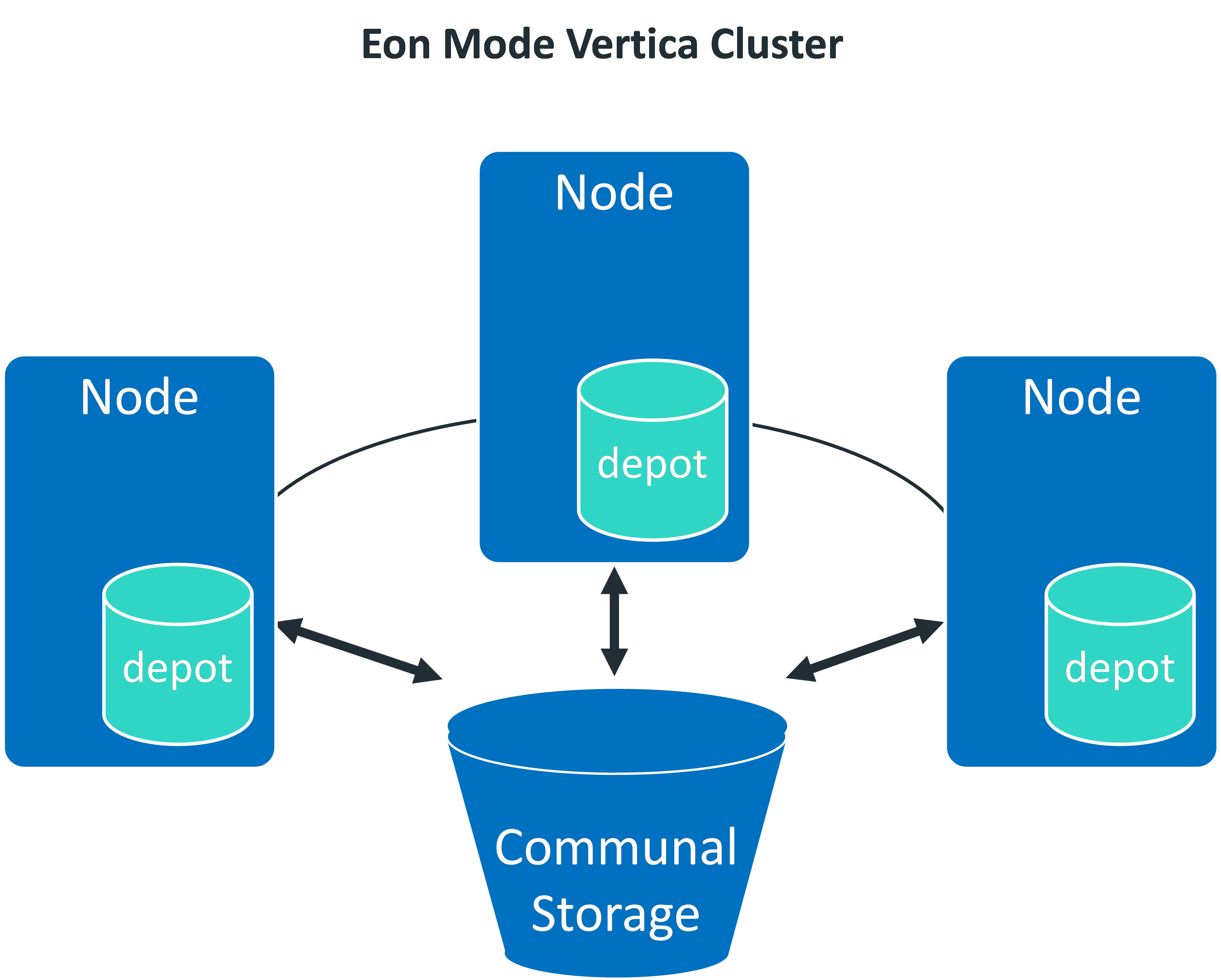
actually according to the relative volume of computer nodes and communal storage we can imagine that there are two types of eon modes (heavy storage, minimal compute and small storage, heavy compute) as follows.
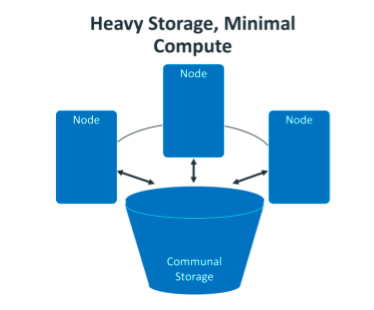
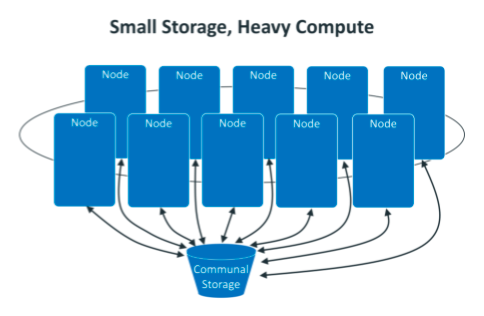
learning path
as an oracle dba with many years working experience i think that one of the most important learning paths about vertica database is still to read and solve your confusion by . here's two number of screenshots.

