

前言
在之前的文章中,已经介绍了prometheus grafana opengauss_exporter 安装部署,也介绍了配置mogdb/opengauss的grafana 的dashboard,在grafana上展示我们所关注的监控指标,但是我们在日常运维过程中并不会一直盯着监控看,所以还需要有一个告警模块,及时的将符合规则的告警触达到指定的人或者团队,从而将风险对业务的影响降到最低。在prometheus整个架构中,alertmanager模块就是为了实现这个功能。
安装部署
alertmanager安装部署
--下载解压
https://github.com/prometheus/alertmanager/releases
这里以0.23.0为例
https://github.com/prometheus/alertmanager/releases/download/v0.23.0/alertmanager-0.23.0.linux-amd64.tar.gz
# tar -zxvf alertmanager-0.23.0.linux-amd64.tar.gz -c /opt/
# ln -s /opt/alertmanager-0.23.0.linux-amd64/ /opt/alertmanager
# cd /opt/alertmanager
--启动
# nohup /opt/alertmanager/alertmanager --config.file=/opt/alertmanager/alertmanager.yml > /opt/alertmanager/alertmanager.log 2>&1 &
--web查看
直接在浏览器输入:http://172.16.3.90:9093,如果能打开界面,说明alertmanager配置成功
添加到prometheus
alertmanager 的默认端口是9093,需要将alertmanager添加到prometheus里统一管理
--编辑prometheus配置文件
# vi /opt/prometheus.yaml
# alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 172.16.3.90:9093
# load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "rules/*.yml"
# - "first_rules.yml"
# - "second_rules.yml"
----添加规则示例
# mkdir /opt/prometheus/rules
# vim node_rules.yml
groups:
- name: node_rule
rules:
- alert: server status
expr: up == 0
for: 10s
labels:
severity: critical
service: node
annotations:
summary: "{{$labels.instance}}: instance down"
description: "{{$labels.instance}}: instance down"
- alert: disk usage
expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 50
for: 1m
labels:
severity: warning
type: "service"
service: node
oid: "1.3.6.1.4.1.98789.0.1"
annotations:
summary: "disk used too high"
description: "service {{ $labels.instance}} : {{$value}}%)"
.
.
.

验证alertmanager是否可以正常接收到报警信息,修改磁盘容量使用情况告警规则验证一下,如果有下图展示方式,说明正常
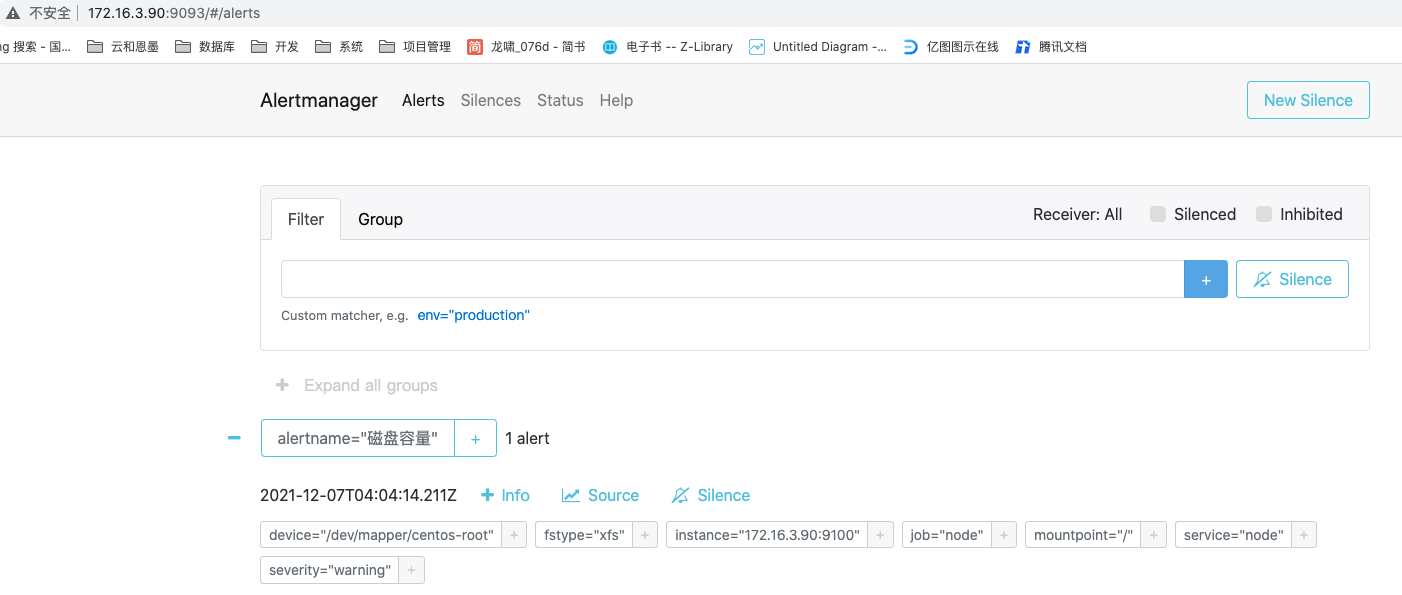
告警配置
snmp
--下载snmp_notifier
https://github.com/maxwo/snmp_notifier/releases/download/v1.2.1/snmp_notifier-1.2.1.linux-amd64.tar.gz
--解压启动snmp_notifier
# tar -zxvf snmp_notifier-1.2.1.linux-amd64.tar.gz -c /opt
# mv /opt/snmp_notifier-1.2.1.linux-amd64 /opt/snmp_notifier
# cd /opt/snmp_notifier
# nohup /opt/snmp_notifier/snmp_notifier > /opt/snmp_notifier/snmp_notifier.log 2>&1 &
# netstat -nap |grep -i 9464
tcp6 0 0 :::9464 :::* listen 14502/snmp_notifier
页面展示
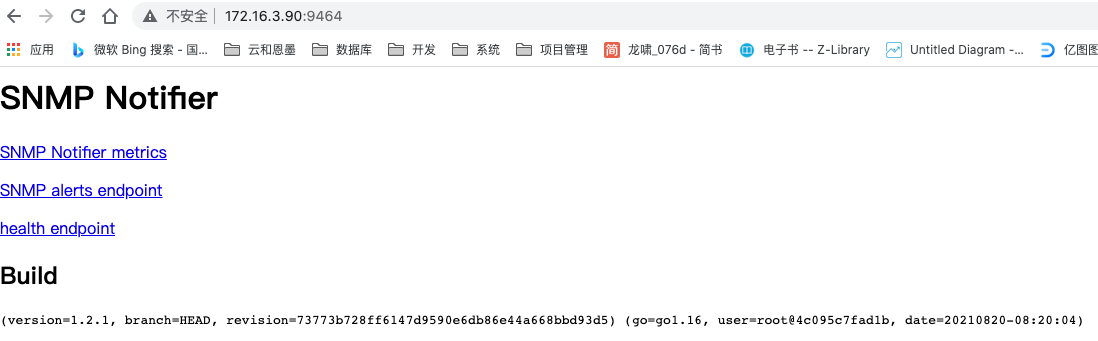
修改alertmanager.yml配置文件
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: 'snmp_notifier'
receivers:
- name: 'snmp_notifier'
webhook_configs:
- send_resolved: true
url: http://172.16.3.90:9464/alerts
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
在本地启动snmptrapd接受报警信息
# snmptrapd -m all -f -of -lo -c /opt/software/snmp_notifier-1.2.1/scripts/snmptrapd.conf
net-snmp version 5.7.2
agent address: 0.0.0.0
agent hostname: localhost
date: 15 - 16 - 8 - 13 - 1 - 4461724
enterprise oid: .
trap type: cold start
trap sub-type: 0
community/infosec context: trap2, snmp v2c, community public
uptime: 0
description: cold start
pdu attribute/value pair array:
.iso.org.dod.internet.mgmt.mib-2.system.sysuptime.sysuptimeinstance = timeticks: (80298000) 9 days, 7:03:00.00
.iso.org.dod.internet.snmpv2.snmpmodules.snmpmib.snmpmibobjects.snmptrap.snmptrapoid.0 = oid: .iso.org.dod.internet.private.enterprises.98789.0.1
.iso.org.dod.internet.private.enterprises.98789.0.1.1 = string: "1.3.6.1.4.1.98789.0.1[alertname=disk usage]"
.iso.org.dod.internet.private.enterprises.98789.0.1.2 = string: "warning"
.iso.org.dod.internet.private.enterprises.98789.0.1.3 = string: "status: warning
- alert: disk usage
summary: disk used too high
description: service 172.16.3.90:9100 : 62.67489771617%)"
--------------
agent address: 0.0.0.0
agent hostname: localhost
date: 15 - 16 - 8 - 13 - 1 - 4461724
enterprise oid: .
trap type: cold start
trap sub-type: 0
community/infosec context: trap2, snmp v2c, community public
uptime: 0
description: cold start
pdu attribute/value pair array:
.iso.org.dod.internet.mgmt.mib-2.system.sysuptime.sysuptimeinstance = timeticks: (80328000) 9 days, 7:08:00.00
.iso.org.dod.internet.snmpv2.snmpmodules.snmpmib.snmpmibobjects.snmptrap.snmptrapoid.0 = oid: .iso.org.dod.internet.private.enterprises.98789.0.1
.iso.org.dod.internet.private.enterprises.98789.0.1.1 = string: "1.3.6.1.4.1.98789.0.1[alertname=disk usage]"
.iso.org.dod.internet.private.enterprises.98789.0.1.2 = string: "info"
.iso.org.dod.internet.private.enterprises.98789.0.1.3 = string: "status: ok"
--------------
钉钉告警
下载webhook_dingtalk
[root@iz2ze6qstyvxj93cbcn5exz go]# mkdir -p src/github.com/timonwong/
[root@iz2ze6qstyvxj93cbcn5exz go]# cd src/github.com/timonwong/
[root@iz2ze6qstyvxj93cbcn5exz timonwong]# git clone https://github.com/timonwong/prometheus-webhook-dingtalk.git
编译安装
[root@db-dev prometheus-webhook-dingtalk]# cd prometheus-webhook-dingtalk
[root@db-dev prometheus-webhook-dingtalk]# make build
>> writing assets
# un-setting goos and goarch here because the generated go code is always the same,
# but the cached object code is incompatible between architectures and oses (which
# breaks cross-building for different combinations on ci in the same container).
go111module=on goos= goarch= go generate -mod=vendor ./template
writing assets_vfsdata.go
go111module=on goos= goarch= go generate -mod=vendor ./web/ui
writing assets_vfsdata.go
curl -s -l https://github.com/prometheus/promu/releases/download/v0.5.0/promu-0.5.0.linux-amd64.tar.gz | tar -xvzf - -c /tmp/tmp.vlpcnjicjq
promu-0.5.0.linux-amd64/
promu-0.5.0.linux-amd64/promu
promu-0.5.0.linux-amd64/notice
promu-0.5.0.linux-amd64/license
mkdir -p /root/go/bin
cp /tmp/tmp.vlpcnjicjq/promu-0.5.0.linux-amd64/promu /root/go/bin/promu
rm -r /tmp/tmp.vlpcnjicjq
>> building binaries
go111module=on /root/go/bin/promu build --prefix /root/go/src/github.com/timonwong/prometheus-webhook-dingtalk
> prometheus-webhook-dingtalk
--配置dingtalk_config.yml文件
## request timeout
# timeout: 5s
## customizable templates path
templates:
- /opt/alertmanager/dingtalk_config.tmpl
# - /root/go/src/github.com/timonwong/prometheus-webhook-dingtalk/contrib/templates/legacy/template.tmpl
## you can also override default template using `default_message`
## the following example to use the 'legacy' template from v0.3.0
# default_message:
# title: '{{ template "legacy.title" . }}'
# text: '{{ template "legacy.content" . }}'
## targets, previously was known as "profiles"
targets:
dingtalk_db:
url: https://oapi.dingtalk.com/robot/send?access_token=9a3709ca79cc055a4d98ec37002082f1dc66039bddea77942ad45d9dcae163db
#message:
# use legacy template
#title: '{{ template "legacy.title" . }}'
#text: '{{ template "legacy.content" . }}'
dingtalk:
url: https://oapi.dingtalk.com/robot/send?access_token=3a915133306ed497730bbd60c3c378fe7af07bc3a4cd4745fa06f1889928ed56
启动dingtalk
nohup ./prometheus-webhook-dingtalk --ding.profile="ops_dingding=https://oapi.dingtalk.com/robot/send?access_token=b65f8ddc1809583b629a9587b3182bb51f66551e52c73b755cf7bb0cd724fd80" 2>&1 &
或
nohup /usr/bin/prometheus-webhook-dingtalk --config.file=dingtalk_config.yml --web.enable-lifecycle > dingtalk.log 2>&1 &
修改alertmanager.yml
global:
resolve_timeout: 1m
route:
receiver: dingtalk
group_wait: 1m
group_interval: 5m
repeat_interval: 10m
group_by: ['alertname']
routes:
- receiver: dingtalk_db
group_wait: 1h
group_interval: 1h
repeat_interval: 1d
match_re:
service: mysql|redis|postgres|node
severity: warning
- receiver: dingtalk_db
group_wait: 10m
group_interval: 10m
repeat_interval: 1h
match_re:
service: mysql|redis|postgres
severity: error
- receiver: dingtalk_db
group_wait: 10s
group_interval: 10s
repeat_interval: 1m
match_re:
service: mysql|redis|postgres
severity: critical
receivers:
- name: dingtalk_db
webhook_configs:
- url: http://xxx.xxx.xxx.xxx:8060/dingtalk/dingtalk_db/send
send_resolved: true
- name: dingtalk
webhook_configs:
- url: http://xxx.xxx.xxx.xxx:8060/dingtalk/dingtalk/send
send_resolved: true
邮件告警
仅需要修改alertmanager.yml文件即可
global:
resolve_timeout: 5m
smtp_from: 'nair@xxx.cn'
smtp_smarthost: 'smtp.xxx.cn:587'
smtp_auth_username: 'nair@xxx.cn'
smtp_auth_password: 'xxxxxxx'
smtp_hello: 'xxx.cn'
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 5s
repeat_interval: 1m
receiver: 'email'
routes:
- receiver: email
group_wait: 10s
group_interval: 20s
repeat_interval: 30s
match_re:
service: mysql|redis|postgres|node
severity: critical
- receiver: email
group_wait: 1m
group_interval: 1m
repeat_interval: 1m
match_re:
service: mysql|redis|postgres|node
severity: error
- receiver: email
group_wait: 1h
group_interval: 1h
repeat_interval: 1h
match_re:
service: mysql|redis|postgres|node
severity: warning
receivers:
- name: 'email'
email_configs:
- to: 'xxx@xxxemail.cn'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
最后修改时间:2022-04-13 23:52:38
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【米乐app官网下载的版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。