

一、core dump文件生成
core文件其实就是内存的映像,当程序崩溃时,存储内存的相应信息,主用用于对程序进行调试。当程序崩溃时便会产生core文件,其实准确的应该说是core dump 文件,默认生成位置与可执行程序位于同一目录下。
1.查看core文件生成是否开启
ulimit -a
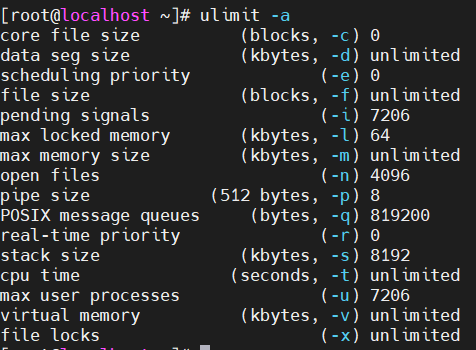
第一行core file size 如果是0表示没有打开,unlimited表示不限制产生文件大小。
ulimit -c 查看也可以

2.开启关闭core
关闭或阻止core文件生成:
$ulimit -c 0
打开core文件生成且不限制:
$ulimit -c unlimited
如果生成的信息超过此大小,将会被裁剪,最终生成一个不完整的core文件。
在调试这样的core文件的时候,gdb会提示错误。
临时设置(如下设置2g,单位为kbyte)
ulimit -c 4194304
3.修改core文件名称
(1)临时修改:
修改/proc/sys/kernel/core_pattern文件,但/proc目录本身是动态加载的,每次系统重启都会重新加载,因此这种方法只能作为临时修改。
使用root用户修改core文件生成名和路径:生成的core文件保存在/tmp/corefile 目录下,且core文件名为:
core-命令名-pid-时间戳(需系统支持修改该文件)
echo /tmp/corefile/core-%e-%p-%t > /proc/sys/kernel/core_pattern
可以将core文件统一生成到/corefile目录下,产生的文件名为core-命令名-pid-时间戳
以下是参数列表:
%p - insert pid into filename 添加pid(进程id)
%u - insert current uid into filename 添加当前uid(用户id)
%g - insert current gid into filename 添加当前gid(用户组id)
%s - insert signal that caused the coredump into the filename 添加导致产生core的信号
%t - insert unix time that the coredump occurred into filename 添加core文件生成时的unix时间
%h - insert hostname where the coredump happened into filename 添加主机名
%e - insert coredumping executable name into filename 添加导致产生core的命令名
(2)永久修改:
可以通过在/etc/sysctl.conf文件中,对sysctl变量kernel.core_pattern的设置。
#vi /etc/sysctl.conf 然后,在sysctl.conf文件中添加下面两行:
kernel.core_pattern = /tmp/corefile/core-%e-%p-%t
kernel.core_uses_pid = 0
kernel.core_uses_pid 这个参数控制core文件的文件名是否添加pid作为扩展,如果这个文件的内容被配置成1,即使core_pattern中没有设置%p,最后生成的core dump文件名仍会加上进程id
使用以下命令,使修改结果马上生效。
sysctl –p /etc/sysctl.conf
二、gdb工具使用
1.介绍
gdb是一个由gnu开源组织发布的、unix/linux操作系统下的、基于命令行的、功能强大的程序调试工具。
在实际应用中,有两种调试方法:在线调试和离线调试。
离线调试适用于开发测试环境,可以自由启停进程,设置断点;
在线调试一般用于现场问题分析,不能随便启停进程。
gdb主要来调试c/c 语言写的程序,当然也可以调试其他语言程序
gdb调试一定要是可执行文件而不是.c文件,要用gcc进行编译
如果调试postgresql和类似的国产数据库,建议postgresql编译项的enable-debug打开,它会开启调试符号使调试器跟踪代码。
gcc -g 源文件.c -o 输出的目标文件
gcc -g test.c -o test
-g表示以os本地格式(stabs,coff,xcoff或dwarf 2)产生调试信息
2.gdb主要可以做四种事情来帮助你找到bug:
启动你的程序,指定任意可以影响程序行为的参数。
让你的程序在指定的条件停住.
测试你的程序停止的时候发生了什么。
改变程序内部的变量,来改正程序的错误继续执行。
3.使用gdb
(1)调试可执行文件
可以不带任何参数或选项执行gdb命令,但是最常用的启动gdb的方式是带一个或者两个参数,指定一个可执行文件来作为参数:
gdb program(gdb 可执行文件名称)
(2)分析core文件
也可以再gdb文件后面指定可执行文件 和 core文件的名称:
gdb program core(gdb 可执行文件 core文件)
在获取core文件时候,可以根据file命令获取是谁产生的

上边的core.20458文件是我执行kill -s sigsegv $$生成的
因此执行
gdb /bin/bash -c core.20458
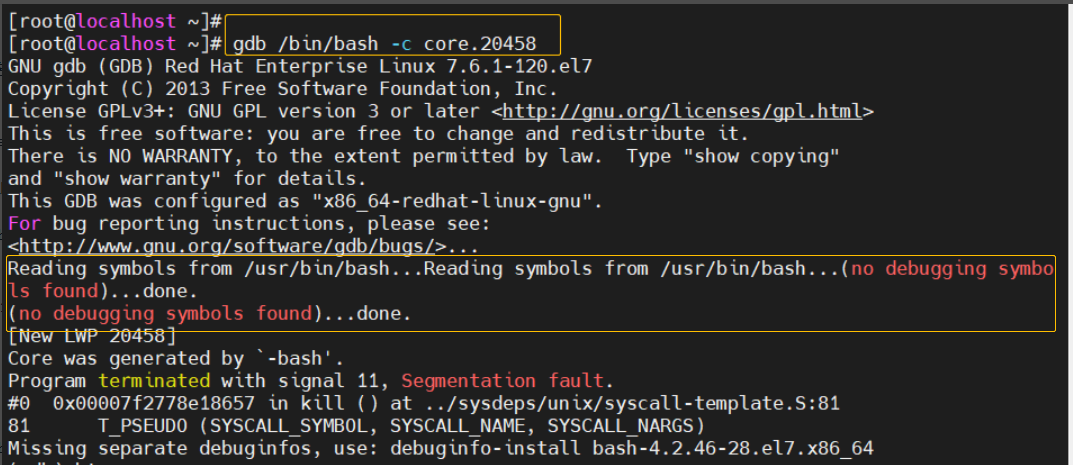
图中显示我没有符号表,需要把符号表拷贝到相应的bin目录下,例如如果是opengauss数据库产生的core的话,就找到相应的符号表的包解压出来,把gaussdb.symbol拷贝到数据库的bin/下。(根据提示放到指定位置就可以)
(3)根据进程调试
如果要调试正在运行的进程,可以指定进程id作为第二个参数
也可以指定一个进程id作为第二个参数,如果你想调试一个正在运行的程序:
gdb program 1234(gdb进程名 进程id)
会附加gdb到进程1234上(除非有一个文件名“1234”;gdb首先检查core文件)
4.调试
常用调试命令
break [file:]function 设置一个断点在函数中(在文件中)
run [arglist] 启动程序带上指定的参数
bt backtrace: 显示堆栈
print expr 显示表达式的值
c 继续执行你的程序(程序停住后,例如:在断点处停止)
next/n 执行程序的下一行代码(程序停止以后);跨国任何当前行的函数调用。
edit [file:]function 查看当前程序停在哪。
list [file:]function 显示程序当前停住的代码行附近的代码
step 单步调试 执行程序的下一行(程序停住后),进入当前行的函数调用的内部,退出函数时使用finish
finish 结束函数
help [name] 显示gdb命令的相关信息。
return 忽略当前未执行的部分,强制返回
quit 退出gdb
5.测试
编写一个测试的文件ysla.c
#include
int main()
{
int a,gw,bw,sw,g,b,r;
scanf("%d",&a);
if(a<10&&a>99)
{
gw=a;
r=a/10;
sw=r;
bw=r/10;
b=gw;
g=bw;
r=b*100 sw*10 g;
printf("%d\n",r);
}
return 0;
}
编译生成执行文件
gcc -g ysla.c -o ysla
使用gdb调试
gdb ysla
(1)列出代码
(gdb) l
列出代码,相当于list,从第一行开始例出原码
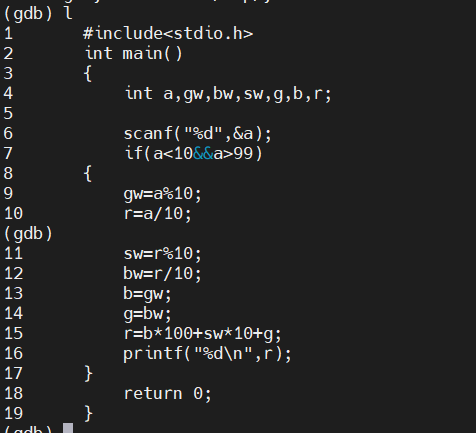
直接回车会重复上一次的操作
(2)设置断点
(gdb) gdb 13

(3)查看断点信息
(gdb) info break

(4)运行程序,run命令简写
(gdb) r
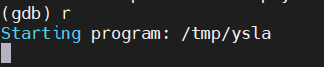
会在断点处停住
(5)单条执行,next命令简写
(gdb) n
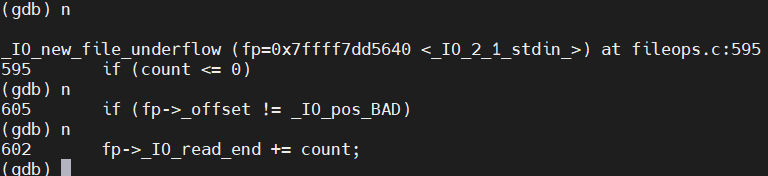
(6)继续执行,continue命令简写
(gdb) c

(7)打印变量,print简写
(gdb) p fp
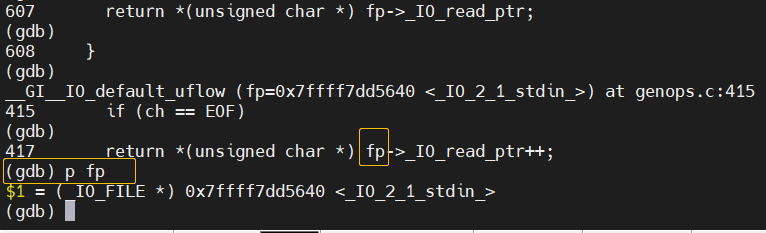
(8)查看函数堆栈
(gdb) bt
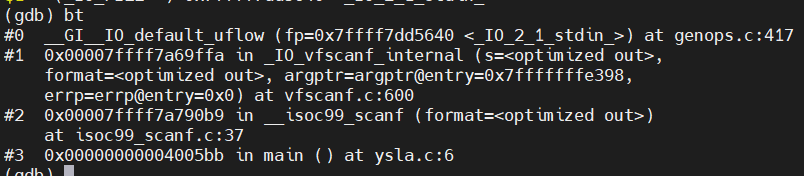
(9)退出函数
(gdb) finish
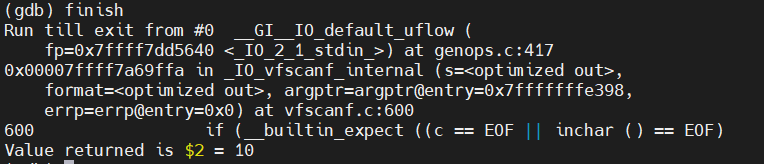
(10)退出gdb
(gdb) q