

目录
前言
最近我在m6米乐安卓版下载-米乐app官网下载上连续发表了两篇关于“可视化oracle性能图表”的原创文章,它们分别是:

维度目录列表
- 最近1小时的平均可运行进程
- 最近24小时的平均可运行进程
- 最近7天的平均可运行进程(按每小时间隔)
- 最近7天的平均可运行进程(按每天间隔)
- 最近31天的平均可运行进程(按每小时间隔)
- 最近31天的平均可运行进程(按每天间隔)
- 自定义时间段的平均可运行进程(按每小时间隔)
- 自定义时间段的平均可运行进程(按每天间隔)
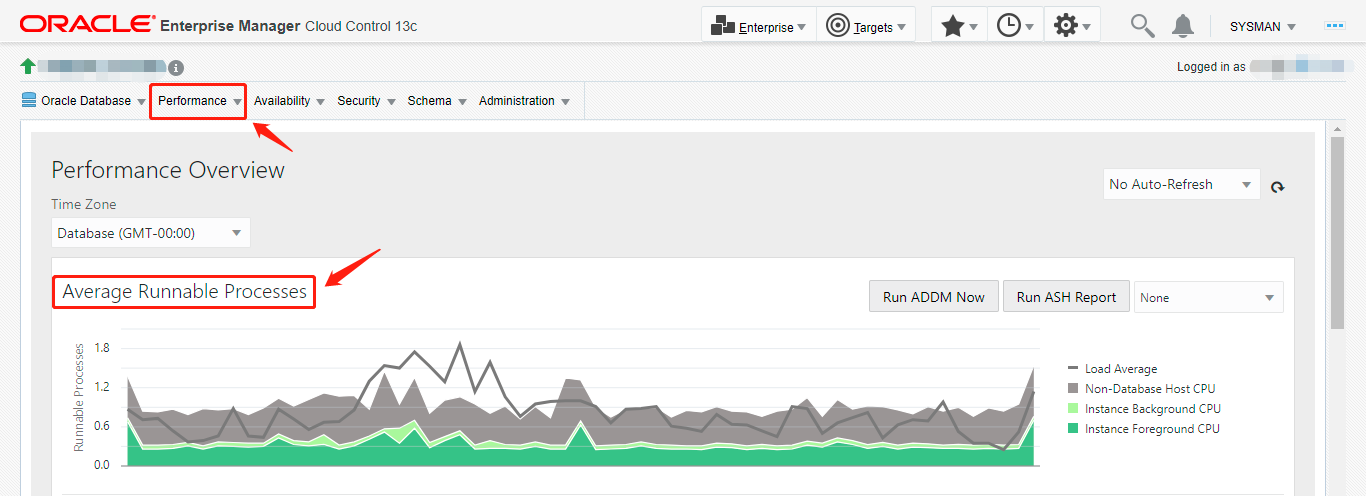
最近1小时的平均可运行进程
感谢kyle hailey
上个月底,我在推特上看到了发了一条有趣的推文,我越读越觉得特别熟悉,它分明就是上个月中下旬我在的里发的中提到的这个“平均可运行进程”图表,推文内容如图所示:
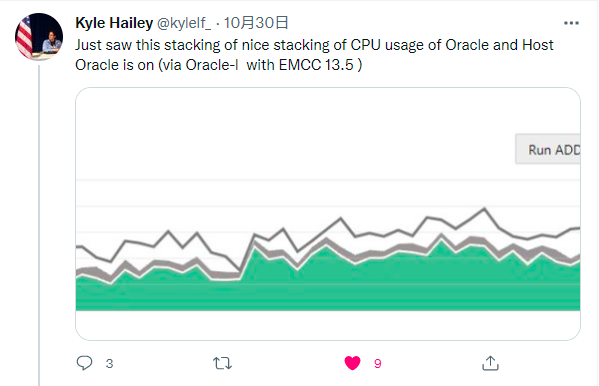
于是,我就借机向他表示感谢并请教如何利用sql语句才能查询出这个图表的数据并进一步可视化。他很热心地回复我,他没有做过这个,但是给我推荐了他曾经写过的,说我也许会感兴趣,详见如下两图:
果不其然,我反复读了几篇他的文章和一些朋友们在评论区给他发的消息以及他的回复之后,终于写出了最近1小时的“平均可运行进程”的sql语句。于是,接连四天给他回复了我对他的博客文章的一些理解,如图所示:
直接上代码,我写出的sql代码是这样的:
-- average runnable processes in last 1 hour.
set linesize 200
set pagesize 300
column metric_name format a25
alter session set nls_date_format = 'yyyy-mm-dd hh24:mi:ss';
with ins_fg_cpu as
(
select end_time sample_time
, decode(metric_name, 'cpu usage per sec', 'instance foreground cpu') metric_name
, round(value/1e2, 2) value
from v$sysmetric_history
where metric_name = 'cpu usage per sec'
and group_id = 2
and end_time >= sysdate - interval '60' minute
order by sample_time
),
ins_bg_cpu as
(
select end_time sample_time
, decode(metric_name, 'background cpu usage per sec', 'instance background cpu') metric_name
, round(value/1e2, 2) value
from v$sysmetric_history
where metric_name = 'background cpu usage per sec'
and group_id = 2
and end_time >= sysdate - interval '60' minute
order by sample_time
),
host_cpu as
(
select end_time sample_time
, decode(metric_name, 'host cpu usage per sec', 'host cpu') metric_name
, round(value/1e2, 2) value
from v$sysmetric_history
where metric_name = 'host cpu usage per sec'
and group_id = 2
and end_time >= sysdate - interval '60' minute
order by sample_time
),
non_db_host_cpu as
(
select hc.sample_time
, 'non-database host cpu' metric_name
, hc.value - fc.value - bc.value value
from host_cpu hc
, ins_fg_cpu fc
, ins_bg_cpu bc
where hc.sample_time = fc.sample_time
and fc.sample_time = bc.sample_time
order by hc.sample_time
),
load_average as
(
select end_time sample_time
, decode(metric_name, 'current os load', 'load average') metric_name
, round(value, 2) value
from v$sysmetric_history
where metric_name = 'current os load'
and group_id = 2
and end_time >= sysdate - interval '60' minute
order by sample_time
)
select * from ins_fg_cpu
union all
select * from ins_bg_cpu
union all
select * from non_db_host_cpu
union all
select * from load_average
;当然,代码有点多,我就简单解释一下。oracle动态性能视图“v$sysmetric_history”中的“metric_name”的值“cpu usage per sec”就是我在emcc13.5中看到的“平均可运行进程”图表的第一个图例(图例条目从下往上数,因为三个cpu都是以“面积堆叠图”来展示的)“instance foreground cpu”;以此类推,“metric_name”的值“background cpu usage per sec”对应于第二个图例“instance background cpu”,但是第三个图例“non-database host cpu”不能直接从metric_name的值中得到了,不过metric_name有一个值是“host cpu usage per sec”,将它与它俩(“cpu usage per sec”和“background cpu usage per sec”)的和进行相减就是“non-database host cpu”。此外,metric_name的值“current os load”对应于第四个图例“load average”(以“折线图”来展示的,非“面积堆叠图”)。然后将四个临时表(ins_fg_cpu,ins_bg_cpu,non_db_host_cpu和load_average)依次进行union all操作,就是最终的sql代码。非常巧合的是,在kyle hailey的那篇文章的评论区也提到了相似的观点,见下图:
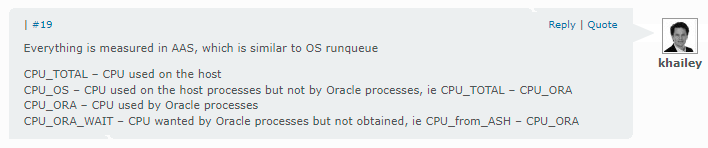
对比“sql查询数据”和“emcc 13.5的图表显示数据”
为了验证我写的sql代码的查询数据能否和emcc 13.5中“最近1小时的平均可运行进程”图表的显示数据一致,我专门把两者在“同一时间(2021-11-20 14:13)”的数据通过四组屏幕截图进行了前后对比,它们分别为:
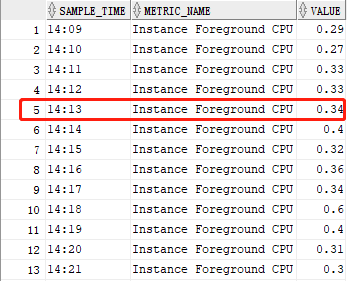

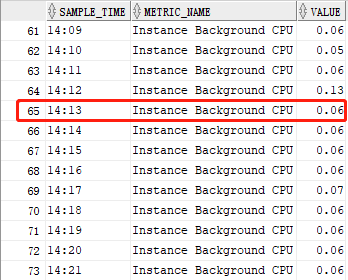

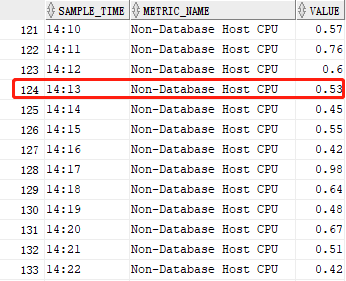

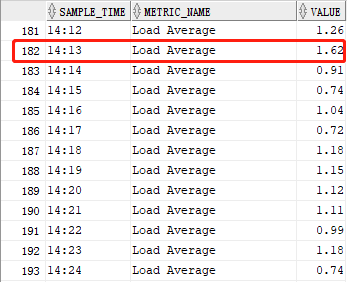

从上面的四组对比图中,我们可以看出,我写的“sql代码”完全吻合“emcc 13.5”的图表数据。
用oracle sql developer 21.2可视化
在前两篇文章中,我曾使用中的用户自定义报告来对其它oracle性能图表进行了一系列的可视化展示(细心的读者已经留意到,我使用的图表类型是常见的“折线图”)。现在我也用同样的方法来可视化最近1小时的平均可运行进程。注意:我们这里要使用的图表类型应该是“组合图”(按照图例从下往上数,前三个是“面积堆叠图”,后一个是“折线图”)。当然,前面的几步设置操作相当顺畅,在这里略过,直到点击“应用”按钮以后,却发现图表的可视化效果让我大跌眼镜。不过,我猜应该是sql developer出现了bug。于是,我在的发了一个,希望得到oracle社区朋友们的反馈。不幸的是,没有回音。接着,我又到上发了一遍,connor mcdonald给我的反馈是他已经转到了sql dev folks那里,静等下一个版本中会得到修复吧。其中,预览效果(前两图)是正确的,实际效果(后一图)是错误的。详见如下三张相应的屏幕截图:
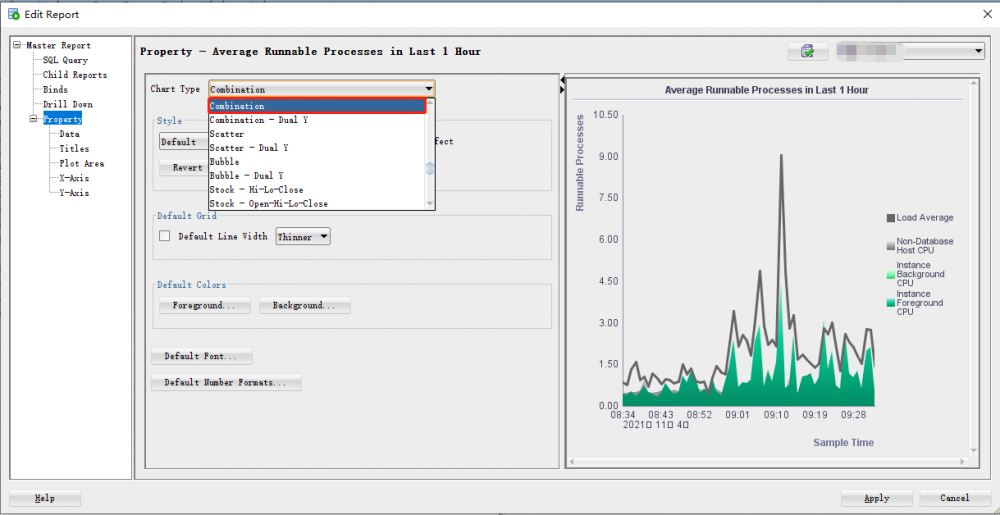
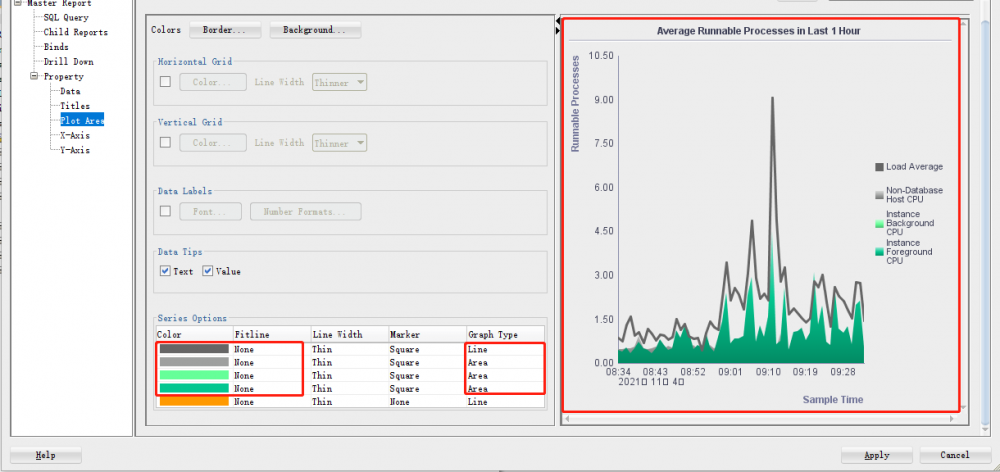
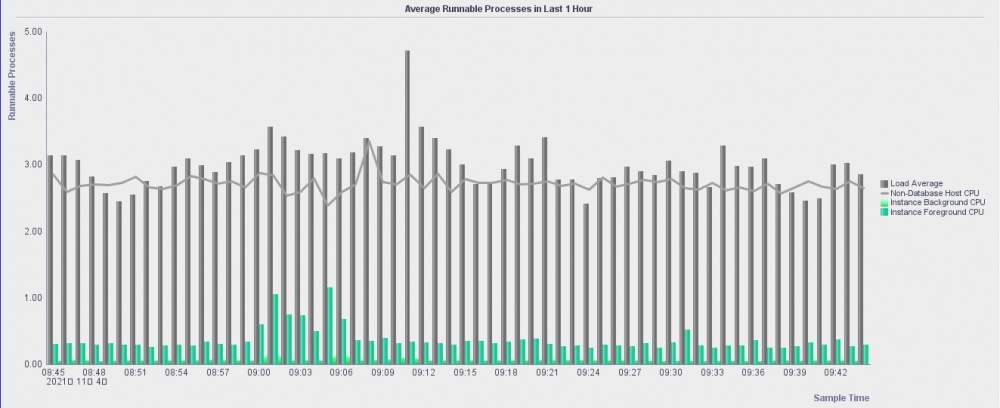
用oracle apex 21.2可视化
果断放弃sql developer的自定义报告以后,我决定采用最新版本的来寻找m6米乐安卓版下载的解决方案。通过申请工作空间和注册账号等一系列基本的操作以后,我得到了一个apex工作空间。如图所示:
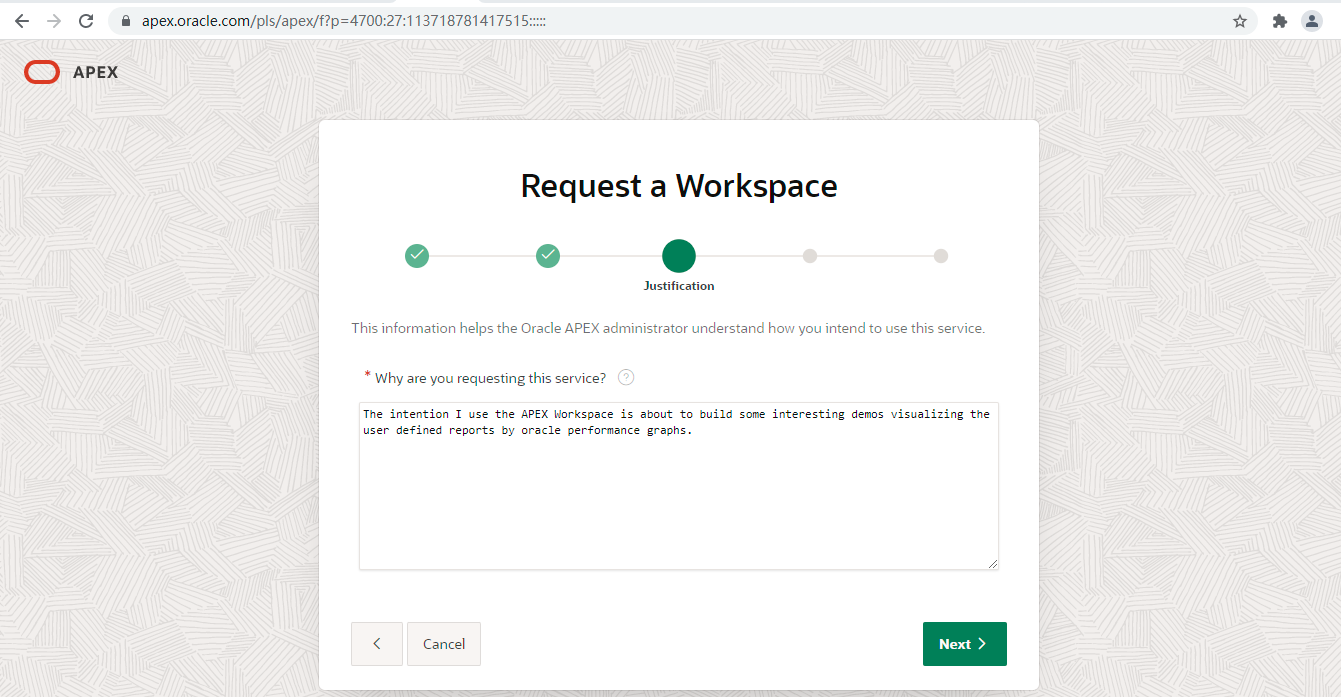
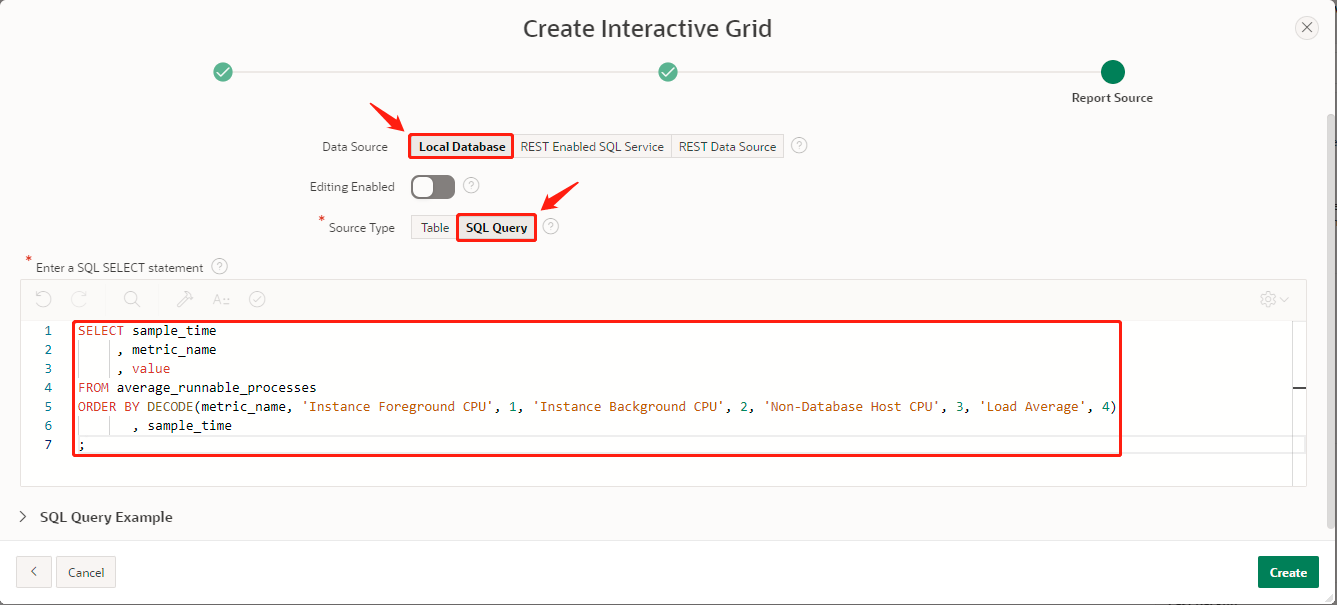
接着,我在sql*plus里使用spool命令包裹我前面的sql代码一起执行生成一个csv格式的文件并导出到我的电脑,然后将该csv文件导入到我刚刚创建的apex工作空间并同时生成了一个arp的应用。在该应用的米乐app官网下载主页中我创建了一个“interactive grid”的报表。在运行该应用程序以后,我发现我的报表页面有一个“actions”的下拉按钮列表,在里面有一个“chart”,这个正好是我期待的图表功能。当我点击它以后,弹出一个对话框,里面包括许多常见的图表类型,可惜没有找到我想要的“组合图表”,详见如下两图:
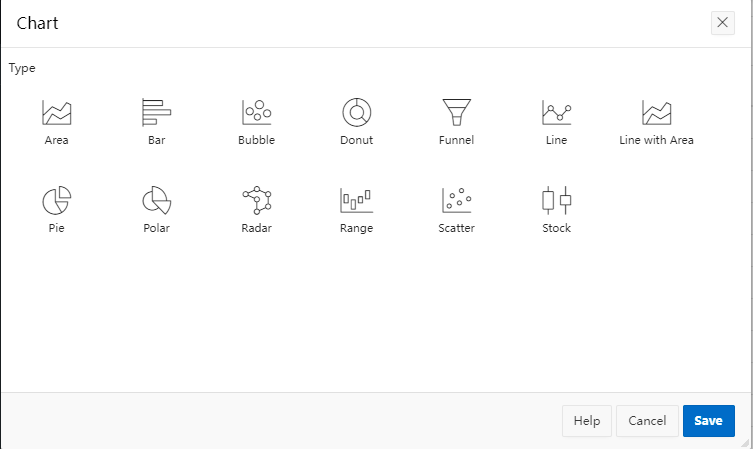
用microsoft office excel可视化
果断放弃oracle apex的图表以后,我决定采用microsoft office excel来寻找m6米乐安卓版下载的解决方案。也许这个方法最原始,但也是最本质的,退一步来讲,追本溯源,值得借鉴。首先,让我们来看一下excel中的的基本原理,下面这张图介绍得透彻明了:
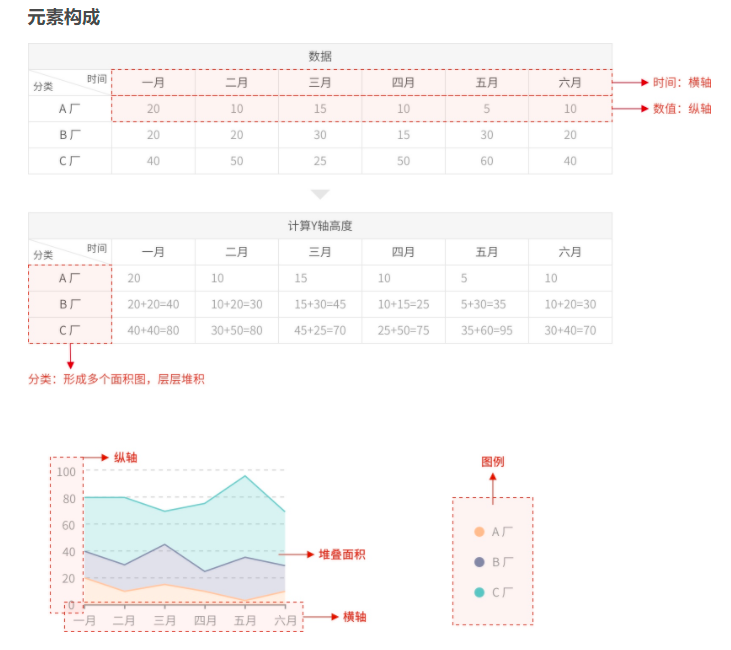
从上图,我们可以了解到,excel数据表中的“时间”代表“面积堆叠图”中的横轴,表格中的“分类”代表“面积堆叠图”中的图例,表格中的“其它单元格的值”代表“面积堆叠图”中的纵轴。通过“平均可运行进程”图表中的横轴、纵轴和图例进行类比,excel数据表应该是,时间是sql查询中的“采样时间”,分类是sql查询中的“度量名字”,其它单元格的值是sql查询中的“值”。这里我们不能直接使用先前的sql查询来得到excel数据表。又因为excel数据表的所有数据列名(采样时间)正好是sql查询中的所有行(采样时间列的值),所以我们需要把先前的sql查询进行一下改良,即进行“行转列”操作以后,就可以得到相应的excel数据表;又因为我们每次查询的最近1小时的“采样时间”也是不断变化的,所以我们将要进行的改良操作,不是“固定行转列”,而是“动态行转列”。
接着,我用先前的sql查询创建一个“视图”,然后再对这个视图进行“动态行转列”操作。由于我是在system用户下进行的查询,所以在创建“视图”之前,需要提前给v$sysmetric_history(和dba_hist_sysmetric_summary,后面七个维度需要查这张表,再此一并授权)做一些“授权”操作,详见如下代码:
desc dba_sys_privs
name null? type
----------------------------------------------------------------- -------- --------------------------------------------
grantee not null varchar2(30)
privilege not null varchar2(40)
admin_option varchar2(3)
select privilege from dba_sys_privs where grantee = 'system' order by 1;
privilege
--------------------------------------------------------------------------------
create materialized view
create table
global query rewrite
select any table
unlimited tablespace
grant select on v_$sysmetric_history to system;
grant select on dba_hist_sysmetric_summary to system;
set linesize 100
column table_name format a28
column privilege format a10
select table_name
, privilege
from dba_tab_privs
where grantee = 'system'
and table_name in ('v_$sysmetric_history', 'dba_hist_sysmetric_summary')
order by 1
;
table_name privilege
---------------------------- ----------
dba_hist_sysmetric_summary select
v_$sysmetric_history select创建视图“arp_in_last_1_hour”,代码如下所示:
prompt ===========================================
prompt average runnable processes in last 1 hour
pormpt ===========================================
set linesize 200
set pagesize 300
column sample_time format a12
column metric_name format a25
column value format 999,999.99
--
-- creating a view named "arp_in_last_1_hour" to show "sample_time" and "value" based on
-- the four metrics amongst "instance foreground cpu", "instance background cpu",
-- "non-database host cpu" and "load average" from v$sysmetric_history in last 1 hour.
--
create or replace view arp_in_last_1_hour
as
with
ins_fg_cpu as
(
select to_char(end_time, 'hh24:mi:ss') sample_time
, decode(metric_name, 'cpu usage per sec', 'instance foreground cpu') metric_name
, round(value/1e2, 2) value
from v$sysmetric_history
where metric_name = 'cpu usage per sec'
and group_id = 2
and end_time >= sysdate - interval '60' minute
order by sample_time
),
ins_bg_cpu as
(
select to_char(end_time, 'hh24:mi:ss') sample_time
, decode(metric_name, 'background cpu usage per sec', 'instance background cpu') metric_name
, round(value/1e2, 2) value
from v$sysmetric_history
where metric_name = 'background cpu usage per sec'
and group_id = 2
and end_time >= sysdate - interval '60' minute
order by sample_time
),
host_cpu as
(
select to_char(end_time, 'hh24:mi:ss') sample_time
, decode(metric_name, 'host cpu usage per sec', 'host cpu') metric_name
, round(value/1e2, 2) value
from v$sysmetric_history
where metric_name = 'host cpu usage per sec'
and group_id = 2
and end_time >= sysdate - interval '60' minute
order by sample_time
),
non_db_host_cpu as
(
select hc.sample_time
, 'non-database host cpu' metric_name
, hc.value - fc.value - bc.value value
from host_cpu hc
, ins_fg_cpu fc
, ins_bg_cpu bc
where hc.sample_time = fc.sample_time
and fc.sample_time = bc.sample_time
order by hc.sample_time
),
load_average as
(
select to_char(end_time, 'hh24:mi:ss') sample_time
, decode(metric_name, 'current os load', 'load average') metric_name
, round(value, 2) value
from v$sysmetric_history
where metric_name = 'current os load'
and group_id = 2
and end_time >= sysdate - interval '60' minute
order by sample_time
)
select * from ins_fg_cpu
union all
select * from ins_bg_cpu
union all
select * from non_db_host_cpu
union all
select * from load_average
;我们通过创建一个存储过程“pro_convert_rows_to_columns”对视图“arp_in_last_1_hour”进行“动态行转列”操作,然后再创建另一个视图“arp_in_last_1_hour_result”来保存前面的操作结果,这两步操作都在“同一存储过程”里完成,详见如下代码:
--
-- creating a procedure named "pro_convert_rows_to_columns" to dynamically convert "sample_time"
-- from rows to columns based on the previous view "arp_in_last_1_hour".
--
create or replace procedure pro_convert_rows_to_columns
authid current_user
is
v_sql varchar2(4000);
cursor cur_samp_time is
select sample_time
from arp_in_last_1_hour
where metric_name = 'instance foreground cpu'
order by sample_time;
begin
v_sql := q'[select metric_name]';
for v_samp_time in cur_samp_time
loop
v_sql := v_sql || q'[, max(decode(sample_time, ']'
|| v_samp_time.sample_time
|| q'[', value)) as "]'
|| v_samp_time.sample_time
|| q'["]';
end loop;
v_sql := v_sql || q'[ from arp_in_last_1_hour group by metric_name]'
|| q'[ order by decode(metric_name,]'
|| q'[ 'instance foreground cpu', 1]'
|| q'[, 'instance background cpu', 2]'
|| q'[, 'non-database host cpu' , 3]'
|| q'[, 'load average' , 4]'
|| q'[)]';
v_sql := 'create or replace view arp_in_last_1_hour_result as ' || v_sql;
execute immediate v_sql;
end;
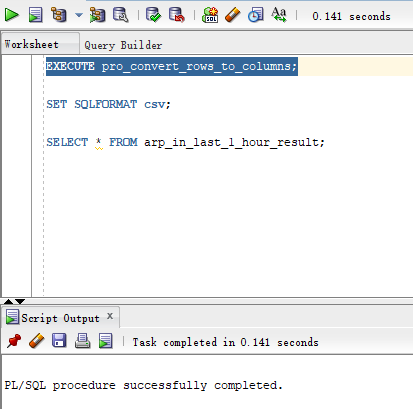
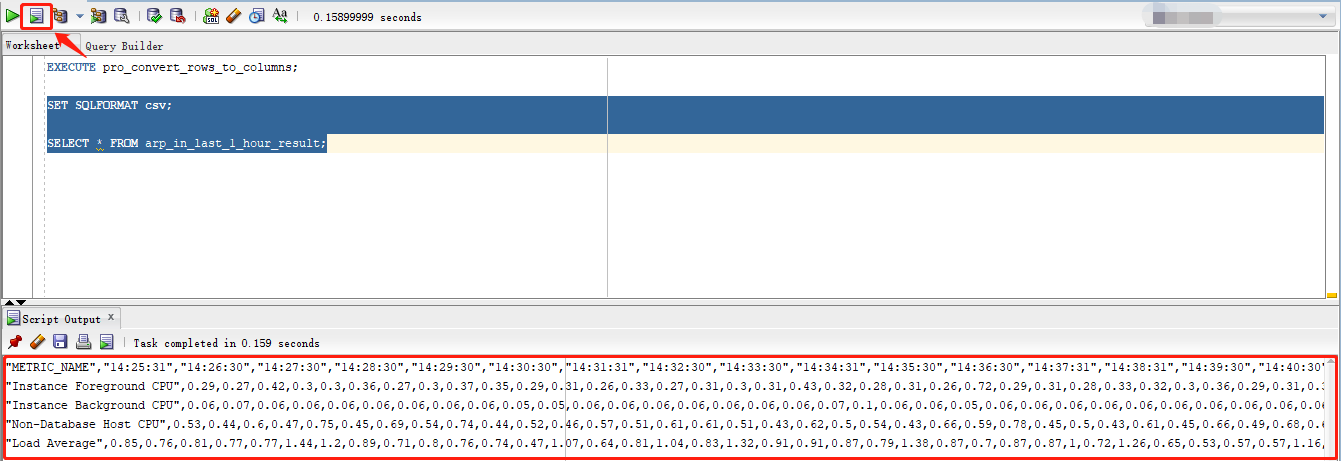
/执行创建成功的存储过程“pro_convert_rows_to_columns”并查询创建成功的视图“arp_in_last_1_hour_result”,具体代码是这样的:
--
-- running the previous procedure "pro_convert_rows_to_columns" to create view
-- "arp_in_last_1_hour_result" to save the result of converting rows to columns dynamically.
--
-- firstly executing "set sqlformat csv" on oracle sql developer 21.2 next running the following sql query
-- by clicking the button of "run script" or pressing f5 to show the csv format, finally save this csv file
-- "arp_1.csv" to your local computer.
--
execute pro_convert_rows_to_columns;
set sqlformat csv;
select * from arp_in_last_1_hour_result;操作步骤详见如下两图:
此时,csv文件“arp_1.csv”已经保存到我的本地电脑。接下来,我们将其导入到excel,通过简单的几步导入操作之后,我们最终需要的excel数据表就生成了。操作步骤依次请看下面八张相应的屏幕截图:
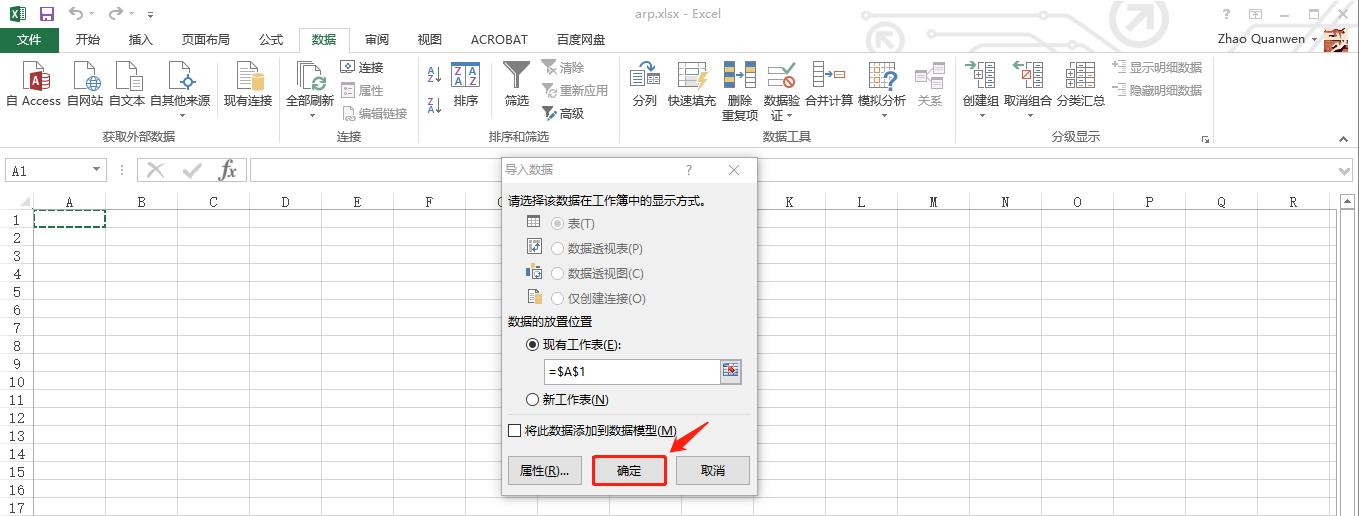
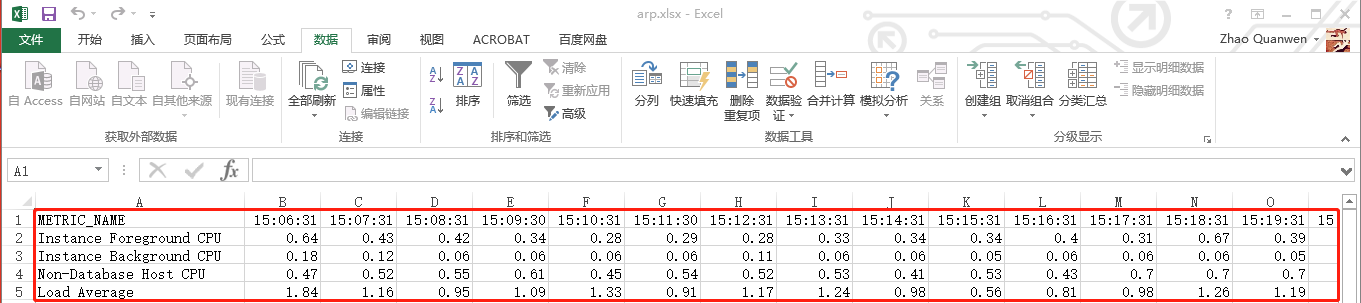
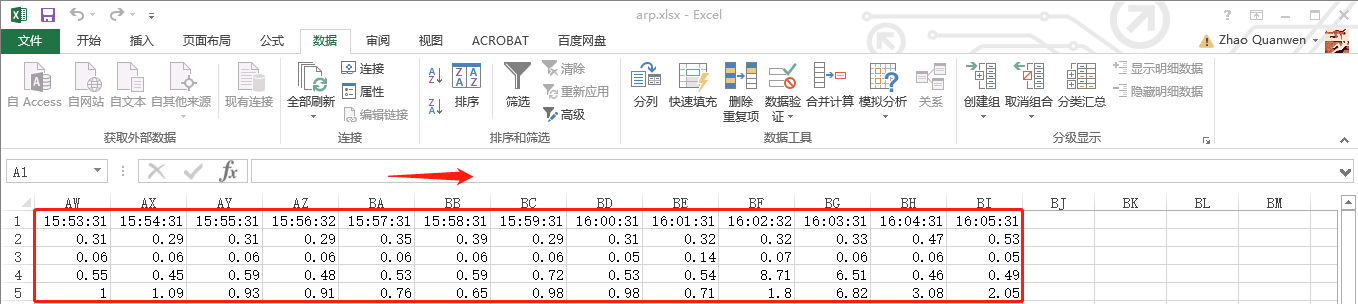
下一步,我们给excel数据表的所在边框加一个框线并用“鼠标选中”整个表,然后去创建我们期盼已久的“组合图”(“面积堆叠图”和“折线图”),操作步骤依次详见如下五张屏幕截图:
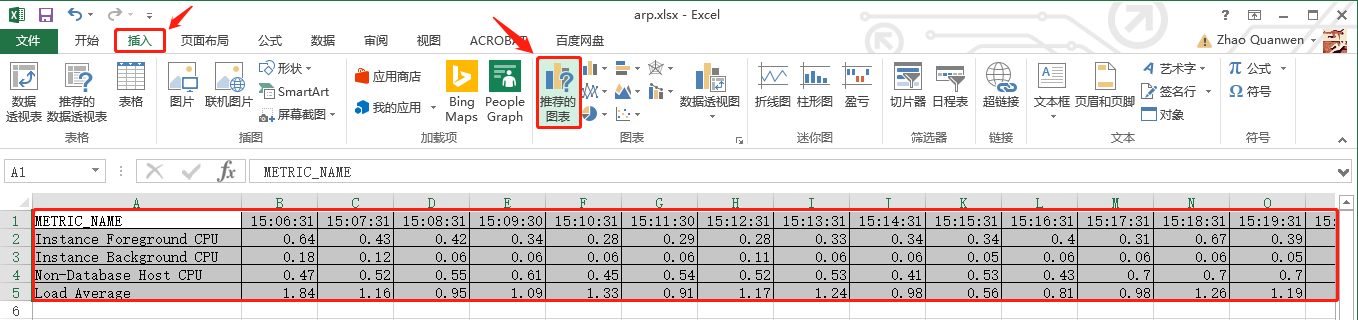
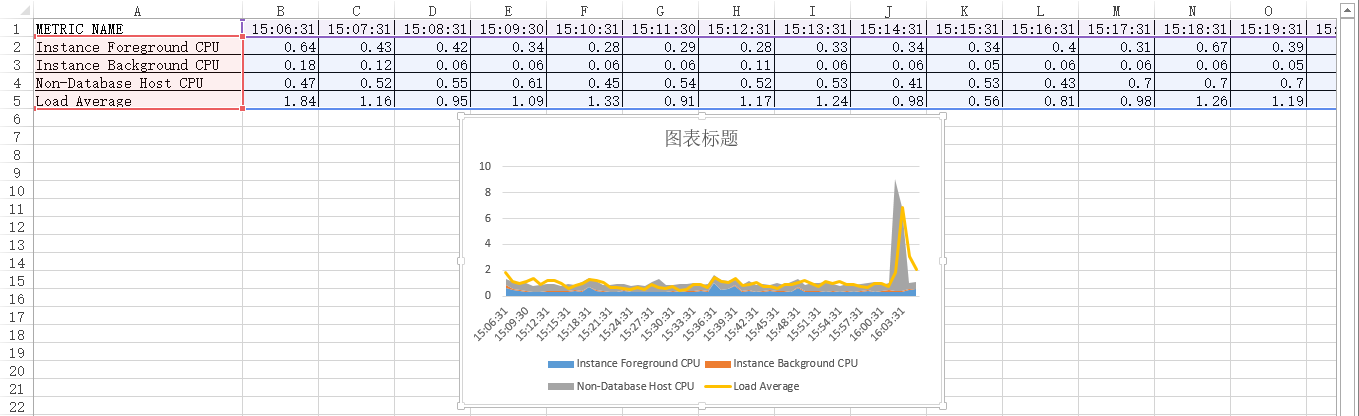
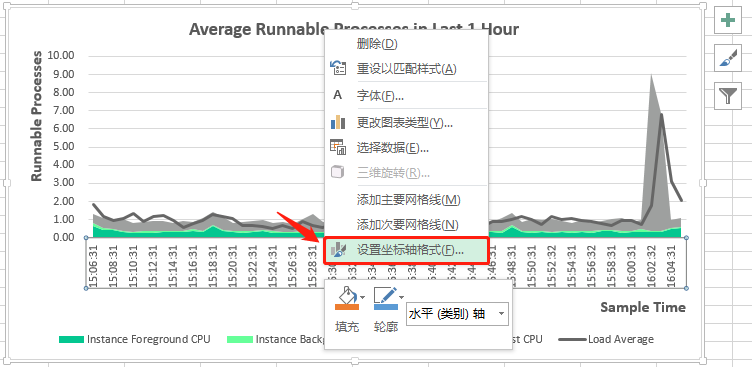
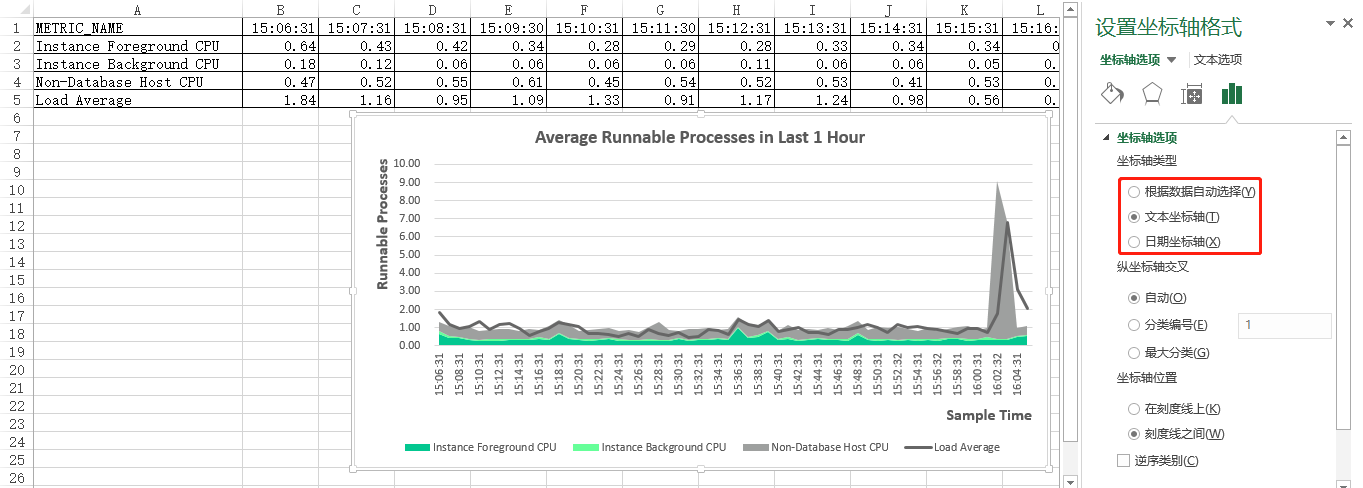
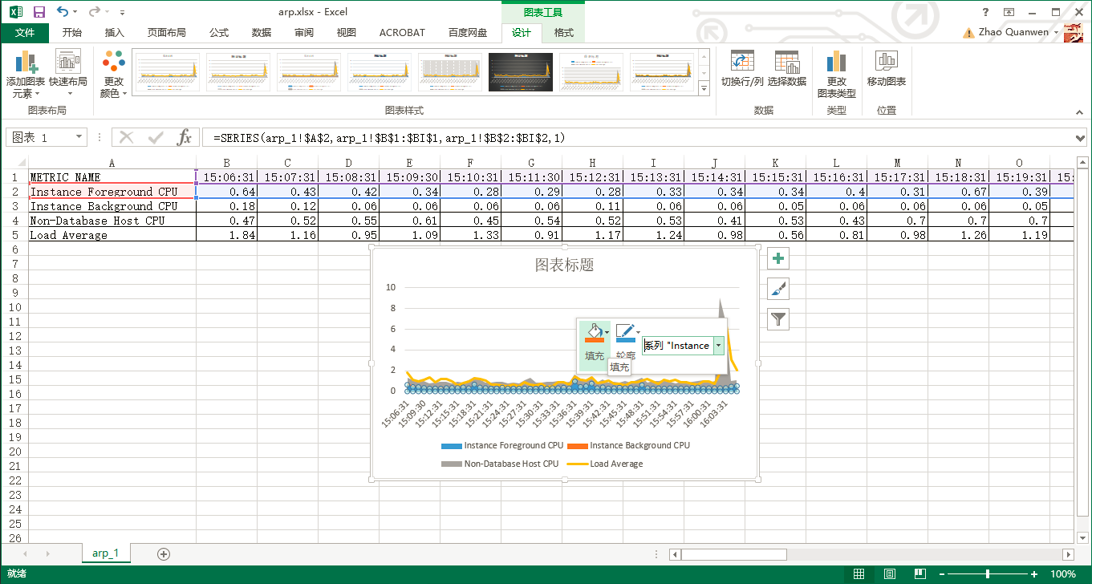
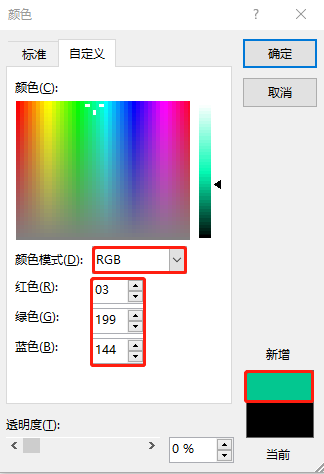
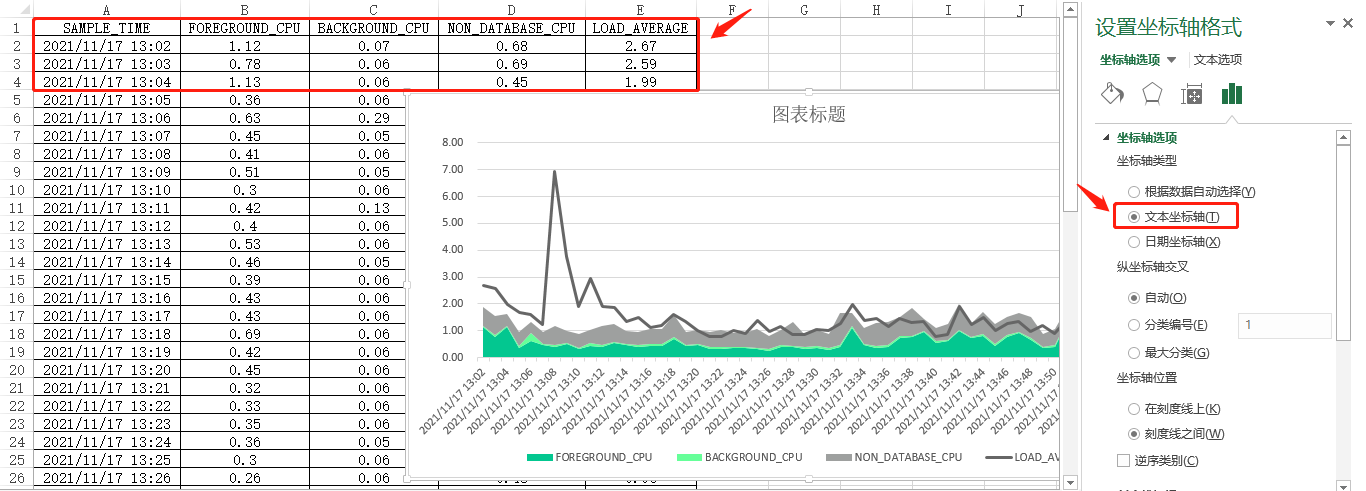
到这里,最近1小时的平均可运行进程的可视化图表(“组合图”)就生成了。接着,进行几步快速地设置,如:添加“图表标题”,显示并添加“横/纵坐标轴标题”,设置纵轴值的显示方式为“数字”并保留“两位小数”,设置“横”坐标轴类型为“文本坐标轴”,调整“三个cpu”图例的“填充颜色”和“平均负载”图例的“轮廓颜色”(用鼠标左键选择每个图例的所在区域,然后点击鼠标右键弹出颜色设置菜单),详见如下十张屏幕截图:
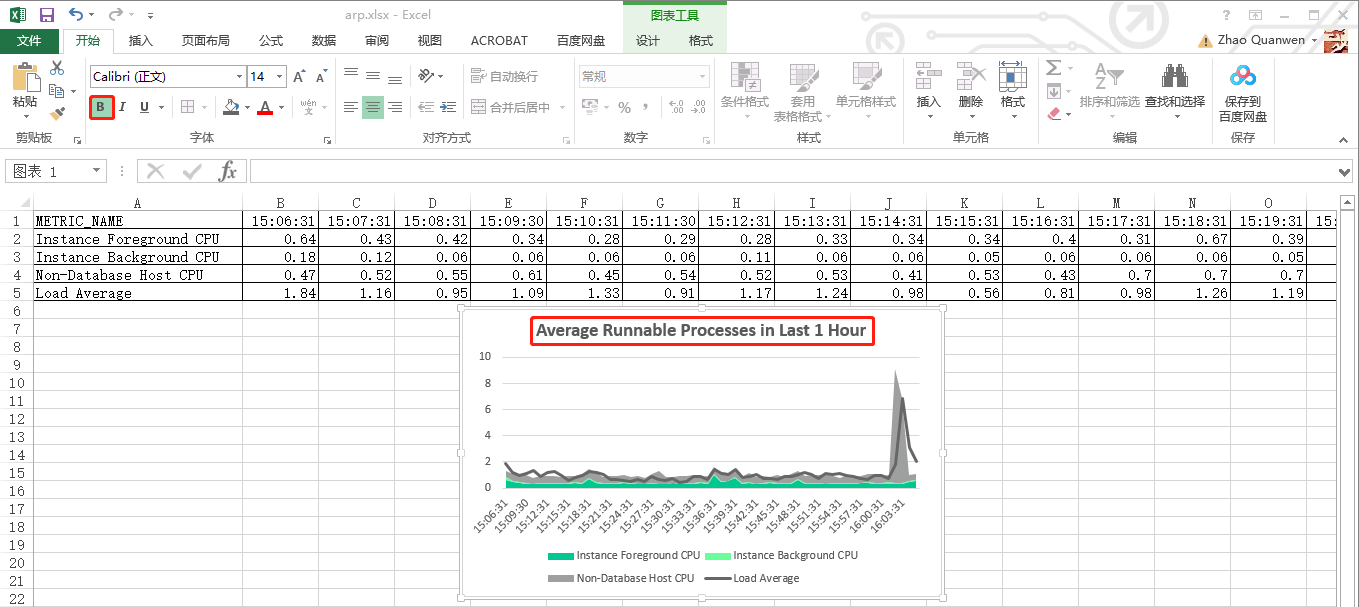
那么,我们对比一下emcc 13.5中的“最近1小时(同一时间段)”的平均可运行进程的图表,见下图:

完美,从整个图表数据的趋势来看,应该是基本一致的,哈哈!!!
最近24小时的平均可运行进程
因为阐述上一个维度的“平均可运行进程”图表可视化花了大量的篇幅,所以针对后面这七个维度的图表可视化,我将如法炮制,在此省略基本的操作步骤,所有代码依次为:
prompt =============================================
prompt average runnable processes in last 24 hours
pormpt =============================================
set linesize 200
set pagesize 300
column sample_time format a20
column metric_name format a25
column value format 999,999.99
--
-- creating a view named "arp_in_last_24_hours" to show "sample_time" and "value" based on
-- the four metrics amongst "instance foreground cpu", "instance background cpu",
-- "non-database host cpu" and "load average" from dba_hist_sysmetric_summary in last 24 hours.
--
create or replace view arp_in_last_24_hours
as
with
ins_fg_cpu as
(
select to_char(end_time, 'yyyy-mm-dd hh24:mi') sample_time
, decode(metric_name, 'cpu usage per sec', 'instance foreground cpu') metric_name
, round(average/1e2, 2) value
from dba_hist_sysmetric_summary
where metric_name = 'cpu usage per sec'
and group_id = 2
and end_time >= sysdate - interval '24' hour
order by sample_time
),
ins_bg_cpu as
(
select to_char(end_time, 'yyyy-mm-dd hh24:mi') sample_time
, decode(metric_name, 'background cpu usage per sec', 'instance background cpu') metric_name
, round(average/1e2, 2) value
from dba_hist_sysmetric_summary
where metric_name = 'background cpu usage per sec'
and group_id = 2
and end_time >= sysdate - interval '24' hour
order by sample_time
),
host_cpu as
(
select to_char(end_time, 'yyyy-mm-dd hh24:mi') sample_time
, decode(metric_name, 'host cpu usage per sec', 'host cpu') metric_name
, round(average/1e2, 2) value
from dba_hist_sysmetric_summary
where metric_name = 'host cpu usage per sec'
and group_id = 2
and end_time >= sysdate - interval '24' hour
order by sample_time
),
non_db_host_cpu as
(
select hc.sample_time
, 'non-database host cpu' metric_name
, hc.value - fc.value - bc.value value
from host_cpu hc
, ins_fg_cpu fc
, ins_bg_cpu bc
where hc.sample_time = fc.sample_time
and fc.sample_time = bc.sample_time
order by hc.sample_time
),
load_average as
(
select to_char(end_time, 'yyyy-mm-dd hh24:mi') sample_time
, decode(metric_name, 'current os load', 'load average') metric_name
, round(average, 2) value
from dba_hist_sysmetric_summary
where metric_name = 'current os load'
and group_id = 2
and end_time >= sysdate - interval '24' hour
order by sample_time
)
select * from ins_fg_cpu
union all
select * from ins_bg_cpu
union all
select * from non_db_host_cpu
union all
select * from load_average
;--
-- creating a procedure named "pro_convert_rows_to_columns_2" to dynamically convert "sample_time"
-- from rows to columns based on the previous view "arp_in_last_24_hours".
--
create or replace procedure pro_convert_rows_to_columns_2
authid current_user
is
v_sql varchar2(4000);
cursor cur_samp_time is
select sample_time
from arp_in_last_24_hours
where metric_name = 'instance foreground cpu'
order by sample_time;
begin
v_sql := q'[select metric_name]';
for v_samp_time in cur_samp_time
loop
v_sql := v_sql || q'[, max(decode(sample_time, ']'
|| v_samp_time.sample_time
|| q'[', value)) as "]'
|| v_samp_time.sample_time
|| q'["]';
end loop;
v_sql := v_sql || q'[ from arp_in_last_24_hours group by metric_name]'
|| q'[ order by decode(metric_name,]'
|| q'[ 'instance foreground cpu', 1]'
|| q'[, 'instance background cpu', 2]'
|| q'[, 'non-database host cpu' , 3]'
|| q'[, 'load average' , 4]'
|| q'[)]';
v_sql := 'create or replace view arp_in_last_24_hours_result as ' || v_sql;
execute immediate v_sql;
end;
/--
-- running the previous procedure "pro_convert_rows_to_columns_2" to create view
-- "arp_in_last_24_hours_result" to save the result of converting rows to columns dynamically.
--
-- firstly executing "set sqlformat csv" on oracle sql developer 21.2 next running the following sql query
-- by clicking the button of "run script" or pressing f5 to show the csv format, finally save this csv file
-- "arp_2.csv" to your local computer.
--
execute pro_convert_rows_to_columns_2;
set sqlformat csv;
select * from arp_in_last_24_hours_result;最终的图表效果见下图:

最近7天的平均可运行进程(按每小时间隔)
同理,详见所有sql代码:
prompt ===================================================================
prompt average runnable processes in last 7 days (interval by each hour)
pormpt ===================================================================
set linesize 200
set pagesize 700
column sample_time format a20
column metric_name format a25
column value format 999,999.99
--
-- creating a view named "arp_in_last_7_days" to show "sample_time" and "value" based on
-- the four metrics amongst "instance foreground cpu", "instance background cpu",
-- "non-database host cpu" and "load average" from dba_hist_sysmetric_summary
-- in last 7 days (interval by each hour).
--
create or replace view arp_in_last_7_days
as
with
ins_fg_cpu as
(
select to_char(end_time, 'yyyy-mm-dd hh24:mi') sample_time
, decode(metric_name, 'cpu usage per sec', 'instance foreground cpu') metric_name
, round(average/1e2, 2) value
from dba_hist_sysmetric_summary
where metric_name = 'cpu usage per sec'
and group_id = 2
and end_time >= sysdate - interval '6' day
order by sample_time
),
ins_bg_cpu as
(
select to_char(end_time, 'yyyy-mm-dd hh24:mi') sample_time
, decode(metric_name, 'background cpu usage per sec', 'instance background cpu') metric_name
, round(average/1e2, 2) value
from dba_hist_sysmetric_summary
where metric_name = 'background cpu usage per sec'
and group_id = 2
and end_time >= sysdate - interval '6' day
order by sample_time
),
host_cpu as
(
select to_char(end_time, 'yyyy-mm-dd hh24:mi') sample_time
, decode(metric_name, 'host cpu usage per sec', 'host cpu') metric_name
, round(average/1e2, 2) value
from dba_hist_sysmetric_summary
where metric_name = 'host cpu usage per sec'
and group_id = 2
and end_time >= sysdate - interval '6' day
order by sample_time
),
non_db_host_cpu as
(
select hc.sample_time
, 'non-database host cpu' metric_name
, hc.value - fc.value - bc.value value
from host_cpu hc
, ins_fg_cpu fc
, ins_bg_cpu bc
where hc.sample_time = fc.sample_time
and fc.sample_time = bc.sample_time
order by hc.sample_time
),
load_average as
(
select to_char(end_time, 'yyyy-mm-dd hh24:mi') sample_time
, decode(metric_name, 'current os load', 'load average') metric_name
, round(average, 2) value
from dba_hist_sysmetric_summary
where metric_name = 'current os load'
and group_id = 2
and end_time >= sysdate - interval '6' day
order by sample_time
)
select * from ins_fg_cpu
union all
select * from ins_bg_cpu
union all
select * from non_db_host_cpu
union all
select * from load_average
;--
-- creating a procedure named "pro_convert_rows_to_columns_3" to dynamically convert "sample_time"
-- from rows to columns based on the previous view "arp_in_last_7_days".
--
create or replace procedure pro_convert_rows_to_columns_3
authid current_user
is
v_sql clob;
cursor cur_samp_time is
select sample_time
from arp_in_last_7_days
where metric_name = 'instance foreground cpu'
order by sample_time;
begin
v_sql := q'[select metric_name]';
for v_samp_time in cur_samp_time
loop
v_sql := v_sql || q'[, max(decode(sample_time, ']'
|| v_samp_time.sample_time
|| q'[', value)) as "]'
|| v_samp_time.sample_time
|| q'["]';
end loop;
v_sql := v_sql || q'[ from arp_in_last_7_days group by metric_name]'
|| q'[ order by decode(metric_name,]'
|| q'[ 'instance foreground cpu', 1]'
|| q'[, 'instance background cpu', 2]'
|| q'[, 'non-database host cpu' , 3]'
|| q'[, 'load average' , 4]'
|| q'[)]';
v_sql := 'create or replace view arp_in_last_7_days_result as ' || v_sql;
execute immediate v_sql;
end;
/--
-- running the previous procedure "pro_convert_rows_to_columns_3" to create view
-- "arp_in_last_7_days_result" to save the result of converting rows to columns dynamically.
--
-- firstly executing "set sqlformat csv" on oracle sql developer 21.2 next running the following sql query
-- by clicking the button of "run script" or pressing f5 to show the csv format, finally save this csv file
-- "arp_3.csv" to your local computer.
--
execute pro_convert_rows_to_columns_3;
set sqlformat csv;
select * from arp_in_last_7_days_result;最后生成的图表见下图:
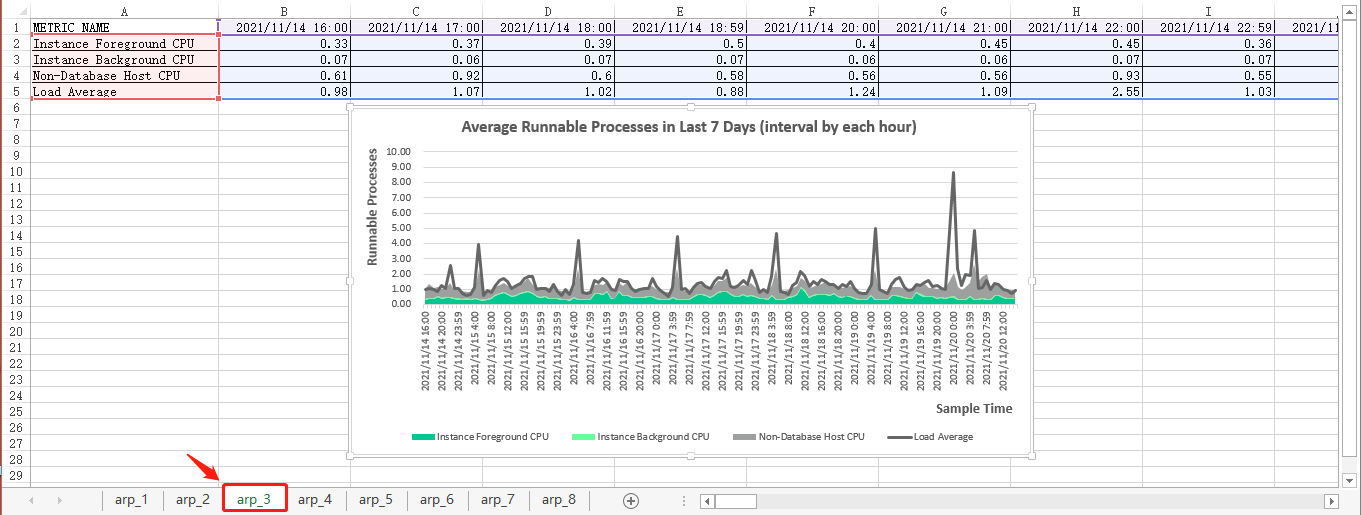
最近7天的平均可运行进程(按每天间隔)
该维度的所有sql代码如下所示:
prompt ==================================================================
prompt average runnable processes in last 7 days (interval by each day)
pormpt ==================================================================
set linesize 200
set pagesize 100
column sample_time format a12
column metric_name format a25
column value format 999,999.99
--
-- creating a view named "arp_in_last_7_days_2" to show "sample_time" and "value" based on
-- the four metrics amongst "instance foreground cpu", "instance background cpu",
-- "non-database host cpu" and "load average" based on the view "arp_in_last_7_days"
-- in last 7 days (interval by each day).
--
create or replace view arp_in_last_7_days_2
as
select to_char(to_date(sample_time, 'yyyy-mm-dd hh24:mi'), 'yyyy-mm-dd') sample_time
, metric_name
, round(avg(value), 2) value
from arp_in_last_7_days
group by to_char(to_date(sample_time, 'yyyy-mm-dd hh24:mi'), 'yyyy-mm-dd')
, metric_name
order by decode(metric_name, 'instance foreground cpu', 1
, 'instance background cpu', 2
, 'non-database host cpu' , 3
, 'load average' , 4
)
, sample_time
;--
-- creating a procedure named "pro_convert_rows_to_columns_4" to dynamically convert "sample_time"
-- from rows to columns based on the previous view "arp_in_last_7_days_2".
--
create or replace procedure pro_convert_rows_to_columns_4
authid current_user
is
v_sql varchar2(4000);
cursor cur_samp_time is
select sample_time
from arp_in_last_7_days_2
where metric_name = 'instance foreground cpu'
order by sample_time;
begin
v_sql := q'[select metric_name]';
for v_samp_time in cur_samp_time
loop
v_sql := v_sql || q'[, max(decode(sample_time, ']'
|| v_samp_time.sample_time
|| q'[', value)) as "]'
|| v_samp_time.sample_time
|| q'["]';
end loop;
v_sql := v_sql || q'[ from arp_in_last_7_days_2 group by metric_name]'
|| q'[ order by decode(metric_name,]'
|| q'[ 'instance foreground cpu', 1]'
|| q'[, 'instance background cpu', 2]'
|| q'[, 'non-database host cpu' , 3]'
|| q'[, 'load average' , 4]'
|| q'[)]';
v_sql := 'create or replace view arp_in_last_7_days_2_result as ' || v_sql;
execute immediate v_sql;
end;
/--
-- running the previous procedure "pro_convert_rows_to_columns_4" to create view
-- "arp_in_last_7_days_2_result" to save the result of converting rows to columns dynamically.
--
-- firstly executing "set sqlformat csv" on oracle sql developer 21.2 next running the following sql query
-- by clicking the button of "run script" or pressing f5 to show the csv format, finally save this csv file
-- "arp_4.csv" to your local computer.
--
execute pro_convert_rows_to_columns_4;
set sqlformat csv;
select * from arp_in_last_7_days_2_result;最终生成的可视化图表是下面的效果图:
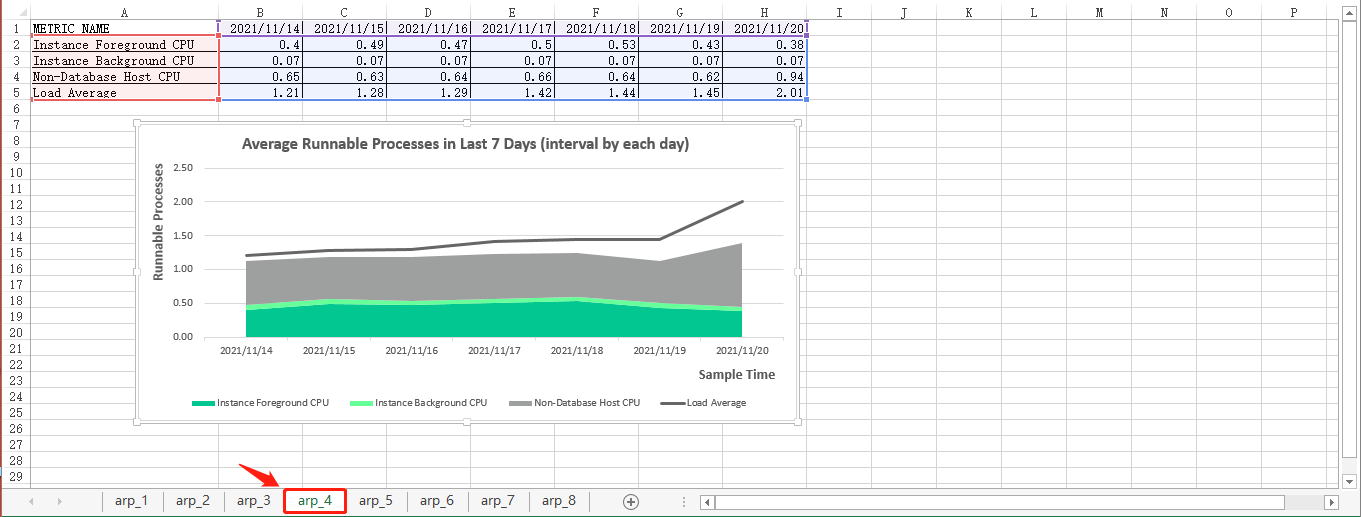
最近31天的平均可运行进程(按每小时间隔)
相应的sql代码如下所示:
prompt ====================================================================
prompt average runnable processes in last 31 days (interval by each hour)
pormpt ====================================================================
set linesize 200
set pagesize 3000
column sample_time format a20
column metric_name format a25
column value format 999,999.99
--
-- creating a view named "arp_in_last_31_days" to show "sample_time" and "value" based on
-- the four metrics amongst "instance foreground cpu", "instance background cpu",
-- "non-database host cpu" and "load average" from dba_hist_sysmetric_summary
-- in last 31 days (interval by each hour).
--
create or replace view arp_in_last_31_days
as
with
ins_fg_cpu as
(
select to_char(end_time, 'yyyy-mm-dd hh24:mi') sample_time
, decode(metric_name, 'cpu usage per sec', 'instance foreground cpu') metric_name
, round(average/1e2, 2) value
from dba_hist_sysmetric_summary
where metric_name = 'cpu usage per sec'
and group_id = 2
and end_time >= sysdate - interval '30' day
order by sample_time
),
ins_bg_cpu as
(
select to_char(end_time, 'yyyy-mm-dd hh24:mi') sample_time
, decode(metric_name, 'background cpu usage per sec', 'instance background cpu') metric_name
, round(average/1e2, 2) value
from dba_hist_sysmetric_summary
where metric_name = 'background cpu usage per sec'
and group_id = 2
and end_time >= sysdate - interval '30' day
order by sample_time
),
host_cpu as
(
select to_char(end_time, 'yyyy-mm-dd hh24:mi') sample_time
, decode(metric_name, 'host cpu usage per sec', 'host cpu') metric_name
, round(average/1e2, 2) value
from dba_hist_sysmetric_summary
where metric_name = 'host cpu usage per sec'
and group_id = 2
and end_time >= sysdate - interval '30' day
order by sample_time
),
non_db_host_cpu as
(
select hc.sample_time
, 'non-database host cpu' metric_name
, hc.value - fc.value - bc.value value
from host_cpu hc
, ins_fg_cpu fc
, ins_bg_cpu bc
where hc.sample_time = fc.sample_time
and fc.sample_time = bc.sample_time
order by hc.sample_time
),
load_average as
(
select to_char(end_time, 'yyyy-mm-dd hh24:mi') sample_time
, decode(metric_name, 'current os load', 'load average') metric_name
, round(average, 2) value
from dba_hist_sysmetric_summary
where metric_name = 'current os load'
and group_id = 2
and end_time >= sysdate - interval '30' day
order by sample_time
)
select * from ins_fg_cpu
union all
select * from ins_bg_cpu
union all
select * from non_db_host_cpu
union all
select * from load_average
;--
-- creating a procedure named "pro_convert_rows_to_columns_5" to dynamically convert "sample_time"
-- from rows to columns based on the previous view "arp_in_last_31_days".
--
create or replace procedure pro_convert_rows_to_columns_5
authid current_user
is
v_sql clob;
cursor cur_samp_time is
select sample_time
from arp_in_last_31_days
where metric_name = 'instance foreground cpu'
order by sample_time;
begin
v_sql := q'[select metric_name]';
for v_samp_time in cur_samp_time
loop
v_sql := v_sql || q'[, max(decode(sample_time, ']'
|| v_samp_time.sample_time
|| q'[', value)) as "]'
|| v_samp_time.sample_time
|| q'["]';
end loop;
v_sql := v_sql || q'[ from arp_in_last_31_days group by metric_name]'
|| q'[ order by decode(metric_name,]'
|| q'[ 'instance foreground cpu', 1]'
|| q'[, 'instance background cpu', 2]'
|| q'[, 'non-database host cpu' , 3]'
|| q'[, 'load average' , 4]'
|| q'[)]';
v_sql := 'create or replace view arp_in_last_31_days_result as ' || v_sql;
execute immediate v_sql;
end;
/--
-- running the previous procedure "pro_convert_rows_to_columns_5" to create view
-- "arp_in_last_31_days_result" to save the result of converting rows to columns dynamically.
--
-- firstly executing "set sqlformat csv" on oracle sql developer 21.2 next running the following sql query
-- by clicking the button of "run script" or pressing f5 to show the csv format, finally save this csv file
-- "arp_5.csv" to your local computer.
--
execute pro_convert_rows_to_columns_5;
set sqlformat csv;
select * from arp_in_last_31_days_result;经过一系列的操作步骤之后(详见第一维度,这里省略。。。),最终展现出来的图表为:
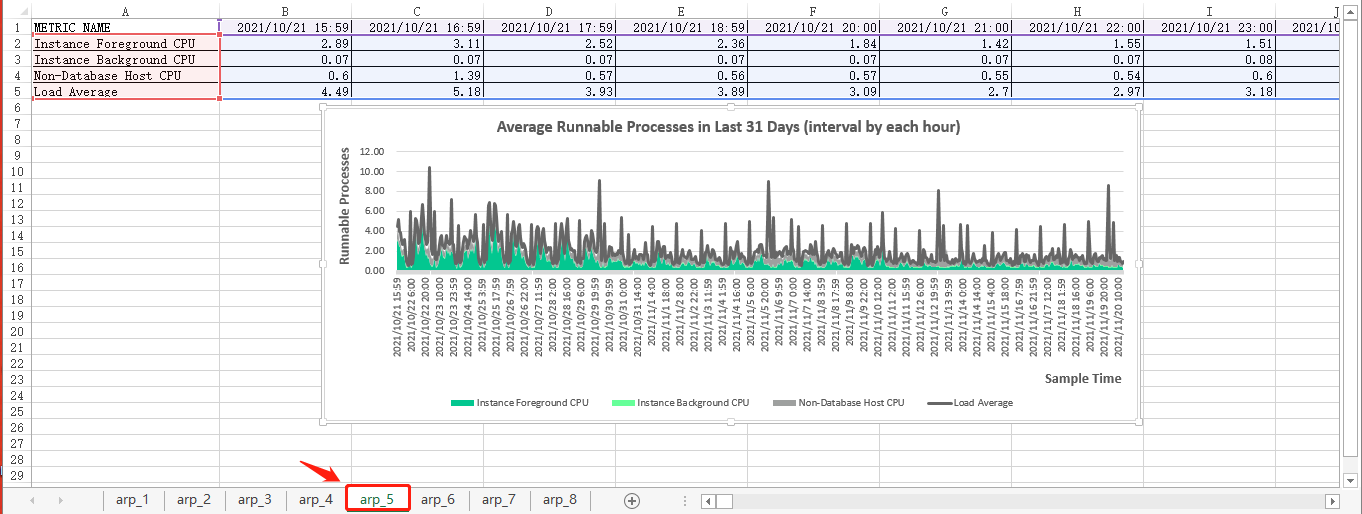
最近31天的平均可运行进程(按每天间隔)
同理,所有的sql代码如下所示:
prompt ===================================================================
prompt average runnable processes in last 31 days (interval by each day)
pormpt ===================================================================
set linesize 200
set pagesize 100
column sample_time format a12
column metric_name format a25
column value format 999,999.99
--
-- creating a view named "arp_in_last_31_days_2" to show "sample_time" and "value" based on
-- the four metrics amongst "instance foreground cpu", "instance background cpu",
-- "non-database host cpu" and "load average" based on the view "arp_in_last_31_days"
-- in last 31 days (interval by each day).
--
create or replace view arp_in_last_31_days_2
as
select to_char(to_date(sample_time, 'yyyy-mm-dd hh24:mi'), 'yyyy-mm-dd') sample_time
, metric_name
, round(avg(value), 2) value
from arp_in_last_31_days
group by to_char(to_date(sample_time, 'yyyy-mm-dd hh24:mi'), 'yyyy-mm-dd')
, metric_name
order by decode(metric_name, 'instance foreground cpu', 1
, 'instance background cpu', 2
, 'non-database host cpu' , 3
, 'load average' , 4
)
, sample_time
;--
-- creating a procedure named "pro_convert_rows_to_columns_6" to dynamically convert "sample_time"
-- from rows to columns based on the previous view "arp_in_last_31_days_2".
--
create or replace procedure pro_convert_rows_to_columns_6
authid current_user
is
v_sql varchar2(4000);
cursor cur_samp_time is
select sample_time
from arp_in_last_31_days_2
where metric_name = 'instance foreground cpu'
order by sample_time;
begin
v_sql := q'[select metric_name]';
for v_samp_time in cur_samp_time
loop
v_sql := v_sql || q'[, max(decode(sample_time, ']'
|| v_samp_time.sample_time
|| q'[', value)) as "]'
|| v_samp_time.sample_time
|| q'["]';
end loop;
v_sql := v_sql || q'[ from arp_in_last_31_days_2 group by metric_name]'
|| q'[ order by decode(metric_name,]'
|| q'[ 'instance foreground cpu', 1]'
|| q'[, 'instance background cpu', 2]'
|| q'[, 'non-database host cpu' , 3]'
|| q'[, 'load average' , 4]'
|| q'[)]';
v_sql := 'create or replace view arp_in_last_31_days_2_result as ' || v_sql;
execute immediate v_sql;
end;
/--
-- running the previous procedure "pro_convert_rows_to_columns_6" to create view
-- "arp_in_last_31_days_2_result" to save the result of converting rows to columns dynamically.
--
-- firstly executing "set sqlformat csv" on oracle sql developer 21.2 next running the following sql query
-- by clicking the button of "run script" or pressing f5 to show the csv format, finally save this csv file
-- "arp_6.csv" to your local computer.
--
execute pro_convert_rows_to_columns_6;
set sqlformat csv;
select * from arp_in_last_31_days_2_result;最后生成的图表见下图:
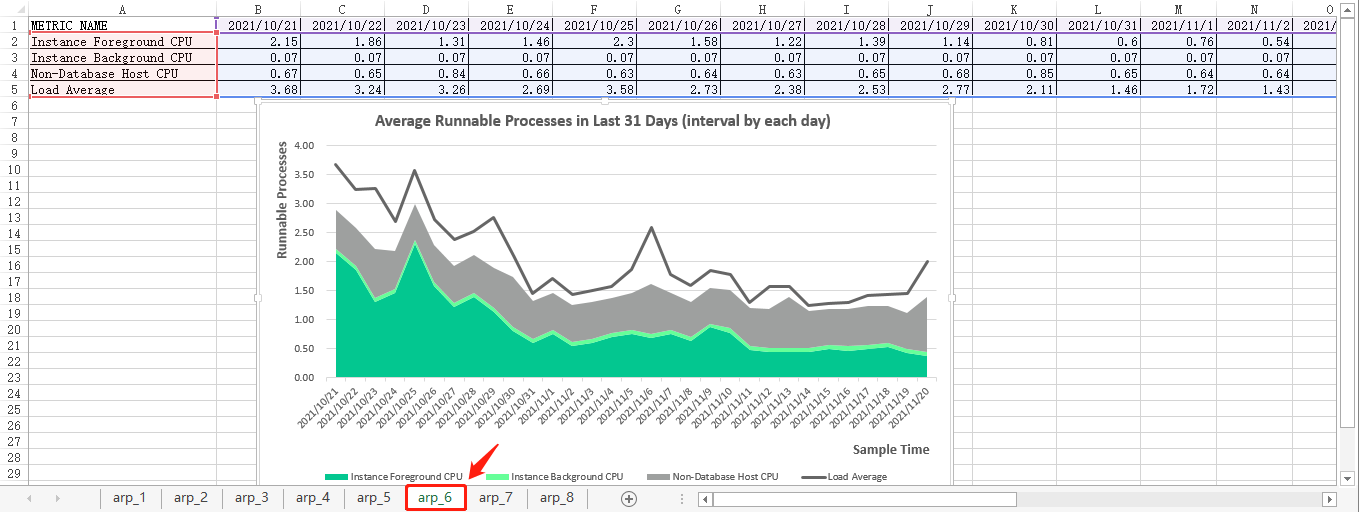
自定义时间段的平均可运行进程(按每小时间隔)
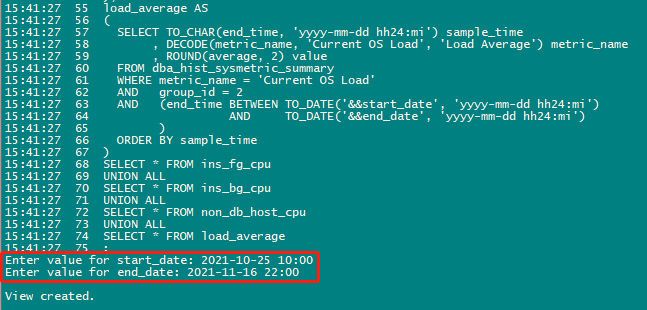
因为这个维度是关于“自定义时间段”,所以在sql*plus中执行代码时,需要手动输入替代变量“开始时间”和“结束时间”之后才能创建成功视图“arp_custom_time_period”。代码部分和输入“替代变量”的操作分别如下所示:
prompt =======================================================================
prompt average runnable processes custom time period (interval by each hour)
pormpt =======================================================================
set verify off
set linesize 200
set pagesize 3000
column sample_time format a20
column metric_name format a25
column value format 999,999.99
--
-- creating a view named "arp_custom_time_period" to show "sample_time" and "value" based on
-- the four metrics amongst "instance foreground cpu", "instance background cpu",
-- "non-database host cpu" and "load average" from dba_hist_sysmetric_summary
-- custom time period (interval by each hour).
--
create or replace view arp_custom_time_period
as
with
ins_fg_cpu as
(
select to_char(end_time, 'yyyy-mm-dd hh24:mi') sample_time
, decode(metric_name, 'cpu usage per sec', 'instance foreground cpu') metric_name
, round(average/1e2, 2) value
from dba_hist_sysmetric_summary
where metric_name = 'cpu usage per sec'
and group_id = 2
and (end_time between to_date('&&start_date', 'yyyy-mm-dd hh24:mi')
and to_date('&&end_date', 'yyyy-mm-dd hh24:mi')
)
order by sample_time
),
ins_bg_cpu as
(
select to_char(end_time, 'yyyy-mm-dd hh24:mi') sample_time
, decode(metric_name, 'background cpu usage per sec', 'instance background cpu') metric_name
, round(average/1e2, 2) value
from dba_hist_sysmetric_summary
where metric_name = 'background cpu usage per sec'
and group_id = 2
and (end_time between to_date('&&start_date', 'yyyy-mm-dd hh24:mi')
and to_date('&&end_date', 'yyyy-mm-dd hh24:mi')
)
order by sample_time
),
host_cpu as
(
select to_char(end_time, 'yyyy-mm-dd hh24:mi') sample_time
, decode(metric_name, 'host cpu usage per sec', 'host cpu') metric_name
, round(average/1e2, 2) value
from dba_hist_sysmetric_summary
where metric_name = 'host cpu usage per sec'
and group_id = 2
and (end_time between to_date('&&start_date', 'yyyy-mm-dd hh24:mi')
and to_date('&&end_date', 'yyyy-mm-dd hh24:mi')
)
order by sample_time
),
non_db_host_cpu as
(
select hc.sample_time
, 'non-database host cpu' metric_name
, hc.value - fc.value - bc.value value
from host_cpu hc
, ins_fg_cpu fc
, ins_bg_cpu bc
where hc.sample_time = fc.sample_time
and fc.sample_time = bc.sample_time
order by hc.sample_time
),
load_average as
(
select to_char(end_time, 'yyyy-mm-dd hh24:mi') sample_time
, decode(metric_name, 'current os load', 'load average') metric_name
, round(average, 2) value
from dba_hist_sysmetric_summary
where metric_name = 'current os load'
and group_id = 2
and (end_time between to_date('&&start_date', 'yyyy-mm-dd hh24:mi')
and to_date('&&end_date', 'yyyy-mm-dd hh24:mi')
)
order by sample_time
)
select * from ins_fg_cpu
union all
select * from ins_bg_cpu
union all
select * from non_db_host_cpu
union all
select * from load_average
;
随后的代码依次为:
--
-- creating a procedure named "pro_convert_rows_to_columns_7" to dynamically convert "sample_time"
-- from rows to columns based on the previous view "arp_custom_time_period".
--
create or replace procedure pro_convert_rows_to_columns_7
authid current_user
is
v_sql clob;
cursor cur_samp_time is
select sample_time
from arp_custom_time_period
where metric_name = 'instance foreground cpu'
order by sample_time;
begin
v_sql := q'[select metric_name]';
for v_samp_time in cur_samp_time
loop
v_sql := v_sql || q'[, max(decode(sample_time, ']'
|| v_samp_time.sample_time
|| q'[', value)) as "]'
|| v_samp_time.sample_time
|| q'["]';
end loop;
v_sql := v_sql || q'[ from arp_custom_time_period group by metric_name]'
|| q'[ order by decode(metric_name,]'
|| q'[ 'instance foreground cpu', 1]'
|| q'[, 'instance background cpu', 2]'
|| q'[, 'non-database host cpu' , 3]'
|| q'[, 'load average' , 4]'
|| q'[)]';
v_sql := 'create or replace view arp_custom_time_period_result as ' || v_sql;
execute immediate v_sql;
end;
/--
-- running the previous procedure "pro_convert_rows_to_columns_7" to create view
-- "arp_custom_time_period_result" to save the result of converting rows to columns dynamically.
--
-- firstly executing "set sqlformat csv" on oracle sql developer 21.2 next running the following sql query
-- by clicking the button of "run script" or pressing f5 to show the csv format, finally save this csv file
-- "arp_7.csv" to your local computer.
--
execute pro_convert_rows_to_columns_7;
set sqlformat csv;
select * from arp_custom_time_period_result;最后的可视化图表是下面这个效果:
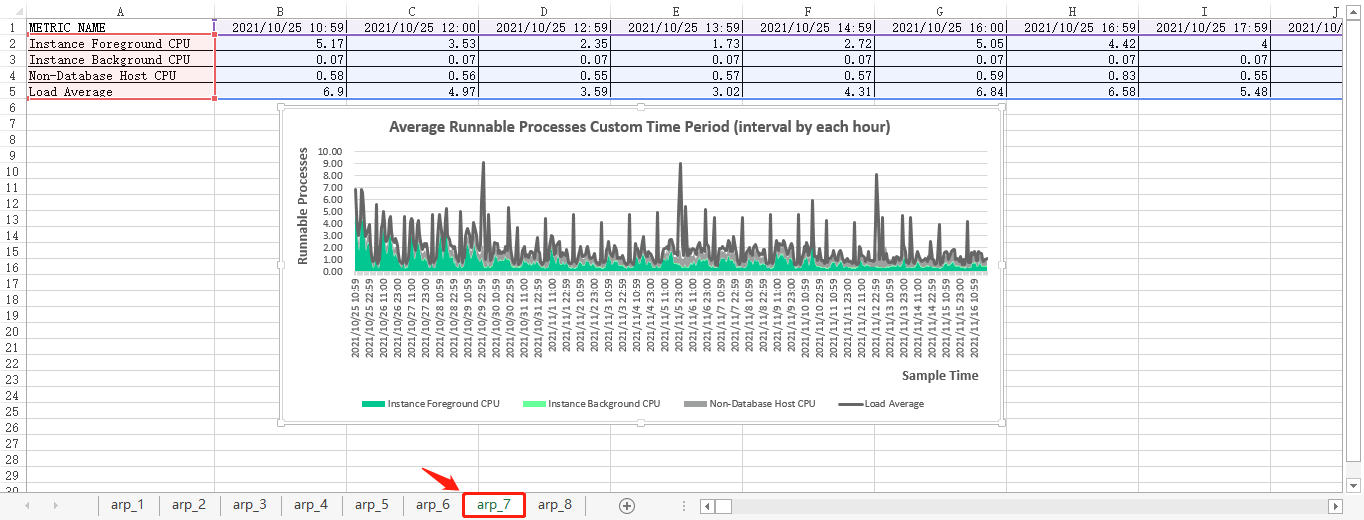
自定义时间段的平均可运行进程(按每天间隔)
同理,所有代码依次为:
prompt ======================================================================
prompt average runnable processes custom time period (interval by each day)
pormpt ======================================================================
set verify off
set linesize 200
set pagesize 100
column sample_time format a12
column metric_name format a25
column value format 999,999.99
--
-- creating a view named "arp_custom_time_period_2" to show "sample_time" and "value" based on
-- the four metrics amongst "instance foreground cpu", "instance background cpu",
-- "non-database host cpu" and "load average" based on the view "arp_custom_time_period"
-- custom time period (interval by each day).
--
create or replace view arp_custom_time_period_2
as
select to_char(to_date(sample_time, 'yyyy-mm-dd hh24:mi'), 'yyyy-mm-dd') sample_time
, metric_name
, round(avg(value), 2) value
from arp_custom_time_period
group by to_char(to_date(sample_time, 'yyyy-mm-dd hh24:mi'), 'yyyy-mm-dd')
, metric_name
order by decode(metric_name, 'instance foreground cpu', 1
, 'instance background cpu', 2
, 'non-database host cpu' , 3
, 'load average' , 4
)
, sample_time
;--
-- creating a procedure named "pro_convert_rows_to_columns_8" to dynamically convert "sample_time"
-- from rows to columns based on the previous view "arp_custom_time_period_2".
--
create or replace procedure pro_convert_rows_to_columns_8
authid current_user
is
v_sql varchar2(4000);
cursor cur_samp_time is
select sample_time
from arp_custom_time_period_2
where metric_name = 'instance foreground cpu'
order by sample_time;
begin
v_sql := q'[select metric_name]';
for v_samp_time in cur_samp_time
loop
v_sql := v_sql || q'[, max(decode(sample_time, ']'
|| v_samp_time.sample_time
|| q'[', value)) as "]'
|| v_samp_time.sample_time
|| q'["]';
end loop;
v_sql := v_sql || q'[ from arp_custom_time_period_2 group by metric_name]'
|| q'[ order by decode(metric_name,]'
|| q'[ 'instance foreground cpu', 1]'
|| q'[, 'instance background cpu', 2]'
|| q'[, 'non-database host cpu' , 3]'
|| q'[, 'load average' , 4]'
|| q'[)]';
v_sql := 'create or replace view arp_custom_time_period_2_res as ' || v_sql;
execute immediate v_sql;
end;
/--
-- running the previous procedure "pro_convert_rows_to_columns_8" to create view
-- "arp_custom_time_period_2_res" to save the result of converting rows to columns dynamically.
--
-- firstly executing "set sqlformat csv" on oracle sql developer 21.2 next running the following sql query
-- by clicking the button of "run script" or pressing f5 to show the csv format, finally save this csv file
-- "arp_8.csv" to your local computer.
--
execute pro_convert_rows_to_columns_8;
set sqlformat csv;
select * from arp_custom_time_period_2_res;最终的可视化图表见下图:
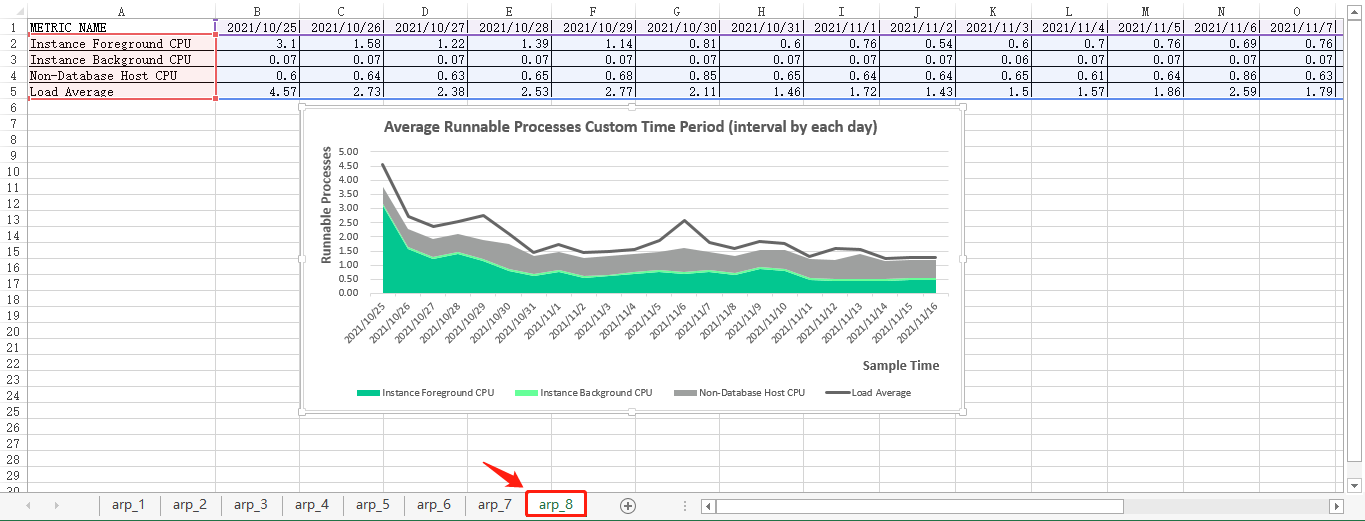
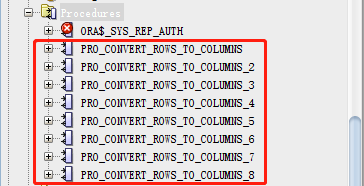
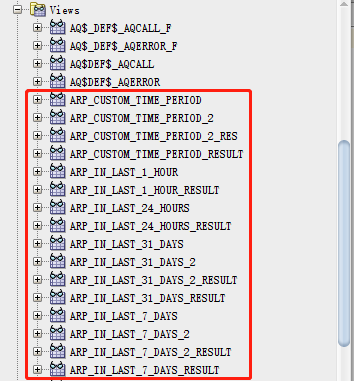
存储过程和视图
将“八个维度”的图表可视化完成以后,全部sql代码生成所有的“存储过程”和“视图”详见下图所示:
至此,可视化oracle性能图表之“平均可运行进程”篇全部分享完毕(另外,您也可以查看我在上的、)。感谢您在百忙之中抽出一点宝贵时间来阅读我的这篇原创文章,欢迎给我任何反馈或提出改进建议!!!
参考文章
更新于 2021年11月23日 上午:
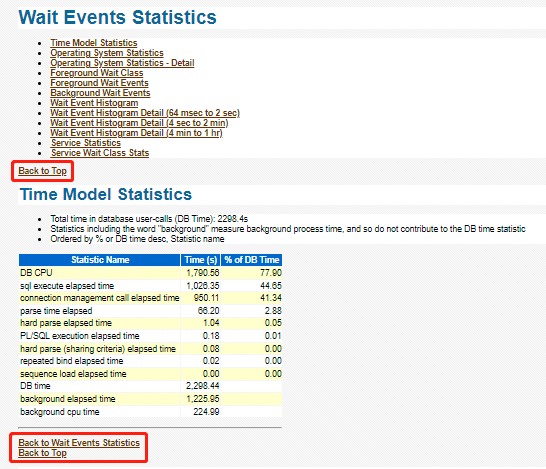
- 在文章每个段落的底部,增加诸如“[返回最近1小时的平均可运行进程]”、“[返回维度目录列表]”、“[返回顶部目录]”的在多段落之间自自跳转的返回链接,这个功能非常棒哟!它类似于“awr报告”中的每个条目底部的“back to the prior parent entry”和“back to top”链接。
更新于 2021年11月25日 中午:
darkathena在评论区给我的回复特别棒,他说在excel中我原先的表格完全可以将x/y轴进行互换(将四个度量名称都放在表头,而采样时间和所有的值放在表的第一列),随后我进行了测试,这是完全可行的,而且也特别简单,这样就可以不用再创建“视图”和“存储过程”,只需将我最初的sql查询进行稍微的改良(这里用到“静态行转列”)就可以快速地导入到excel从而进行图表的可视化操作,如下两图所示:
这里,我使用了经典的行转列函数“max(decode(......)) group by ...”和oracle从11g开始支持的“pivot() / unpivot()”函数这两种方法来进行行转列操作。以“最近1小时的平均可运行进程”这个维度举例来说明:
prompt ===========================================
prompt average runnable processes in last 1 hour
pormpt ===========================================
-- statically converting rows to columns by "max(decode(...)) group by ...".
set linesize 200
set pagesize 300
column sample_time format a11
column metric_name format a25
column value format 999,999.99
with
ins_fg_cpu as
(
select to_char(end_time, 'hh24:mi:ss') sample_time
, decode(metric_name, 'cpu usage per sec', 'instance foreground cpu') metric_name
, round(value/1e2, 2) value
from v$sysmetric_history
where metric_name = 'cpu usage per sec'
and group_id = 2
and end_time >= sysdate - interval '60' minute
order by sample_time
),
ins_bg_cpu as
(
select to_char(end_time, 'hh24:mi:ss') sample_time
, decode(metric_name, 'background cpu usage per sec', 'instance background cpu') metric_name
, round(value/1e2, 2) value
from v$sysmetric_history
where metric_name = 'background cpu usage per sec'
and group_id = 2
and end_time >= sysdate - interval '60' minute
order by sample_time
),
host_cpu as
(
select to_char(end_time, 'hh24:mi:ss') sample_time
, decode(metric_name, 'host cpu usage per sec', 'host cpu') metric_name
, round(value/1e2, 2) value
from v$sysmetric_history
where metric_name = 'host cpu usage per sec'
and group_id = 2
and end_time >= sysdate - interval '60' minute
order by sample_time
),
non_db_host_cpu as
(
select hc.sample_time
, 'non-database host cpu' metric_name
, hc.value - fc.value - bc.value value
from host_cpu hc
, ins_fg_cpu fc
, ins_bg_cpu bc
where hc.sample_time = fc.sample_time
and fc.sample_time = bc.sample_time
order by hc.sample_time
),
load_average as
(
select to_char(end_time, 'hh24:mi:ss') sample_time
, decode(metric_name, 'current os load', 'load average') metric_name
, round(value, 2) value
from v$sysmetric_history
where metric_name = 'current os load'
and group_id = 2
and end_time >= sysdate - interval '60' minute
order by sample_time
),
arp as
(
select * from ins_fg_cpu
union all
select * from ins_bg_cpu
union all
select * from non_db_host_cpu
union all
select * from load_average
)
select sample_time
, max(decode(metric_name, 'instance foreground cpu', value)) "instance foreground cpu"
, max(decode(metric_name, 'instance background cpu', value)) "instance background cpu"
, max(decode(metric_name, 'non-database host cpu' , value)) "non-database host cpu"
, max(decode(metric_name, 'load average' , value)) "load average"
from arp
group by sample_time
order by sample_time
;-- statically converting rows to columns by "select * from table_name pivot (max(column_name_1) for column_name_2 in ())".
set linesize 200
set pagesize 300
column sample_time format a11
column metric_name format a25
column value format 999,999.99
with
ins_fg_cpu as
(
select to_char(end_time, 'hh24:mi:ss') sample_time
, decode(metric_name, 'cpu usage per sec', 'instance foreground cpu') metric_name
, round(value/1e2, 2) value
from v$sysmetric_history
where metric_name = 'cpu usage per sec'
and group_id = 2
and end_time >= sysdate - interval '60' minute
order by sample_time
),
ins_bg_cpu as
(
select to_char(end_time, 'hh24:mi:ss') sample_time
, decode(metric_name, 'background cpu usage per sec', 'instance background cpu') metric_name
, round(value/1e2, 2) value
from v$sysmetric_history
where metric_name = 'background cpu usage per sec'
and group_id = 2
and end_time >= sysdate - interval '60' minute
order by sample_time
),
host_cpu as
(
select to_char(end_time, 'hh24:mi:ss') sample_time
, decode(metric_name, 'host cpu usage per sec', 'host cpu') metric_name
, round(value/1e2, 2) value
from v$sysmetric_history
where metric_name = 'host cpu usage per sec'
and group_id = 2
and end_time >= sysdate - interval '60' minute
order by sample_time
),
non_db_host_cpu as
(
select hc.sample_time
, 'non-database host cpu' metric_name
, hc.value - fc.value - bc.value value
from host_cpu hc
, ins_fg_cpu fc
, ins_bg_cpu bc
where hc.sample_time = fc.sample_time
and fc.sample_time = bc.sample_time
order by hc.sample_time
),
load_average as
(
select to_char(end_time, 'hh24:mi:ss') sample_time
, decode(metric_name, 'current os load', 'load average') metric_name
, round(value, 2) value
from v$sysmetric_history
where metric_name = 'current os load'
and group_id = 2
and end_time >= sysdate - interval '60' minute
order by sample_time
),
arp as
(
select * from ins_fg_cpu
union all
select * from ins_bg_cpu
union all
select * from non_db_host_cpu
union all
select * from load_average
)
select *
from arp
pivot ( max(value)
for metric_name in
( 'instance foreground cpu' as "instance foreground cpu"
, 'instance background cpu' as "instance background cpu"
, 'non-database host cpu' as "non-database host cpu"
, 'load average' as "load average"
)
)
order by sample_time
;其余七个维度的sql代码请查看,因此不再贴出。
更新于 2021年11月30日 下午:
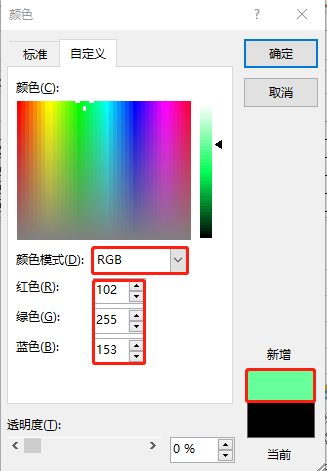
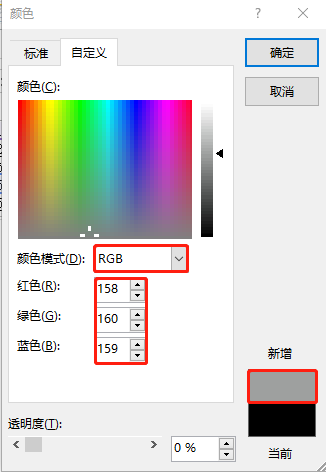
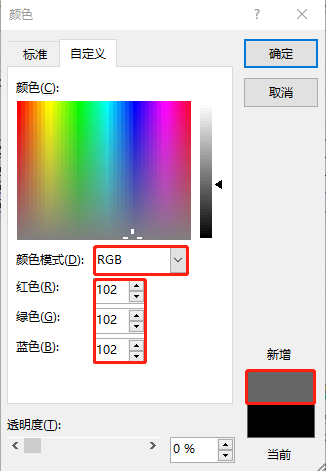
为了让通过microsoft office excel可视化图表的图例颜色完全等同于emcc中的图表图例颜色,强烈建议在上传图例图片(可以截取emcc图表的图例保存成本地图片),使其识别出相应的rgb颜色值(十六进制),然后再使用得到我们想要的rgb颜色值(十进制)。本篇文章中使用到的rgb颜色值是这样的:
-- each legend color from the graph of "average runnable processes" of emcc 13.5.
instance foreground cpu, #35c387 -> rgb (53 , 195, 135)
instance background cpu, #a9f89c -> rgb (169, 248, 156)
non-database host cpu , #9a9595 -> rgb (154, 149, 149)
load average , #7a7a7a -> rgb (122, 122, 122)