

在mysql的innodb引擎设计中,对删除一些数据的操作,只是被标记为“已删除”,而不是真正的从物理文件中删除,因而空间也没有真的被释放回收。虽然mysql中有purge线程会异步清理这些没用的数据,但是依然没有把这些空间释放出来还给操作系统重新使用。因此,数据页中存在很多空洞。当然,有新的数据插入时,会尽可能使用这些空洞的空间,进行覆盖,这样做既节省又能再次利用。
但往往不是那么尽人如意,当mysql数据库负载高,或或算法不足以满足时,会顾不上原空间利用,只会开辟新的空间。这样导致的结果是,实际数据量就只有几万行,但底层数据ibd文件会非常大。跟实际空间不成对比。这就是mysql表碎片化场景。普遍场景下对整体影响不大,但过多的碎片化会导致表扫描所花费的时间比“应该”花费的时间更长,底层io会更高。
- 空间浪费:空间浪费不用多说,碎片占用了大量可用空间。
- 读写性能下降:由于存在大量碎片,数据从连续规则的存储方式变为随机分散的存储方式,磁盘i0会变的繁忙,数据库读写性能就会下降。
- 执行计划不准确导致sql语句性能下降。因为样本sample采取的页里包含空洞,导致cardinality信息不准确,执行计划选择错误。
在mysql使用经验中,容易大量碎片出现的情况如下:
1.频繁大量随机的delete操作会产生会不连续的空白空间,这些空间使用率非常底。
2.大量的update,也会产生文件碎片化,innodb的最小物理存储分配单位是页(page),而update也可能导致页分裂(page split),频繁的页分裂,页会变得稀疏,并且被不规则的填充,所以最终数据会有碎片。
mysql提供系统表和工具可以查看碎片信息。
1)命令行统计信息。
通过show status 命令查看表的情况:
mysql>show table status like 'attendance'\g;
*************************** 1. row ***************************
name: attendance
engine: innodb
version: 10
row_format: dynamic
rows: 8
avg_row_length: 2048
data_length: 253040000
max_data_length: 0
index_length: 62040000
data_free: 102400
auto_increment: null
create_time: 2023-09-18 18:08:38
update_time: null
check_time: null
collation: utf8mb4_bin
checksum: null
create_options:
comment:
1 row in set (0.00 sec)
查询information_schema.tables获取表的碎片化信息:
mysql> select concat(table_schema, '.', table_name) as table_name,
(data_length index_length) / 1024 / 1024 as total_mb,
data_free / 1024 / 1024 as data_free_mb,
data_free * 100/(data_length index_length) as data_free_percent,
curdate() as today
from information_schema.tables
where table_schema not in ('mysql','sys','information_schema','performance_schema')
order by data_free_percent desc limit 5;
-------------------- ------------ -------------- ------------------- ------------
| table_name | total_mb | data_free_mb | data_free_percent | today |
-------------------- ------------ -------------- ------------------- ------------
| book.attendance | 323.031250 | 100.000000 | 33.000 | 2023-12-18 |
| book.customers | 300.031250 | 90.00000000 | 0.3000 | 2023-12-18 |
| book.dataseta | 120.015625 | 4.00000000 | 0.0333 | 2023-12-18 |
| book.employees | 79.0312500 | 1.00000000 | 0.0100 | 2023-12-18 |
| book.jemp | 50.0468750 | 1.00000000 | 0.0100 | 2023-12-18 |
| book.members | 42.0468750 | 1.00000000 | 0.0100 | 2023-12-18 |
| book.opening_lines | 40.0156250 | 1.00000000 | 0.0100 | 2023-12-18 |
-------------------- ------------ -------------- ------------------- ------------
10 rows in set, 10 warnings (0.01 sec)
备注:这有可能存在不准确信息,最好在到数据目录查看文件实际大小。
2)mysql工具innochecksum分析碎片
innocchecksum是官方提供的innodb引擎文件的校验工具。该工具读取innodb表空间文件,计算每个页面的校验和,将计算出的校验和与存储的校验和进行比较。需要保证ibd文件没有文件锁,最好的方式是先关闭mysqld进程。
显示各种页类型的计数:
shell> innochecksum --page-type-summary ./attendance.ibd
file::./attendance.ibd
================page type summary==============
#page_count page_type
===============================================
625 index page #索引页
1 sdi index page #数据字典也
0 undo log page #undo页
1 inode page #索引页
0 insert buffer free list page #插入缓冲空闲列表页
523 freshly allocated page #表示还没有使用的页
1 insert buffer bitmap #插入缓冲位图页
0 system page #系统页
0 transaction system page #事务数据页
1 file space header #文件空间标头
0 extent descriptor page
0 blob page #blob数据页
0 compressed blob page #压缩的blob页
0 subsequent compressed blob page
0 sdi blob page #sdi blob页
0 compressed sdi blob page #压缩的 sdi blob页
0 other type of page #其他页
===============================================
additional information:
undo page type: 0 insert, 0 update, 0 other
undo page state: 0 active, 0 cached, 0 to_free, 0 to_purge, 0 prepared, 0 other
备注:需要关注freshly allocated page:可用页
显示表空间中每个页的分布情况:
shell> innochecksum --page-type-dump=/tmp/a.txt ./attendance.ibd
shell> cat /tmp/a.txt
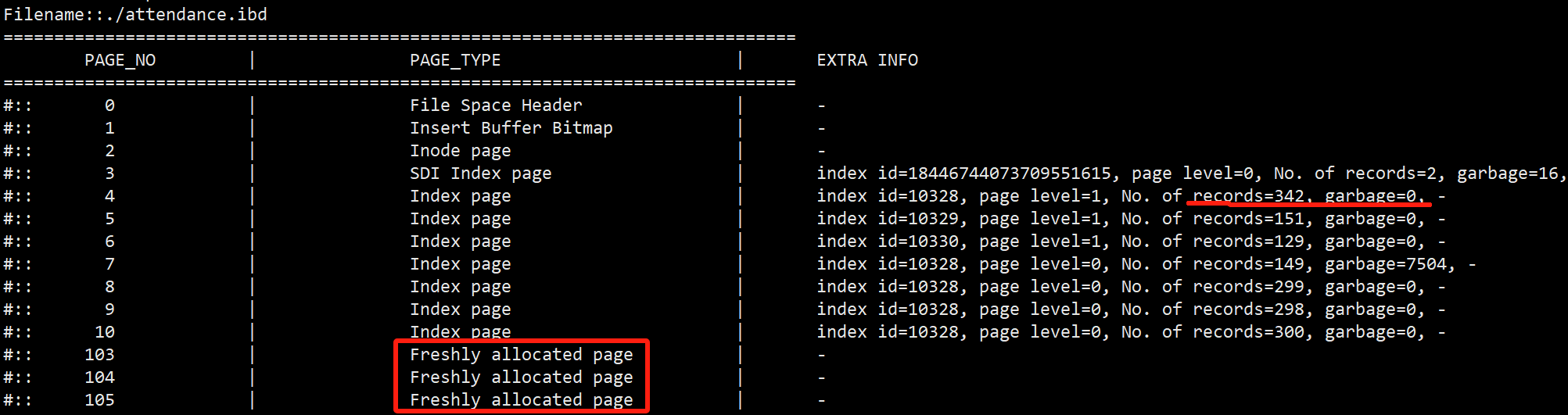
备注:这里的index page都是按照page num的顺序从小到大排列的。records显示每个page的行数。
garbage已经被删除的记录行数。从这里看出是否复用了这个页。
在mysql碎片整理,有如下3种技术方式:
- alter table tbl_name engine=innodb
当指定engine子句时,alter table会重新构建该表。在现有的innodb表上运行alter table tbl_name engine=innodb将执行“null”alter table操作,该操作可用于对innodb表进行碎片整理。 - optimize table回收未使用的空间并对数据文件进行碎片整理。在对表进行大量更改后,此语句还可以提高使用该表的语句的性能,有时甚至可以显著提高性能。
- 另一种方法是逻辑导出导入,删除原表,然后从新加载数据。可以使用mysqldump方式。
alter操作和optimize会锁表,属于高危命令,时间长短依据数据量的大小。
按照上诉技术手段,可以在主从节点上轮回切换,进行碎片整理。注意,避免在业务高峰期进行,以减少对系统性能的影响。
对于mysql碎片情况,官方建议不要经常进行碎片整理,一般根据实际情况,当出现碎片,并导致的性能问题比较严重时,选择合适的时机和合适的方式进行整理。
对于日常碎片化监控,建议先通过系统表统计信息进行监控。当碎片情况比较严重时,使用innochecksum进行二次分析,之后进行碎片整理。