

mgr 对网络要求很高,有的时候会因网络波动,自动退出集群的情况,此时需要先在出问题的节点停止组复制,然后再重新加入到集群中。
如下,该节点被踢出集群,直接执行stop group_replication;报错

需要先执行 stop group_replication 然后再 start group_replication
stop group_replication;
start group_replication;
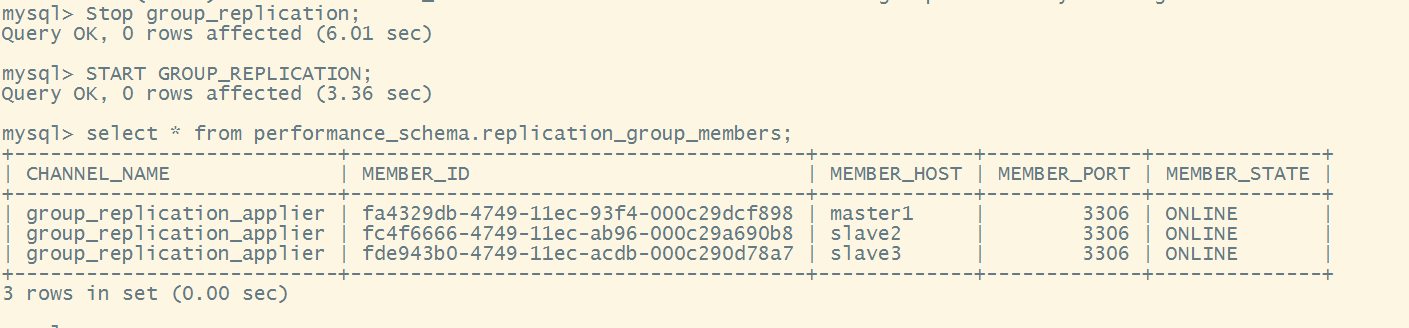

查看日志

在主节点将密码的加密方式修改
set sql_log_bin=0;
alter user repl@'%' identified with mysql_native_password by 'repl';
grant replication slave on *.* to repl@'%';
grant backup_admin on *.* to repl@'%';
flush privileges;
set sql_log_bin=1;
在重启两个从节点
stop group_replication;
start group_replication;
2节点状态恢复正常

3节点状态恢复正常

暂时性恢复
mgr 对数据具有一定的容错性和最终一致性,原则上并不会出现数据不一致的情况,并且每次执行事务都会检测冲突,然后如果当某个节点的数据因为异常导致不一致,切主节点的 binlog 丢失的情况,势必会导致集群数据不一致,此时可以通过以下的方法暂时让集群起来。
停止异常节点的组复制
stop group_replication;
清空当前的 gtid executed
reset master;
在异常节点将 gtid 事务号设置和主节点一致
set @@global.gtid_purged='主节点的 gtid 号';
启动异常节点的组复制
start group_replication; 这里需要注意,这样的方式即使恢复了集群,因为 binlog 的缺失,实际上数据是不一致的,极有可能发生后续因为数据不一致导致集群出现问题,这里强烈不建议这么做。
前面提到了暂时性的集群恢复,这样的恢复会有很大的问题,这里说下 mgr 正常的恢复方式,mgr 当新的成员加入节点时,通常有两种方法,当 binlog 全,或者 binlog 在删除前接入的节点能够成功继续往下同
步的。则新加入的节点会继续同步下去,在 mysql8.0.21 版本中,可以通过设置参数
group_replication_advertise_recovery_endpoints 这个参数来进行指定的点进行同步。
如果当 binlog 不可用或者差的数据实在太多时,mysql 在 8.0.17 后退出了克隆的方式进行恢复,即在集群中的所有 mysql 节点上添加克隆插件,新加入的节点数据将会被全部删除,然后会被自动重新同步数据。
4.1节点分布式恢复
读节点重新加入环境
模拟读节点重新加入,首先观察主节点的数据以及事务的情况
此时将节点 3,然后清除所有数据,清除同步信息,重新初始化 mysql,模拟成新节点
已有数据
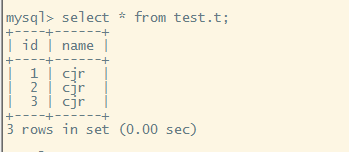
关库

删数据文件

此时3节点已经被集群踢出去了

重新初始化,启动,并登录
初始化
mysqld --defaults-file=/etc/my.cnf --basedir=/usr/local/mysql --initialize-insecure --datadir=/data/3306/data --user=mysql &
启动
mysqld_safe --defaults-file=/etc/my.cnf --user=mysql &
登录
mysql -u root

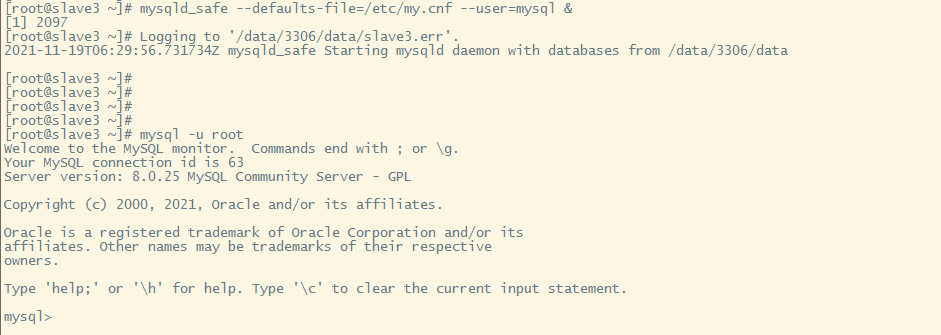
这里注意,因为 2 节点的的 ip 已经添加到了所有节点的 group_replication_group_seeds 中,所以不再添加,如果是新的 ip 加入节点,必须在所有其他节点上 group_replication_group_seeds 中添加新节点的ip。
按照搭建 mgr 节点的步骤,将节点 2 添加到集群中
reset master;
install plugin group_replication soname 'group_replication.so';
change master to master_user='repl', master_password='repl' for channel 'group_replication_recovery';
start group_replication;
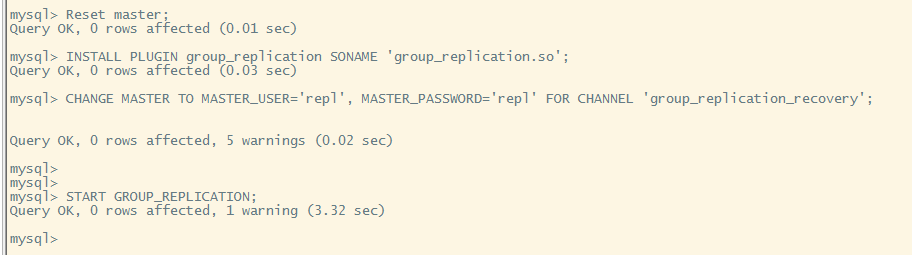
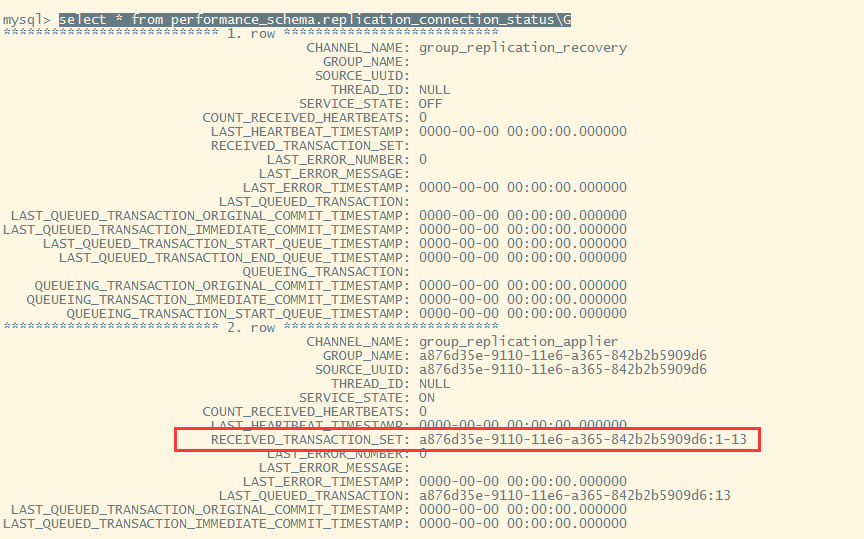
已经重新加入到集群中,数据也同步回来

可以看到同步事务已经一致
4.2克隆恢复
mysql8.0.17 后可以使用克隆恢复
这里我们依然采用节点 3 作为需要接收克隆的节点
首先在源节点和接收克隆的节点添加克隆插件
install plugin clone soname 'mysql_clone.so';
同样因为是组复制,所以节点 3 必须装组复制插件
install plugin group_replication soname 'group_replication.so';

其次在提供克隆的节点上,也就是节点 1 上赋权
create user clone_user@'%' identified by '123456';
grant backup_admin on *.* to 'clone_user'@'%'; 在接收克隆的目标节点,也就是节点 2 上赋权
create user clone_user@'%' identified by '123456';
grant clone_admin on *.* to 'clone_user'@'%'; 在接收克隆的目标节点上设置源端的白名单
set global clone_valid_donor_list = '192.168.168.101:3360';
为了验证克隆是否会清除接收端上的数据,这里我们多建几个 schema在节点3执行
clone instance from clone_user@'192.168.168.101':3360 identified by '123456';
完成之后,把节点3重新加入到集群
change master to master_user='repl', master_password='repl' for channel 'group_replication_recovery';
start group_replication;完成恢复