

前言
作为一名dba,光懂数据库却不懂操作系统也是有弊端的,因为归根结底,数据库是安装在操作系统之上的。笔者最近一次处理故障的过程,充分验证了这个说法。
作为打工人是需要随时响应的,周末也不例外。下午接到用户方的消息,表示业务数据库节点主机的安装目录/u01使用率达到了100%,但是他不知道该怎么清理,于是需要我上线去释放一点空间。
排障步骤
1.查找大文件
由于该数据库的存储是使用asm磁盘的,所以主机分区u01满掉肯定不会是因为数据文件增长,所以一般是数据库的一些日志文件增长导致。笔者对linux的命令知道的不多,使用的是du命令,挨个分区找下去,发现/u01/11.2/grid/crf/db/host/下存在一些后缀为.bdb的文件,占据了大概20g的空间。
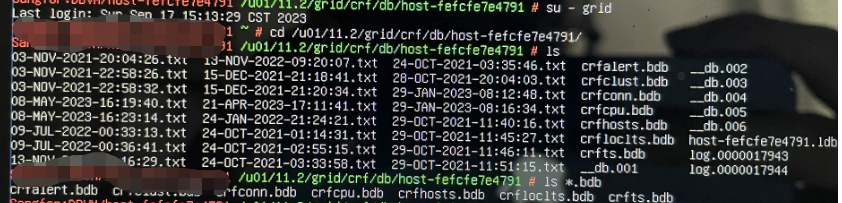
2.搜索引擎
搜索关键字“crfclust.bdb”可以得到一篇标准的处理流程,技术原理略过。即登录到grid用户,查看ora.crf服务的状态,删除文件,启动ora.crf服务,就算处理好了。
crsctl stat res ora.crf -init -t #查看ora.crf
crsctl stop res ora.crf -init #关闭ora.crf
rm -f *.bdb #删除文件
crsctl start res ora.crf -init #启动ora.crf
结果敲第一句就报错,如图所示。想了想,应该是分区满掉,连crsctl命令都敲不出来了,这会笔者有点着急,这没按剧本走啊!

3.暴力解决问题
人一旦开始急了,就会干出点非标准化的动作。笔者的做法是不管三七二十一,直接用root账户把这些后缀为.bdb的文件给干掉,释放空间,结果删完发现,u01空间占用率依旧还是100%.
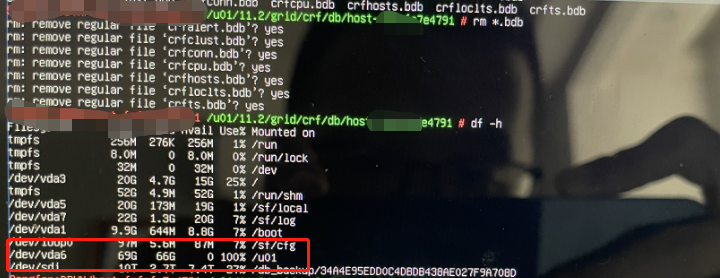
4.搜索引擎
笔者认为操作系统有类似回收站的机制,需要清空回收站,空间才会得到释放,然后继续开始搜索引擎查找,发现判断错误。查询发现是由于ora.crf服务锁定了这部分的文件空间,需要停止该服务后,空间才会释放,但是通过步骤二的输出结果,发现crsctl是无法被执行的,由于分区满掉的原因(kill进程也许会奏效,但是笔者不太敢操作)。
5.删点别的
为了解决分区满掉,导致crsctl命令无法执行的问题。笔者想起了alert,grid日志,于是对类似.log和.xml日志一顿删,再次执行该命令,成功。这边也整理了可以清理的日志文件及目录(部分)
cd /u01/app/grid/diag/tnslsnr/host/listener/alert
rm -f log_*.xml
cd /u01/app/grid/diag/tnslsnr/host/listener/trace
rm -f listener.log
6.释放空间
接下来,按照上述搜索引擎得到的标准步骤执行一遍,u01分区的空间即刻得到了释放,故障消除
总结
由于是业务数据库,再小的故障也需要进行反思回顾。笔者认为,此故障暴露了两个问题。1、运维人员未将主机操作系统的健康进行检查,等到业务异常了才通知相关人员去处理。 2、dba人员即笔者,对linux主机的原理了解过少,导致一个简单的问题却花费了过多的时间去解决。