

perf工具可用来对软件进行优化,包括算法优化(空间复杂度、时间复杂度)和代码优化(提高执行速度、减少内存占用)等等,perf 最常用的参数有top、stat、record,另外还有list和report等。
本文主要使用perf的record,script以及flamegraph工具生成火焰图,来进一步分析性能瓶颈和函数调用。
使用perf record 采集数据,其中-g表示记录调用栈,-p 49383是进程号,即对哪个进程进行分析。采集后可以ctrl c终止。
-e参数来统计需要关注的事件。 多个事件就用多个-e 连接。此处我带了cpu-clock,cpu-clock可以用来表示程序执行经过的真实时间,而无论cpu处于什么状态(pn(n非0)或者是c状态)。
除了cpu-clock事件,比较常用的还有cpu cycle,cpu cycles用来表示执行程序指令花费的时钟周期数,如果cpu处于pn(n非0)或者是c状态,则cycles的产生速度会减慢。
如果想查看哪些代码消耗的真实时间多,则可以使用cpu-clock事件;而如果想查看哪些代码消耗的时钟周期多,则可以使用cpu cycles事件。
除了此类cpu火焰图,也可以带上其他类型的事件进行统计,例如内存火焰图,分析内存的变化情况,可以进一步帮助分析内存被哪些模块占用、内存泄露问题的原因等问题。bio火焰图,统计io的耗时由哪些函数占用,便于分析优化io性能。此处不做赘述。
perf record -e cpu-clock -g -p 49383
除此之外,常见的还可以带上如下选项:
-f 99:表示每秒99次
sleep 30:采集持续30秒,这样就不需要手动ctrl c终止。
-o xxx:指定采集后输出的文件名等。
-t:指定线程tid。
-a:显示在所有cpu上的性能统计信息。
-c:显示在指定cpu上的性能统计信息。
第一步生成的perf.data文件其实也可以用perf report查看,只不过不直观
perf report -n --stdio -i perf.data
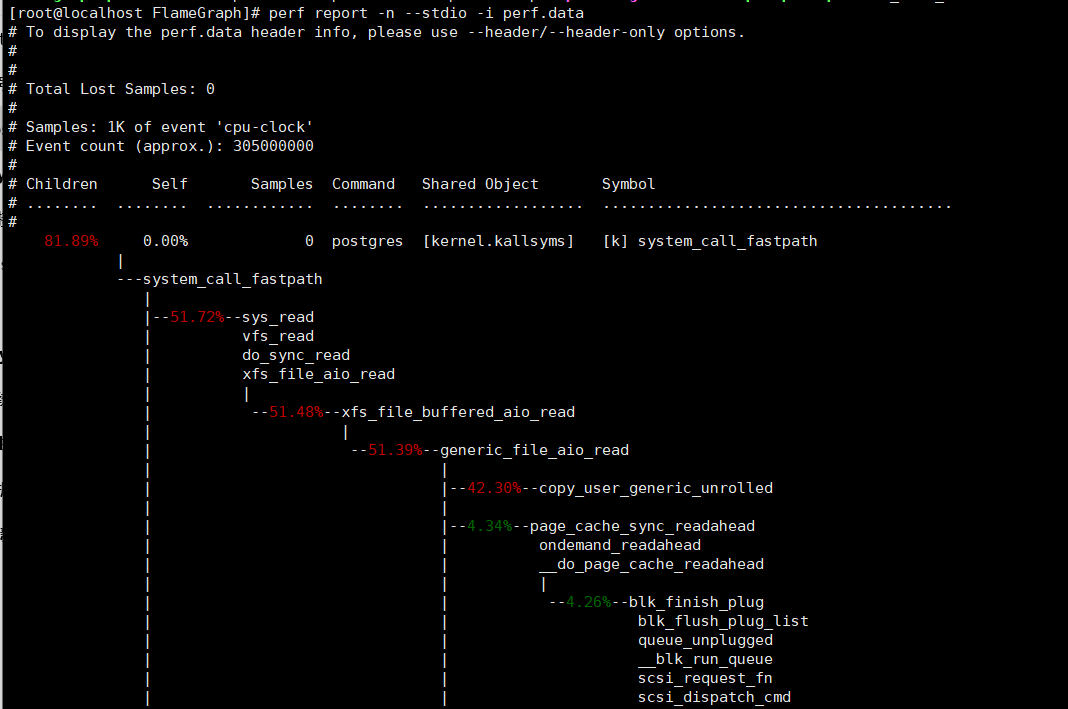
-i跟第一步收集的文件,进行解析
perf script -i perf.data > perf.script

使用flamegraph的stackcollapse-perf.pl折叠调用栈
./stackcollapse-perf.pl perf.script > perf.folded
使用flamegraph的flamegraph.pl生成svg格式的火焰图
./flamegraph.pl perf.folded > perf.svg
生成的火焰图大概是如下这样
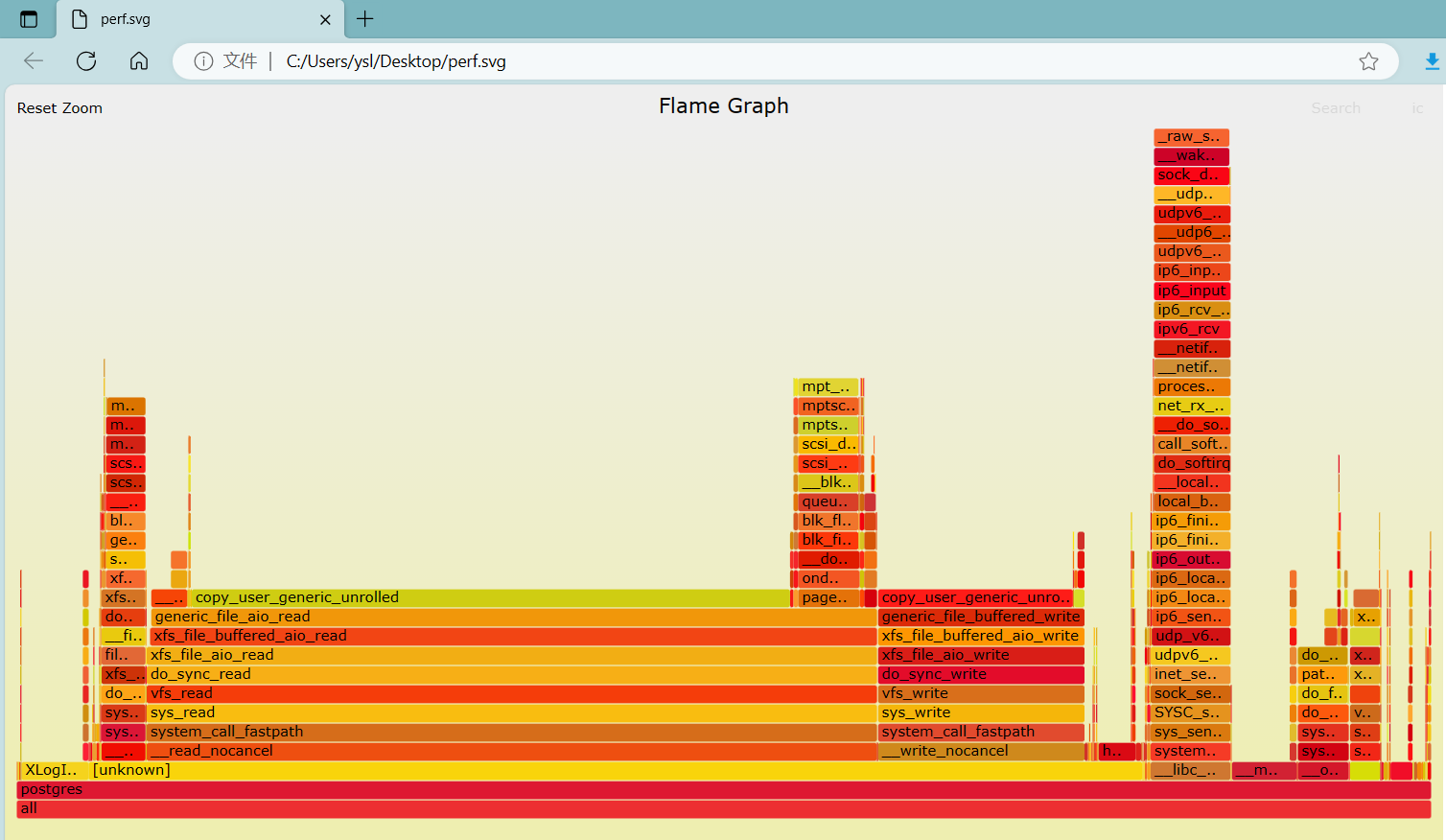
其中每一个方框是一个函数,鼠标悬浮时会显示完整的函数名、抽样抽中的次数、占据总抽样次数的百分比。方框的长度,代表了它的执行时间,所以越宽的函数,就表示它被抽到的次数多,即执行的时间长。调用栈越深,火焰就越高,顶部就是正在执行的函数,下方都是它的父函数。
可以看到all上边的第一个就是postgres。如下的每个方框,即函数都可以点击,点击后,会显示其对应调用的子函数。例如点击xloginsertrecord函数,可以显示出其调用的堆栈
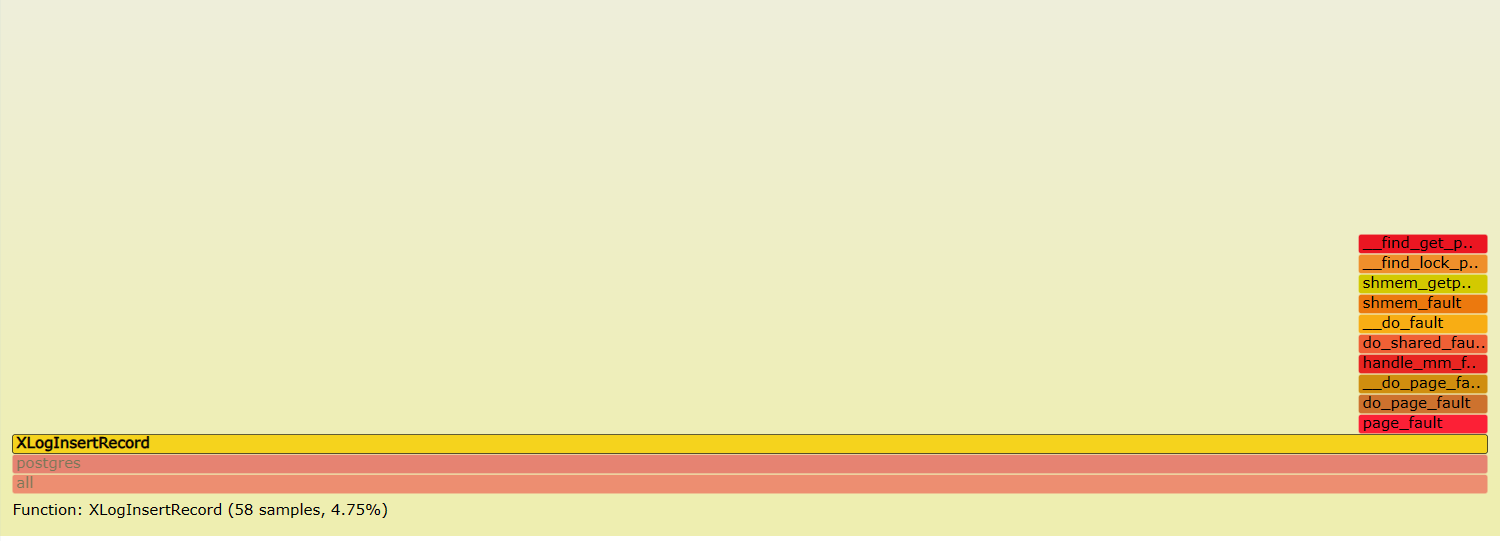
点击hash_search_with_hash_value,显示它调用的堆栈。

火焰图主要看顶层的哪个函数占据的宽度最大。只要有"平顶"(plateaus),就表示该函数可能存在性能问题,可能是瓶颈。可以尝试对此类函数占用时间长的原因分析和优化,从而提高性能。