

本案例中的问题现象发生于当前主流的oracle 11g环境。不排除随着后续数据库版本的升级可能会有一定细微的差异表现。但问题的原因及m6米乐安卓版下载的解决方案,在所有版本中都是通用的。
数据库版本:oracle 11g
应用人员反馈,当前数据库存在一条低效sql。不确定什么原因导致。需要定位问题原因。且应用人员反应之前该sql执行效率没有问题,是这两天才出现的性能问题。
为此。需要排查何种原因导致的当前性能低效,并找出m6米乐安卓版下载的解决方案。
2.1 查看活动会话
应用人员反馈当前sql正在跑,为此查看当前活动会话。

可以看到有一条sql在累计执行,且平均执行时间达到了3w多秒。可以确定是该低效sql。
2.2 分析sql的历史执行情况:

可以看到,sql在20号之前的执行效率是可以的。真正出现问题是从21号开始。执行计划发生了改变,导致了执行效率非常低效。这也符合应用人员反馈的,执行效率近期才开始变差。
2.3 分析执行计划:
sql语句较长,这里优先分析执行计划。只列出部分
原始高效执行计划:


通过t3做驱动表,通过finish_time索引完成过滤。
当前低效执行计划:


当前问题执行计划,通过t_agent_type表做驱动表,并关联后续多张表。从cost成本来看,新产生的执行计划成本远小于之前的。因此优化器选择了新的执行计划。
2.4 实际测试执行效率:
针对出现性能差异的代码段,单独测试执行效率。
当前低效执行情况:

主要耗时发生在t_agent_type表关联的后续一系列多张表,执行效率较低。更近一步分析,根源在于其直接关联的t_t1_change表,其预估行数明明很大,达到了34m,而优化器估算成本时确只有121。关联后的成本也只有125。

这里同样测试如果用finish_time日期索引关联。则成本会远高于当前的。

这样就导致当前使用t_agent_type做驱动表,后续再关联多张表时候选择了嵌套循环关联,多次访问造成执行较慢的问题。
2.5 分析目标表:
这里怀疑执行成本较小的原因与驱动表t_agent_type有关。是否是统计信息差异导致的当前预估成本过小问题?
首先查看统计信息的最大最小值。
--获取列中的最大最小值
set serveroutput on
declare
a_low dba_tab_columns.low_value%type;
a_high dba_tab_columns.high_value%type;
aa xxx.t_agent_type.service_id%type;
begin
select low_value, high_value
into a_low, a_high
from dba_tab_columns
where owner = 'xxx' ----用户名
and table_name in ('t_agent_type') ---表名
and column_name in (upper('service_id'));
dbms_stats.convert_raw_value(a_low, aa);
dbms_output.put_line('min:'||aa);
dbms_stats.convert_raw_value(a_high, aa);
dbms_output.put_line('max:'||aa);
end;
/
set serveroutput off


表中数据量较少,当前表的最大最小值,与表中实际的数据分布完全吻合,不存在记录差异影响关联行数,进而影响查询成本的问题。
查看统计信息:

该表上一次统计信息收集时间是在5月20日,尽管时间偏长,但该表是个小表,没有频繁 数据变动的情况下,也不需要保持统计信息的最新。

根据关联列,这里继续分析关联列service_id的最大最小值。

通过cast_to_varchar2函数来看,该列是字符型列。且转换后正好是对应的最大最小值。
但从列统计信息上看,该列确是number类型。


通过cast_to_number函数转换时不匹配。这里就是很奇怪的地方。为何统计信息记录的类型,和实际存储的最大最小值转换时不匹配呢?
怀疑是否是应用人员修改过该字段的类型。

且查看该表相关对象,发现有相同表名的不同用户,其目标字段正好是varchar2类型的。

通过last_ddl_time及上述对比,上面的假设很有可能。
2.6 创建测试表实验模拟:
为了验证上述猜想是否正确。在经过应用人员同意的情况下,创建了相应测试表。
create table t_agent_type_copy2 as select * from t_agent_type;
truncate table t_agent_type_copy2;
alter table t_agent_type_copy2 modify(service_id varchar2(4));
insert into t_agent_type_copy2 select * from t_agent_type;
--并收集统计信息:
exec dbms_stats.gather_table_stats(ownname=>'xxx',tabname=>'t_agent_type_copy2',cascade=>true,no_invalidate=>false);
1.首先测试varchar2列类型:
select count(*)
from t_t1_change tpc
where
tpc.service_id in (select service_id from t_agent_type_copy2)
and tpc.change_status = '3'
and tpc.service_id not in (451, 437);
模拟相同的表关联情况:

在当前列类型时,关联成本是很高的。可以看到即使是全索引扫描,优化器仍然使用了hash关联。而不会考虑问题执行计划中的嵌套循环。
试图让其走回嵌套循环:

查询成本甚至上升到了80m。也正是如此,放弃嵌套循环使用hash关联是正确的选择。
- 修改类型为number类型:不收集统计信息
truncate table t_agent_type_copy2;
alter table t_agent_type_copy2 modify(service_id number(10,0));
insert into t_agent_type_copy2 select * from t_agent_type;
在插入数据后,保持当前目标表的未收集统计信息状态。再次测试:
select /* 22 */count(*)
from t_t1_change tpc
where
tpc.service_id in (select service_id from t_agent_type_copy2)
and tpc.change_status = '3'
and tpc.service_id not in (451, 437);
执行计划如下:
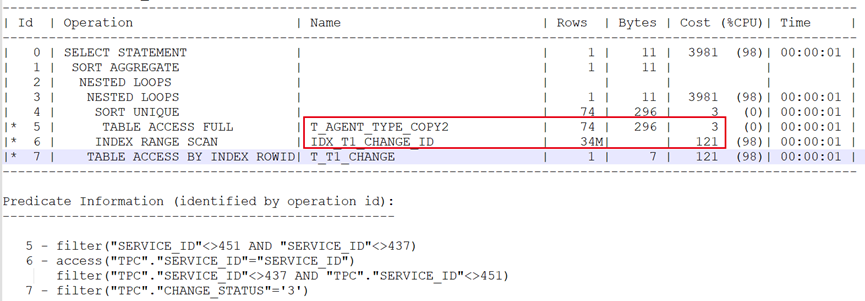
可以看到,此时重现了问题现象。尽管关联后预估返回行数很多,但预估的查询成本确很低。这里就怀疑与修改字段未收集统计信息有关。
3.修改类型后重新收集统计信息:
exec dbms_stats.gather_table_stats(ownname=>'xxx',tabname=>'t_agent_type_copy2',cascade=>true,no_invalidate=>false );
再次测试查询:
select /* 33 */count(*)
from t_t1_change tpc
where
tpc.service_id in (select service_id from t_agent_type_copy2)
and tpc.change_status = '3'
and tpc.service_id not in (451, 437);
对比执行情况:

此时又走回了hash关联。
分析到此,基本确定就是由于修改字段类型但未收集统计信息有关。
对比当前测试表的历史统计信息:

进一步印证了上述实验。首先创建t_agent_type_copy2测试表后,直接修改字段类型为varchar2类型,之后收集统计信息。此时记录的最大最小值均为313036、39323038。也就是最开始看到的目标表的最大最小值情况。(当前列为字符型)

之后修改字段类型为number。但由于未收集统计信息,此时产生了性能问题。对应实验步骤2
最后收集统计信息后,再次观察历史统计信息。

此时的记录变成了c20207、c25d09。也就是统计信息成功的记录为了number类型。

再次对比原始目标表,

与我们实验的测试表现象完全一致。至此问题明确。
通过上述分析,从问题现象推导出是应用人员对目标表做过字段类型修改。之后与应用人员沟通,确定正是在前一天修改过service_id的字段类型。从varchar2修改为number类型。从而造成了看到的性能问题。
因此,又经过上面的实验测试。只需要在事后及时的收集目标表的统计信息。即可让优化器顺利的评估各表关联后的查询成本,从而走回正确的执行计划。
优化建议:
在修改字段类型后及时收集统计信息。
exec dbms_stats.gather_table_stats(ownname=>'xxx',tabname=>'t_agent_type',cascade=>true,no_invalidate=>false);
收集统计信息后,对比sql执行情况:

后续走回了正确的执行计划。
本案例应用人员对表做ddl变更。但未收集统计信息所致。数据库在评估执行计划时,是依赖统计信息的,如果统计信息与实际的差异过大,甚至出现本例中的字段类型与记录的最大最小值类型完全不是一类的时候,很可能造成走错执行计划的问题。因此就需要及时的收集统计信息以保证查询效率。