

近日中午一开发过来说生产有条 sql 执行缓慢,让看一下执行计划。测试环境说也有同样的问题 sql,那么则开始在测试环境搞一搞吧,排查过程大概记录如下,对于 优化也就是一知半解,故此只能抛砖引玉,如有错误还望指正。
开发发过来的分页 sql 如下(敏感信息均已过滤转换),由于篇幅问题,这里不放入 plsql 格式化展开了。
select "v0" "sequence_no", "v1" "pk_deliver_info", "v2" "trans_no", "v3" "agent_id", "v4" "trans_time", "v5" "rst_code", "v6" "rst_mess", "v7" "count", "v8" "quarter", "v9" "query_beg_date", "v10" "query_end_date", "v11" "start_index", "v12" "items_count", "v13" "pull_way", "v14" "create_time", "v15" "update_time", "v16" "delete_time" from (select "x"."v0", "x"."v1", "x"."v2", "x"."v3", "x"."v4", "x"."v5", "x"."v6", "x"."v7", "x"."v8", "x"."v9", "x"."v10", "x"."v11", "x"."v12", "x"."v13", "x"."v14", "x"."v15", "x"."v16", rownum "rn" from (select "t_order_info"."sequence_no" "v0", "t_order_info"."pk_deliver_info" "v1", "t_order_info"."trans_no" "v2", "t_order_info"."agent_id" "v3", "t_order_info"."trans_time" "v4", "t_order_info"."rst_code" "v5", "t_order_info"."rst_mess" "v6", "t_order_info"."count" "v7", "t_order_info"."quarter" "v8", "t_order_info"."query_beg_date" "v9", "t_order_info"."query_end_date" "v10", "t_order_info"."start_index" "v11", "t_order_info"."items_count" "v12", "t_order_info"."pull_way" "v13", "t_order_info"."create_time" "v14", "t_order_info"."update_time" "v15", "t_order_info"."delete_time" "v16" from "t_order_info" where (1 = 1 and "t_order_info"."agent_id" = 'c002374') order by "v10" desc, "v2" desc) "x" where rownum <= (0 1)) where "rn" > 0 order by "rn";
下面来一起看看吧
测试数据库版本及补丁信息
linux 6.10 11204 rac sql*plus: release 11.2.0.4.0
database patch set update : 11.2.0.4.190416
1、查看统计信息收集时间,防止统计信息过旧
sql> set line 345
sql> select table_name,owner,num_rows,last_analyzed from dba_tables where table_name='t_order_info' and owner='prod';
table_name owner num_rows last_analyzed
------------------------------ ------------------------------ ---------- -------------------
t_order_info prod 3625092 2021-10-28 17:36:25
sql> select count(*) from prod.t_order_info;
count(*)
----------
3625092
2、查看创建索引情况
如下只有三个索引
sql> select owner,index_name,table_owner,table_name,tablespace_name,last_analyzed,status from dba_indexes where table_name='t_order_info' and table_owner='prod';
owner index_name table_owner table_name tablespace_name last_analyzed status
------------------------------ ------------------------------ ------------------------------ ------------------------------ ------------------------------ ------------------- --------
prod t_order_info_uk1 prod t_order_info prod_data 2021-10-28 17:36:25 valid
prod t_order_info_index1 prod t_order_info prod_data 2021-10-28 17:36:25 valid
prod t_order_info_pk prod t_order_info prod_data 2021-10-28 17:36:25 valid
3、查看索引所在的列
序列为主键索引,pk_deliver_info 列为唯一索引,普通索引刚好在 agent_id 我们最开始的 where 子句中。
set line 234
col index_owner for a30
col table_owner for a15
col table_name for a25
col index_name for a28
col column_name for a20
select index_owner,table_owner,table_name,index_name,column_name from dba_ind_columns where table_name='&tablename' order by index_name;
sql> select index_owner,table_owner,table_name,index_name,column_name from dba_ind_columns where table_name='t_order_info' and table_owner='prod';
index_owner table_owner table_name index_name column_name
------------------------------ --------------- --------------- ------------------ --------------------
prod prod t_order_deliver t_order_deliver_in sequence_no
_info fo_pk
prod prod t_order_deliver t_order_deliver_in agent_id
_info fo_index1
prod prod t_order_deliver t_order_deliver_in pk_deliver_info
_info fo_uk1
4、查看表是否分区(如下未分区)
sql> select table_name,partitioned from dba_tables where table_name='t_order_info' and owner='prod';
table_name par
------------------------------ ---
t_order_info no
5、查看表的大小
sql> select sum(bytes)/1024/1024 mb from dba_segments where owner='prod' and segment_name ='t_order_info';
mb
----------
768
360多万,768m也算不上大表,对于合理的分页查询应该也没有什么问题,下面就需要看看执行计划了。
sql> select table_name,owner,num_rows,last_analyzed from dba_tables where table_name='t_order_info' and owner='prod';
table_name owner num_rows last_analyzed
--------------- ------------------------------ ---------- -------------------
t_order_info prod 3625092 2021-11-05 16:32:11
6、首先需要拿到原 sql 的 sql_id.
可以通过 awr、ash或者 v$sql 等视图获取,这里通过最简单的 v$sql 视图获取。
set long 9999 line 999 pages 999
select sql_id,sql_fulltext from v$sql where sql_text like '%t_order_info%';
5b2zcwhm267q8
sql> @?/rdbms/admin/sqltrpt.sql
oracle 10g 以后提供了一个脚本 sqltrpt.sql 用来查询最耗费资源的 sql 语句,也可以根据输入的sql_id,生成对应执行计划和调优建议,是一个不错的调优优化脚本。其实是sqltrpt是sql tune report的缩写。这个脚本位于$oracle_home/rdbms/admin/sqltrpt.sql
7、查看执行计划
知道 sql_id 后便可以根据多种办法查看执行计划。关于执行计划多种查看方法,可查看之前的 。
@?/rdbms/admin/awrsqrpt.sql
select * from table(dbms_xplan.display_awr('5b2zcwhm267q8'));
通过 autotrace 和 plsql 使用 f5 查看的执行计划一样。
sql> set autot trace
sp2-0618: cannot find the session identifier. check plustrace role is enabled
sp2-0611: error enabling statistics report
以上普通用户无法使用 autotrace ,需要执行脚本 plustrce.sql 创建 plustrace 角色授予普通用户即可。
cd $oracle_home/sqlplus/admin
ll plustrce.sql
sql> @$oracle_home/sqlplus/admin/plustrce.sql
sql>
sql> drop role plustrace;
drop role plustrace
*
error at line 1:
ora-01919: role 'plustrace' does not exist
sql> create role plustrace;
role created.
sql>
sql> grant select on v_$sesstat to plustrace;
grant succeeded.
sql> grant select on v_$statname to plustrace;
grant succeeded.
sql> grant select on v_$mystat to plustrace;
grant succeeded.
sql> grant plustrace to dba with admin option;
grant succeeded.
sql>
sql> set echo off
sql> grant plustrace to prod;
grant succeeded.
sql> set autot on
sql> conn prod/lkkbtd7$
connected.
sql> set autot on
sql>
sql> set autot trace
execution plan
----------------------------------------------------------
plan hash value: 3374223308
------------------------------------------------------------------------------------------------------------------------
| id | operation | name | rows | bytes |tempspc| cost (%cpu)| time |
------------------------------------------------------------------------------------------------------------------------
| 0 | select statement | | 10 | 8160 | | 4031 (1)| 00:00:49 |
| 1 | sort order by | | 10 | 8160 | | 4031 (1)| 00:00:49 |
|* 2 | view | | 10 | 8160 | | 4030 (1)| 00:00:49 |
|* 3 | count stopkey | | | | | | |
| 4 | view | | 46319 | 35m| | 4030 (1)| 00:00:49 |
|* 5 | sort order by stopkey | | 46319 | 8594k| 10m| 4030 (1)| 00:00:49 |
| 6 | table access by index rowid| t_order_info | 46319 | 8594k| | 2111 (1)| 00:00:26 |
|* 7 | index range scan | t_order_info_index1 | 46319 | | | 469 (0)| 00:00:06 |
------------------------------------------------------------------------------------------------------------------------
predicate information (identified by operation id):
---------------------------------------------------
2 - filter("rn">0)
3 - filter(rownum<=10)
5 - filter(rownum<=10)
7 - access("t_order_info"."agent_id"='c002282')
sql> set line 456 pages 456
sql> select * from table(dbms_xplan.display_cursor('5b2zcwhm267q8'));
------------------------------------------------------------------------------------------------------------------------
| id | operation | name | rows | bytes |tempspc| cost (%cpu)| time |
------------------------------------------------------------------------------------------------------------------------
| 0 | select statement | | | | | 1943 (100)| |
| 1 | sort order by | | 10 | 8160 | | 1943 (1)| 00:00:24 |
|* 2 | view | | 10 | 8160 | | 1942 (1)| 00:00:24 |
|* 3 | count stopkey | | | | | | |
| 4 | view | | 23300 | 17m| | 1942 (1)| 00:00:24 |
|* 5 | sort order by stopkey | | 23300 | 4323k| 5336k| 1942 (1)| 00:00:24 |
| 6 | table access by index rowid| t_order_info | 23300 | 4323k| | 976 (1)| 00:00:12 |
|* 7 | index range scan | t_order_info_index1 | 23300 | | | 220 (0)| 00:00:03 |
------------------------------------------------------------------------------------------------------------------------
执行计划中有排序,而且成本 cost 也很高,autotrace 出来的达 4031。
8、优化此 sql
agent_id 建有索引,该 sql 也是走了此索引,但是效果不佳,那么我们尝试创建一个联合索引来看看。
create index prod.t_ord_info_idquery_transno on prod.t_order_info(agent_id,query_end_date desc,trans_no desc) tablespace prod_index online;
注意如果建立如下索引,执行计划则会出现 index range scan descending,物理读变为 3,其他基本一样,但是使用 11 节的分页 sql 时执行计划中排序则不可避免,没有充分利用索引有序的特性,故需删除按照上面语法重新创建较好一丢丢。
create index prod.t_ord_info_idquery_transno on prod.t_order_info(agent_id,query_end_date,trans_no) tablespace prod_index online;
drop index prod.t_ord_info_idquery_transno;
9、收集表统计信息
exec dbms_stats.gather_table_stats(ownname => 'prod', tabname => 't_order_info');
alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss';
select table_name,owner,num_rows,last_analyzed from dba_tables where table_name like 't_order_info' and owner='prod';
10、查看执行计划
conn xxxx/xxxx
set autot on
execution plan
----------------------------------------------------------
plan hash value: 3879506888
--------------------------------------------------------------------------------------------------------------
| id | operation | name | rows | bytes | cost (%cpu)| time |
--------------------------------------------------------------------------------------------------------------
| 0 | select statement | | 10 | 8160 | 9 (12)| 00:00:01 |
| 1 | sort order by | | 10 | 8160 | 9 (12)| 00:00:01 |
|* 2 | view | | 10 | 8160 | 8 (0)| 00:00:01 |
|* 3 | count stopkey | | | | | |
| 4 | view | | 11 | 8833 | 8 (0)| 00:00:01 |
| 5 | table access by index rowid| t_order_info | 37872 | 7064k| 8 (0)| 00:00:01 |
|* 6 | index range scan | t_ord_info_idquery_transno | 11 | | 4 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------------------------
statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
8 consistent gets
2 physical reads
0 redo size
2765 bytes sent via sql*net to client
520 bytes received via sql*net from client
2 sql*net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
10 rows processed
原有执行计划中有 sort order by 的排序操作也已经消除了,cost 成本值降低至 9,与原来的 4031 相比,提高了 440 多倍。那么该 sql 还有优化的空间吗?
11、根据《sql优化核心思想》8.3 一节分页优化思想改写的 sql 如下:
select * from (select *
from (select a.*,rownum rn from (分页sql) a) where rownum<=10)
where rn >=1;
不知道是不是作者笔误,多写了一层 select 还是怎么的,根据此分页框架改写如下 sql 还是达不到最优,请继续往下看。
select * from (select *
from (select a.*,rownum rn from
(select "t_order_info"."sequence_no" "v0",
"t_order_info"."pk_deliver_info" "v1",
"t_order_info"."trans_no" "v2",
"t_order_info"."agent_id" "v3",
"t_order_info"."trans_time" "v4",
"t_order_info"."rst_code" "v5",
"t_order_info"."rst_mess" "v6",
"t_order_info"."count" "v7",
"t_order_info"."quarter" "v8",
"t_order_info"."query_beg_date" "v9",
"t_order_info"."query_end_date" "v10",
"t_order_info"."start_index" "v11",
"t_order_info"."items_count" "v12",
"t_order_info"."pull_way" "v13",
"t_order_info"."create_time" "v14",
"t_order_info"."update_time" "v15",
"t_order_info"."delete_time" "v16"
from "t_order_info"
where ("t_order_info"."agent_id" = 'c002282')
order by "v10" desc, "v2" desc
)
a) where rownum<=10
)
where rn >=1;
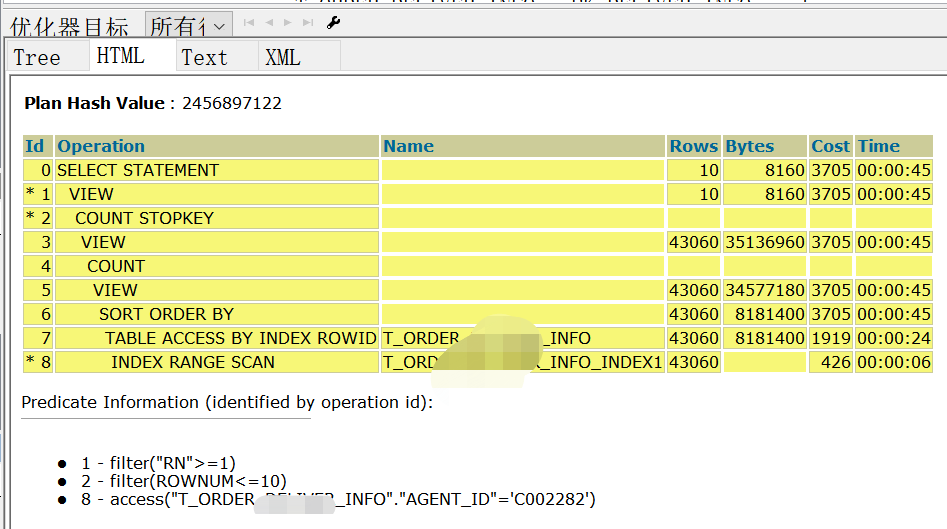
执行计划如下:
plan hash value: 2456897122
-------------------------------------------------------------------------------------------------------------------------
| id | operation | name | rows | bytes |tempspc| cost (%cpu)| time |
-------------------------------------------------------------------------------------------------------------------------
| 0 | select statement | | 10 | 8160 | | 3162 (1)| 00:00:38 |
|* 1 | view | | 10 | 8160 | | 3162 (1)| 00:00:38 |
|* 2 | count stopkey | | | | | | |
| 3 | view | | 37872 | 29m| | 3162 (1)| 00:00:38 |
| 4 | count | | | | | | |
| 5 | view | | 37872 | 29m| | 3162 (1)| 00:00:38 |
| 6 | sort order by | | 37872 | 7064k| 8672k| 3162 (1)| 00:00:38 |
| 7 | table access by index rowid| t_order_info | 37872 | 7064k| | 1579 (1)| 00:00:19 |
|* 8 | index range scan | t_order_info_index1 | 37872 | | | 348 (0)| 00:00:05 |
-------------------------------------------------------------------------------------------------------------------------
statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
1173 consistent gets
0 physical reads
0 redo size
2729 bytes sent via sql*net to client
520 bytes received via sql*net from client
2 sql*net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
10 rows processed
使用原有索引 t_order_info_index1,并没有用到新的联合索引,原有执行计划中有 sort order by 的排序操作也没有消除了,cost 成本值有原来的 4031 降低至 3162,效果不是很明显.
使用 statistics_level 看一眼真实执行计划也是一样使用旧索引,还有排序操作。
grant select any dictionary to prod;
conn prod/prod1245
alter session set statistics_level=all;
执行上述分页 sql
select * from table(dbms_xplan.display_cursor(null,null,‘allstats last’));

那么,我们强制使用 hint 走联合索引在看看,结果 cost 值达 13303,还是没有达到最优。
select /* index(t_order_info t_ord_info_idquery_transno) */ "t_order_info"
execution plan
----------------------------------------------------------
plan hash value: 4173602263
---------------------------------------------------------------------------------------------------------------
| id | operation | name | rows | bytes | cost (%cpu)| time |
---------------------------------------------------------------------------------------------------------------
| 0 | select statement | | 10 | 8160 | 13303 (1)| 00:02:40 |
|* 1 | view | | 10 | 8160 | 13303 (1)| 00:02:40 |
|* 2 | count stopkey | | | | | |
| 3 | view | | 41284 | 32m| 13303 (1)| 00:02:40 |
| 4 | count | | | | | |
| 5 | view | | 41284 | 31m| 13303 (1)| 00:02:40 |
| 6 | table access by index rowid| t_order_info | 41284 | 7700k| 13303 (1)| 00:02:40 |
|* 7 | index range scan | t_ord_info_idquery_transno | 41284 | | 469 (0)| 00:00:06 |
---------------------------------------------------------------------------------------------------------------
predicate information (identified by operation id):
---------------------------------------------------
1 - filter("rn">=1)
2 - filter(rownum<=10)
7 - access("t_order_info"."agent_id"='c002282')
statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
10 consistent gets
2 physical reads
0 redo size
2729 bytes sent via sql*net to client
520 bytes received via sql*net from client
2 sql*net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
10 rows processed
12、最高效的单表分页查询写法
看过老虎刘老师的最高效分页查询语句架构只有三层,我们来套用看看。
select column_lists from
(select rownum as rn,a.* from
(select column_lists from table_name where col_1=:b0 order by col_2) a
where rownum<=:b2
) where rn>:b1;
改写完 sql 格式化如下:
select "v0",
"v1",
"v2",
"v3",
"v4",
"v5",
"v6",
"v7",
"v8",
"v9",
"v10",
"v11",
"v12",
"v13",
"v14",
"v15",
"v16"
from (select rownum as rn, a.*
from (select "t_order_info"."sequence_no" "v0",
"t_order_info"."pk_deliver_info" "v1",
"t_order_info"."trans_no" "v2",
"t_order_info"."agent_id" "v3",
"t_order_info"."trans_time" "v4",
"t_order_info"."rst_code" "v5",
"t_order_info"."rst_mess" "v6",
"t_order_info"."count" "v7",
"t_order_info"."quarter" "v8",
"t_order_info"."query_beg_date" "v9",
"t_order_info"."query_end_date" "v10",
"t_order_info"."start_index" "v11",
"t_order_info"."items_count" "v12",
"t_order_info"."pull_way" "v13",
"t_order_info"."create_time" "v14",
"t_order_info"."update_time" "v15",
"t_order_info"."delete_time" "v16"
from "t_order_info"
where "t_order_info"."agent_id" = 'c002282'
order by "v10" desc, "v2" desc) a
where rownum <= 10)
where rn > 0;
我们来看一看执行计划
execution plan
----------------------------------------------------------
plan hash value: 2845846103
-------------------------------------------------------------------------------------------------------------
| id | operation | name | rows | bytes | cost (%cpu)| time |
-------------------------------------------------------------------------------------------------------------
| 0 | select statement | | 10 | 8160 | 8 (0)| 00:00:01 |
|* 1 | view | | 10 | 8160 | 8 (0)| 00:00:01 |
|* 2 | count stopkey | | | | | |
| 3 | view | | 11 | 8833 | 8 (0)| 00:00:01 |
| 4 | table access by index rowid| t_order_info | 37872 | 7064k| 8 (0)| 00:00:01 |
|* 5 | index range scan | t_ord_info_idquery_transno | 11 | | 4 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------------------
statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
10 consistent gets
0 physical reads
0 redo size
2635 bytes sent via sql*net to client
520 bytes received via sql*net from client
2 sql*net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
10 rows processed
plan hash value: 2845846103
-----------------------------------------------------------------------------------------------------------------------
| id | operation | name | starts | e-rows | a-rows | a-time | buffers |
-----------------------------------------------------------------------------------------------------------------------
| 0 | select statement | | 1 | | 10 |00:00:00.01 | 10 |
|* 1 | view | | 1 | 10 | 10 |00:00:00.01 | 10 |
|* 2 | count stopkey | | 1 | | 10 |00:00:00.01 | 10 |
| 3 | view | | 1 | 10 | 10 |00:00:00.01 | 10 |
| 4 | table access by index rowid| t_order_info | 1 | 41284 | 10 |00:00:00.01 | 10 |
|* 5 | index range scan | t_ord_info_idquery_transno | 1 | 10 | 10 |00:00:00.01 | 5 |
-----------------------------------------------------------------------------------------------------------------------
执行计划中没有排序,没有物理读,cost 只有 8,查询结果秒出,这才是最优的结果。 最后来一起看看落落大神总结的分页优化思路:
单表分页语句优化思路:如果分页语句中有排序(order by),要利用索引已经排序特性,将order by的列按照排序的先后顺序包含在索引中,同时要注意排序是升序还是降序。如果分页语句中有过滤条件,我们要注意过滤条件是否有等值过滤条件,如果有等值过滤条件,要将等值过滤条件优先组合在一起,然后将排序列放在等值过滤条件后面,最后将非等值过滤列放排序列后面。如果分页语句中没有等值过滤条件,我们应该先将排序列放在索引前面,将非等值过滤列放后面,最后利用rownum的count stopkey特性来优化分页sql。如果分页中没有过滤条件,可以将排序列和常量组合(object_name,0)创建索引。如果分页中没有排序,可以直接利用rownum的count stopkey特性来优化分页sql。
如果我们想一眼看出分页语句执行计划是正确还是错误的,先看分页语句有没有order by,再看执行计划有没有sort order by,如果执行计划中有sortorder by,执行计划一般都是错误的分页语句中也不能有distinct、group by、max、min、avg、union、union all等关键字。因为当分页语句中有这些关键字,我们需要等表关联完或者数据都跑完之后再来分页,这样性能很差。
多表关联分页优化思路:多表关联分页语句,如果有排序,只能对其中一个表进行排序,让参与排序的表作为嵌套循环的驱动表,并且要控制驱动表返回的数据顺序与排序的顺序一致,其余表的连接列要创建好索引。
如果有外连接,我们只能选择主表的列作为排序列,语句中不能有distinct、group by、max、min、avg、union、union all,执行计划中不能出现sort order by。
——————————————————————–—–————
公众号:jiekexu dba之路
墨天轮:https://www.modb.pro/u/4347
csdn :https://blog.csdn.net/jiekexu
腾讯云:https://cloud.tencent.com/developer/user/5645107
————————————————————————----———
